来源: MySQL技术内幕:SQL编程
-
作者: 姜承尧
一、前言
因为我想让更多的开发人员和DBA意识到SQL也是一门语言,与我们平时接触的C语言等编程语言并没有什么不同。正因如此,我们也要追求SQL的编程之美。
然而与其他语言不同的是,SQL语言不仅是面向过程的语言,更多的时候,通过SQL语言提供的面向集合的思想可以解决数据库中遇到的很多问题。当然,SQL语言本身也提供了面向过程的方法,但是如果使用不当,会在数据库性能方面遭遇梦魇。SQL编程需要掌握的知识远比想象中多,只有掌握各种知识,综合运用面向过程和面向集合的思想,才能真正解决所遇到的问题。不要迷信网上的任何“神话”,不要被自己或他人的经验所左右。我一直坚信,只有理解了数据库内部运行的原理,才能承自然之道,“乘天地之正,而御六气之辩”,做到真正的“无招胜有招”。
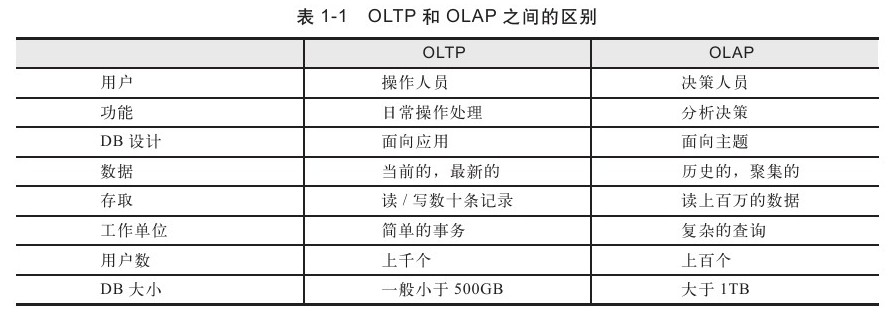
二、数据库的应用类型
对于SQL开发人员来说,必须先要了解进行SQL编程的对象类型,即要开发的数据库应用是哪种类型。一般来说,可将数据库的应用类型分为OLTP(OnLine Transaction Processing,联机事务处理)和OLAP(OnLine Analysis Processing,联机分析处理)两种。OLTP是传统关系型数据库的主要应用,其主要面向基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP即联机事务处理,就是我们经常说的关系数据库,意即记录即时的增、删、改、查,就是我们经常应用的东西,这是数据库的基础;
OLAP即联机分析处理,是数据仓库的核心部心,所谓数据仓库是对于大量已经由OLTP形成的数据的一种分析型的数据库,用于处理商业智能、决策支持等重要的决策信息;数据仓库是在数据库应用到一定程序之后而对历史数据的加工与分析;是处理两种不同用途的工具而已。
二、Mysql的一个比较重要的控制变量
MySQL的sql_mode合理设置
sql_mode是个很容易被忽视的变量,默认值是空值,在这种设置下是可以允许一些非法操作的,比如允许一些非法数据的插入。在生产环境必须将这个值设置为严格模式,所以开发、测试环境的数据库也必须要设置,这样在开发测试阶段就可以发现问题
sql_mode常用值如下:
ONLY_FULL_GROUP_BY:
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中
NO_AUTO_VALUE_ON_ZERO:
该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户 希望插入的值为0,而该列又是自增长的,那么这个选项就有用了。
STRICT_TRANS_TABLES:
在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做限制
NO_ZERO_IN_DATE:
在严格模式下,不允许日期和月份为零
NO_ZERO_DATE:
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告。
ERROR_FOR_DIVISION_BY_ZERO:
在INSERT或UPDATE过程中,如果数据被零除,则产生错误而非警告。如 果未给出该模式,那么数据被零除时MySQL返回NULL
NO_AUTO_CREATE_USER:
禁止GRANT创建密码为空的用户
NO_ENGINE_SUBSTITUTION:
如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常
PIPES_AS_CONCAT:
将"||"视为字符串的连接操作符而非或运算符,这和Oracle数据库是一样的,也和字符串的拼接函数Concat相类似
ANSI_QUOTES:
启用ANSI_QUOTES后,不能用双引号来引用字符串,因为它被解释为识别符
ORACLE的sql_mode设置等同:PIPES_AS_CONCAT, ANSI_QUOTES, IGNORE_SPACE, NO_KEY_OPTIONS, NO_TABLE_OPTIONS, NO_FIELD_OPTIONS, NO_AUTO_CREATE_USER.
如果使用mysql,为了继续保留大家使用oracle的习惯,可以对mysql的sql_mode设置如下:
在my.cnf添加如下配置
[mysqld]
sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,
ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,PIPES_AS_CONCAT,ANSI_QUOTES'
参考:http://dev.mysql.com/doc/refman/5.5/en/server-sql-mode.html
三、查询
查询操作是关系数据库中使用最为频繁的操作,也是构成其他SQL语句(如DELETE、UPDATE)的基础。当要删除或更新某些记录时,首先要查询出这些记录,然后再对其进行相应的SQL操作。因此基于SELECT的查询操作就显得非常重要。对于查询处理,可将其分为逻辑查询处理及物理查询处理。逻辑查询处理表示执行查询应该产生什么样的结果,而物理查询代表MySQL数据库是如何得到该结果的。两种查询的方法可能完全不同,但是得到的结果必定是相同的。
3.1 逻辑查询处理
SQL语言不同于其他编程语言(如C、C++、Java、Python),最明显的不同体现在处理代码的顺序上。在大多数编程语言中,代码按编码顺序被处理。但在SQL语言中,第一个被处理的子句总是FROM子句。图3-1显示了逻辑查询处理的顺序以及步骤的序号。

可以看到一共有11个步骤,最先执行的是FROM操作,最后执行的是LIMIT操作。每个操作都会产生一张虚拟表,该虚拟表作为一个处理的输入。这些虚拟表对用户是透明的,只有最后一步生成的虚拟表才会返回给用户。如果没有在查询中指定某一子句,则将跳过相应的步骤。
接着我们来具体分析查询处理的各个阶段:
1)FROM:对FROM子句中的左表<left_table>和右表<right_table>执行笛卡儿积(Cartesian product),产生虚拟表VT1。
2)ON:对虚拟表VT1应用ON筛选,只有那些符合<join_condition>的行才被插入虚拟表VT2中。
3)JOIN:如果指定了OUTER JOIN(如LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3。如果FROM子句包含两个以上表,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1)~步骤3),直到处理完所有的表为止。
4)WHERE:对虚拟表VT3应用WHERE过滤条件,只有符合<where_condition>的记录才被插入虚拟表VT4中。
5)GROUP BY:根据GROUP BY子句中的列,对VT4中的记录进行分组操作,产生VT5。
6)CUBE|ROLLUP:对表VT5进行CUBE或ROLLUP操作,产生表VT6。
7)HAVING:对虚拟表VT6应用HAVING过滤器,只有符合<having_condition>的记录才被插入虚拟表VT7中。
8)SELECT:第二次执行SELECT操作,选择指定的列,插入到虚拟表VT8中。
9)DISTINCT:去除重复数据,产生虚拟表VT9。
10)ORDER BY:将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10。
11)LIMIT:取出指定行的记录,产生虚拟表VT11,并返回给查询用户。
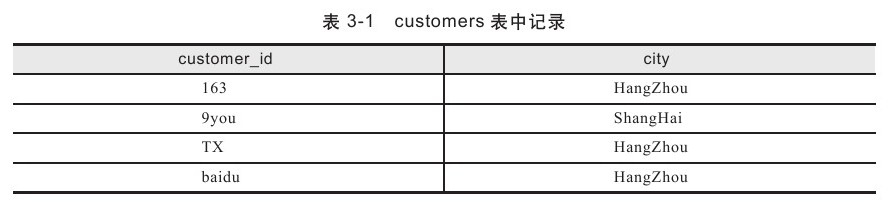
下面通过一个查询示例来详细描述逻辑处理的11个阶段。首先根据下面的代码,创建一个典型的TPC-C应用用户数据表customers和orders,并填充一定量的数据。


表customers和表orders的内容如表3-1和表3-2所示。

通过如下语句来查询来自杭州且订单数少于2的客户,并且查询出他们的订单数量,查询结果按订单数从小到大排序,最后得到的结果如表3-3所示。


3.1.1 执行笛卡儿积
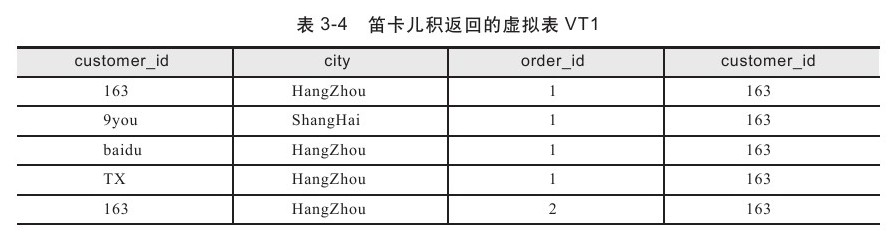
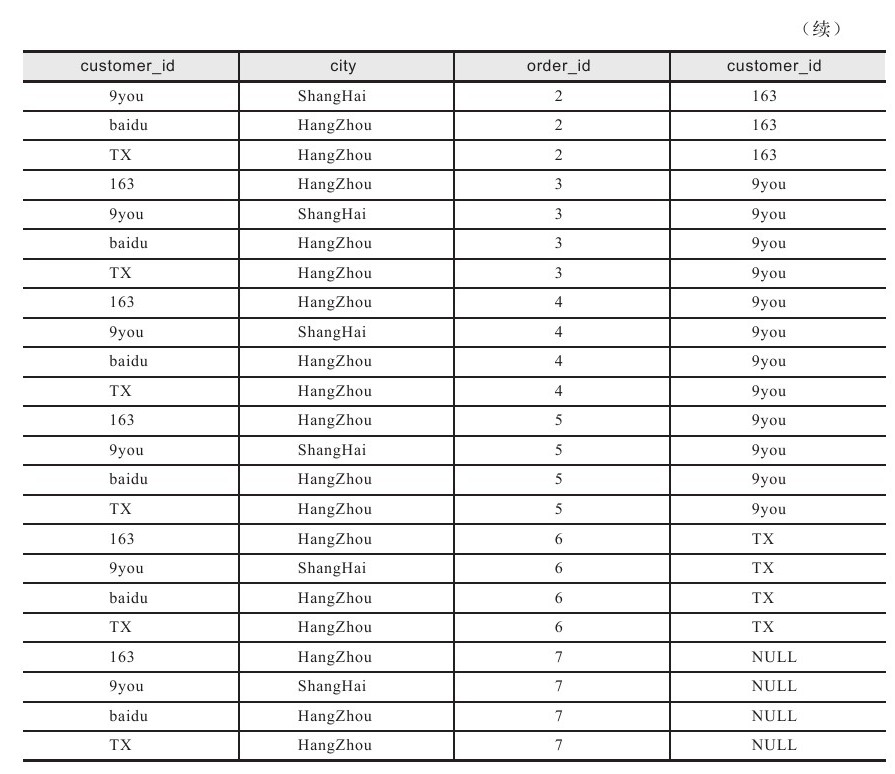
第一步需要做的是对FROM子句前后的两张表进行笛卡儿积操作,也称做交叉连接(Cross Join),生成虚拟表VT1。如果FROM子句前的表中包含a行数据,FR
OM子句后的表中包含b行数据,那么虚拟表VT1中将包含a*b行数据。虚拟表VT1的列由源表定义。对于前面的SQL查询语句,会先执行表orders和customers的笛卡儿积操作。
FROM customers as c……JOIN orders as o
表3-4显示了笛卡儿积产生的虚拟表VT1。
3.1.2 应用ON过滤器
SELECT查询一共有3个过滤过程,分别是ON、WHERE、HAVING。ON是最先执行的过滤过程。根据上一小节产生的虚拟表VT1,过滤条件为:

对于大多数的编程语言而言,逻辑表达式的值只有两种:TRUE和FALSE。但是在关系数据库中起逻辑表达式作用的并非只有两种,还有一种称为三值逻辑的表达式。这是因为在数据库中对NULL值的比较与大多数编程语言不同。在C语言中,NULL==NULL的比较返回的是1,即相等,而在关系数据库中,NULL的比较则完全不是这么回事,例如:


第一个NULL值的比较返回的是NULL而不是0,第二个NULL值的比较返回的仍然是NULL,而不是1。对于比较返回值为NULL的情况,用户应该将其视为UNKNOWN,即表示未知的。因为在某些情况下,NULL返回值可能代表1,即NULL等于NULL,而有时NULL返回值可能代表0。
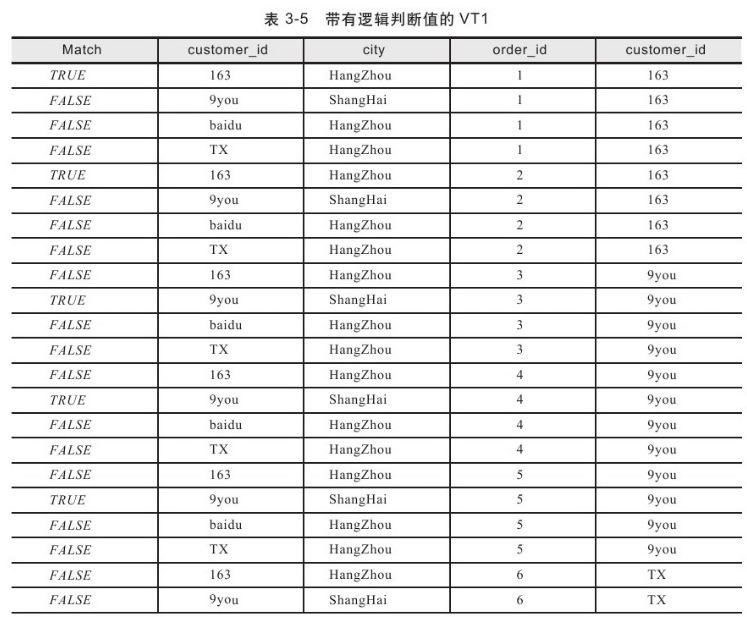
对于在ON过滤条件下的NULL值比较,此时的比较结果为UNKNOWN,却被视为FALSE来进行处理,即两个NULL并不相同。但是在下面两种情况下认为两个NULL值的比较是相等的:
GROUP BY子句把所有NULL值分到同一组。
ORDER BY子句中把所有NULL值排列在一起。
下面来看一个例子,创建表t的语句如下所示:

接着对表t中的列a进行ORDER BY操作,得到的结果如下所示:

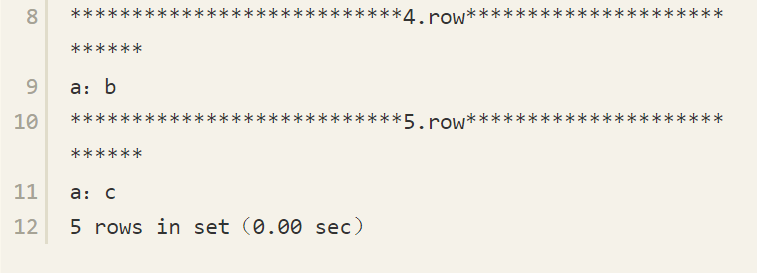
再对列a进行分组统计:
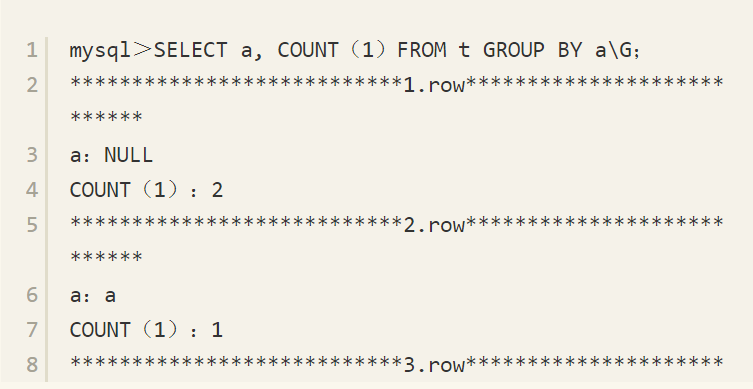
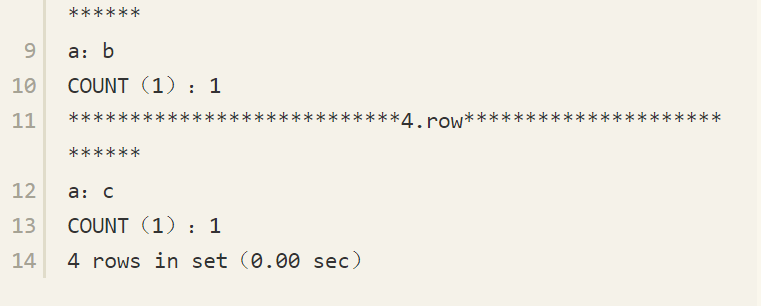
可见,对于ORDER BY的SQL查询语句,返回结果将两个NULL值先返回并排列在一起。对于GROUP BY的查询语句,返回NULL值的有两条记录。
因此在产生虚拟表VT2时,会增加一个额外的列来表示ON过滤条件的返回值,返回值有TRUE、FALSE、UNKNOWN,如表3-5所示。
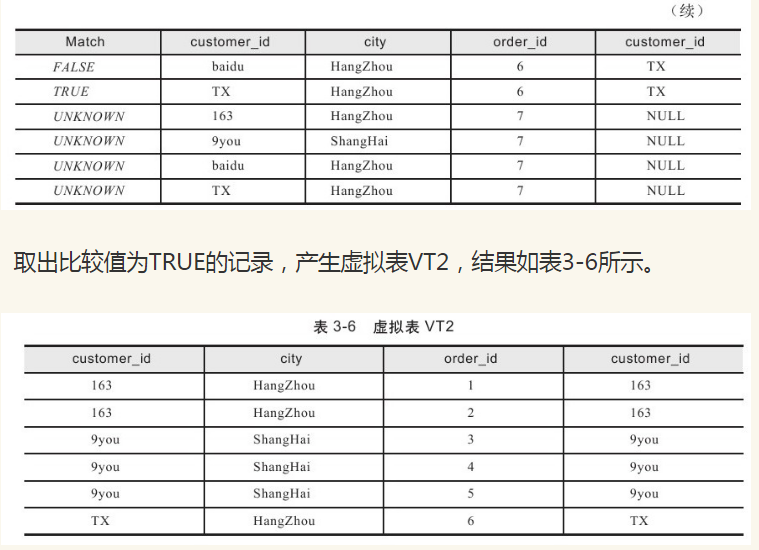
3.1.3 添加外部行
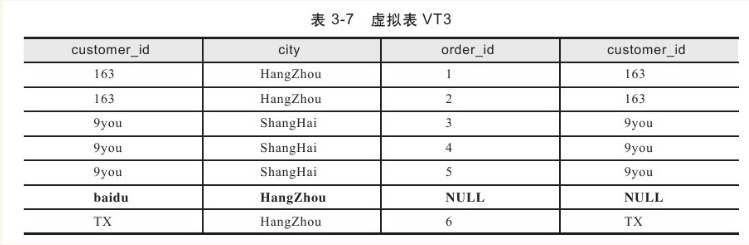
这一步只有在连接类型为OUTER JOIN时才发生,如LEFT OUTER JOIN、RIGHT OUTER JOIN、FULL OUTER JOIN。虽然在大多数时候我们可以省略OUTER关键字,但OUTER代表的就是外部行。LEFT OUTER JOIN把左表记为保留表,RIGHT OUTER JOIN把右表记为保留表,FULL OUTER JOIN把左右表都记为保留表。添加外部行的工作就是在VT2表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据被赋予NULL值,最后生成虚拟表VT3,如表3-7所示。
在这个例子中,保留表是customers,设置保留表的过程如下:

顾客baidu在VT2表中由于没有订单而被过滤,因此baidu作为外部行被添加到虚拟表VT2中,将非保留表中的数据赋值为NULL。
如果需要连接表的数量大于2,则对虚拟表VT3重做本节首的步骤1)~步骤3),最后产生的虚拟表作为下一个步骤的输出。
3.1.4 应用WHERE过滤器
对上一步骤产生的虚拟表VT3进行WHERE条件过滤,只有符合<where_condition>的记录才会输出到虚拟表VT4中。
在当前应用WHERE过滤器时,有两种过滤是不被允许的:
由于数据还没有分组,因此现在还不能在WHERE过滤器中使用where_condition=MIN(col)这类对统计的过滤。
由于没有进行列的选取操作,因此在SELECT中使用列的别名也是不被允许的,如SELECT city as c FROM t WHERE c='ShangHai'是不允许出现的。
首先来看一个在WHERE过滤条件中使用分组过滤查询导致出错的例子。

可以看到MySQL数据库提示错误地使用了分组函数。接着来看一个列别名使用出错的例子。

因为在当前的步骤中还未进行SELECT选取列名的操作,所以此时的列别名是不被支持的,MySQL数据库抛出了错误,提示未知的列c。
应用WHERE过滤器:WHERE c.city='HangZhou',最后得到的虚拟表VT4如表3-8所示。
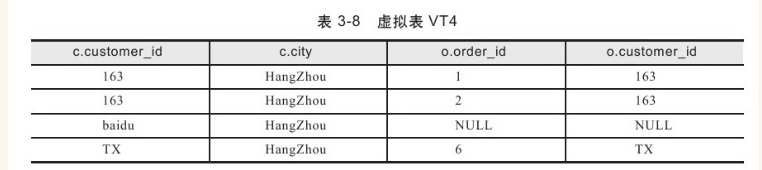
此外,在WHERE过滤器中进行的过滤和在ON过滤器中进行的过滤是有所不同的。对于OUTER JOIN中的过滤,在ON过滤器过滤完之后还会添加保留表中被ON条件过滤掉的记录,而WHERE条件中被过滤掉的记录则是永久的过滤。在INNER JOIN中两者是没有差别的,因为没有添加外部行的操作。来看下面这个查询:

得到的结果如表3-9所示。
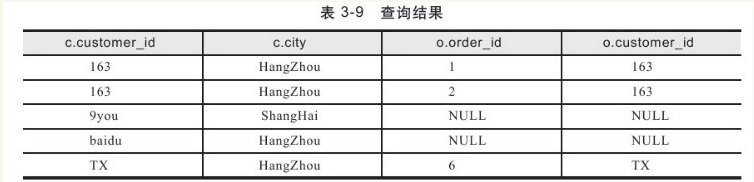
对比表3-8和表3-9可以发现,customer_id为9you的记录被添加入后者的查询中。这是因为ON过滤条件虽然过滤掉了city不等于“HangZhou”的记录,但是由于查询是OUTER JOIN,因此会对保留表中被排除的记录进行再次的添加操作。
3.1.5 分组
在本步骤中根据指定的列对上个步骤中产生的虚拟表进行分组,最后得到虚拟表VT5,如表3-10所示。在示例中进行如下分组:
GROUP BY c.customer_id
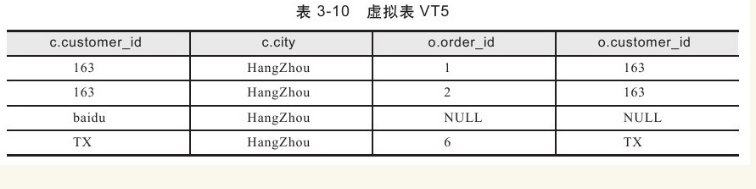
前面已经介绍了在执行GROUP BY阶段,数据库认为两个NULL值是相等的,因此会将NULL值分到同一个分组中。
3.1.6 应用ROLLUP或CUBE
如果指定了ROLLUP选项,那么将创建一个额外的记录添加到虚拟表VT5的最后,并生成虚拟表VT6。因为我们的查询并未用到ROLLUP,所以将跳过本步骤。
对于CUBE选项,MySQL数据库虽然支持该关键字的解析,但是并未实现该功能。若执行带有CUBE选项的SQL语句,用户可能会得到如下的错误提示:


可以看到提示当前的MySQL数据库版本不支持CUBE操作。
3.1.7 应用HAVING过滤器
这是最后一个条件过滤器了,之前已经分别应用了ON和WHERE过滤器。在该步骤中对于上一步产生的虚拟表应用HAVING过滤器,HAVING是对分组条件进行过滤的筛选器。对于示例的查询语句,其分组条件为:

因此将customer_id为163的订单从虚拟表中删除,生成的虚拟表VT6如表3-11所示。

需要特别注意的是,在这个分组中不能使用COUNT(1)或COUNT(*),因为这会把通过OUTER JOIN添加的行统计入内而导致最终查询结果与预期结果不同。在这个例子中只能使用COUNT o.order_id才能得到预期的结果。例如,将分组查询语句改成COUNT(*),则会得到如表3-12所示的结果。

显然顾客baidu并没有任何的订单操作,返回预期应该为0,但是在COUNT(*)的条件下,该返回值为1。
注意 子查询不能用做分组的聚合函数,如HAVING COUNT(SELECT……)<2是不合法的。
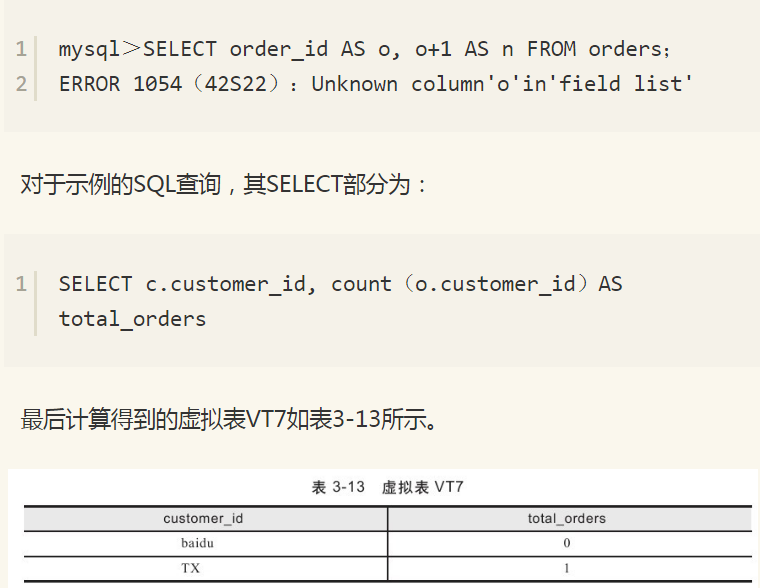
3.1.8 处理SELECT列表
虽然SELECT是查询中最先被指定的部分,但是直到步骤8)时才真正进行处理。在这一步中,将SELECT中指定的列从上一步产生的虚拟表中选出。
有一点容易被忽视的是,列的别名不能在SELECT中的其他别名表达式中使用。因此对于下列查询MySQL数据库会抛出错误提示:
3.1.9 应用DISTINCT子句
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存中存放不下就放到磁盘上)。这张内存临时表的表结构和上一步产生的虚拟表一样,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来去除重复数据。
由于在这个SQL查询中未指定DISTINCT,因此跳过本步骤。另外,对于使用了GROUP BY的查询,再使用DISTINCT是多余的,因为已经进行分组,不会移除任何行。
3.1.10 应用ORDER BY子句
根据ORDER BY子句中指定的列对上一步输出的虚拟表进行排列,返回新的虚拟表。还可以在ORDER BY子句中指定SELECT列表中列的序列号,如下面的语句:

等同于:

通常情况下,并不建议采用这种方式来进行排序,因为程序员可能修改了SELECT列表中的列,而忘记修改ORDER BY中的列表。当然,如果用户对网络传输要求很高,这也不失为一种节省网络传输字节的方法。
对于这里的示例,ORDER BY子句为:

最后得到的虚拟表如表3-14所示。

大多数DBA和开发人员都错误地认为在选取表中的数据时,记录会按照表中主键的大小顺序地取出,即结果像进行了ORDER BY一样。导致这个经典错误的原因主要是没有理解什么才是真正的关系数据库。下面介绍一下关系数据库的起源。
1970年,IBM公司的研究员、有“关系数据库之父”之称的E.F.Codd博士在刊物《Communication of the ACM》上发表了题为“A Relational Model of Data for Large Shared Data banks(大型共享数据库的关系模型)”的论文,文中首次提出了“数据库的关系模型”的概念,奠定了关系模型的理论基础。后来Codd又陆续发表多篇文章,论述了范式理论和衡量关系系统的12条准则,用数学理论奠定了关系数据库的基础。IBM的Ray Boyce和Don Chamberlin将Codd关系数据库的12条准则的数学定义以简单的关键字语法表现出来,里程碑式地提出了SQL语言。由于关系模型的相关书籍简单明了、具有坚实的数学理论基础,因此一经推出就受到了学术界和产业界的高度重视和广泛响应,并很快成为数据库市场的主流。20世纪80年代以来,计算机厂商推出的数据库管理系统几乎都支持关系模型,数据库领域当前的研究工作大都以关系模型为基础。
关系数据库是在数学的基础上发展起来的,关系对应于数学中集合的概念。数据库中常见的查询操作其实对应的是集合的某些运算:选择、投影、连接、并、交、差、除。最终的结果虽然是以一张二维表的方式呈现在用户面前,但是从数据库内部来看是一系列的集合操作。因此,对于表中的记录,用户需要以集合的思想来理解。对于customers和orders表,更准确的描述应如图3-2所示。
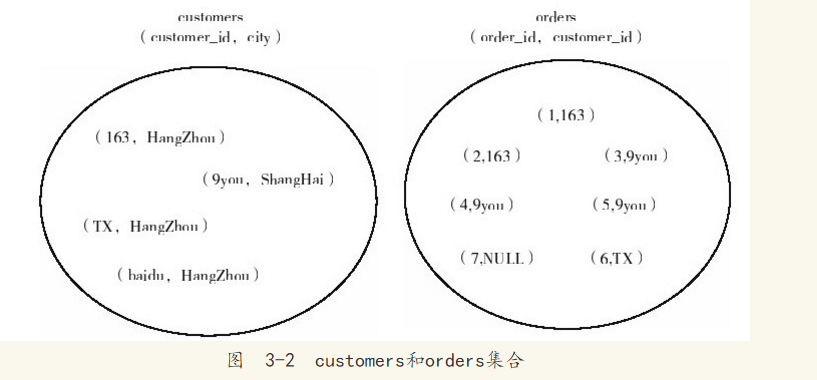
将图3-2和表3-1、表3-2进行对比。表3-1、表3-2以一张二维表来展示,而实际上更应该将表中的数据理解为图3-2。因为表中的数据是集合中的元素,而集合是无序的。因此对于没有ORDER BY子句的SQL语句,其解析结果应为:从集合中选择期望的子集合。这表明结果并不一定要有序。
3.1.11 LIMIT子句
在该步骤中应用LIMIT子句,从上一步骤的虚拟表中选出从指定位置开始的指定行数据。对于没有应用ORDER BY的LIMIT子句,结果同样可能是无序的,因此LIMIT子句通常和ORDER BY子句一起使用。
MySQL数据库的LIMIT支持如下形式的选择:
LIMIT n, m
表示从第n条记录开始选择m条记录。而大多数开发人员喜欢使用这类语句来解决Web中经典的分页问题。对于小规模的数据,这并不会有太大的问题。对于论坛这类可能具有非常大规模数据的应用来说,LIMIT n, m的效率是十分低的。因为每次都需要对数据进行选取。如果只是选取前5条记录,则非常轻松和容易;但是对100万条记录,选取从第80万行记录开始的5条记录,则还需要扫描记录到这个位置。因此,对于数据量非常庞大的分页问题,在应用层建立一定的缓存机制是十分必要的。
由于示例中SQL语句没有LIMIT子句,因此最后得到的结果应如表3-16所示。

3.2 物理查询处理
上一节介绍了逻辑查询处理,并且描述了执行查询应该得到什么样的结果。但是数据库也许并不会完全按照逻辑查询处理的方式来进行查询。图1-1显示了在MySQL数据库层有Parser和Optimizer两个组件。Parser的工作就是分析SQL语句,而Optimizer的工作就是对这个SQL语句进行优化,选择一条最优的路径来选取数据,但是必须保证物理查询处理的最终结果和逻辑查询处理是相等的。
如果表上建有索引,那么优化器就会判断SQL语句是否可以利用该索引来进行优化。如果没有可以利用的索引,可能整个SQL语句的执行代价非常大。来看如下的一个例子,先生成表和数据,这里使用了第2章介绍的数字辅助表。

通过数字辅助表生成了10万行数据表x和18万行数据表y。表x和表y上都没有索引,因此最终SQL解析器解析的执行结果为逻辑处理的步骤,也就是按照上一节中分析的,总共经过11个步骤来进行数据的查询。最先根据笛卡儿积生成一张虚拟表VT1,表x有10万行数据,表y有18万行数据,这意味着进行笛卡儿积后产生的虚拟表VT1总共有180亿行的数据!因此运行这条SQL语句,在笔者的双核笔记本上,InnoDB缓冲池配置为128MB,总共执行50多分钟,具体情况如下:

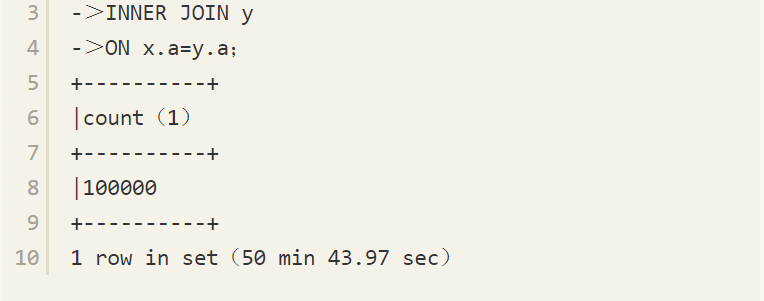
有人可能会认为,128MB的InnoDB缓冲池太小,从而导致内存中无法存放这么多数据而使执行需要花费这么长的时间。其实不然,表x和表y的大小都没有超过20MB,足够存放在128MB的内存缓冲池中,语句执行速度慢的主要原因是需要产生180亿次的数据。即便是在内存中产生这么多次的数据,也需要花费很长的时间。然而,如果这时对表y添加一个主键值,再执行这条SQL语句,你会惊讶地发现只需要0.85秒,具体情况如下:

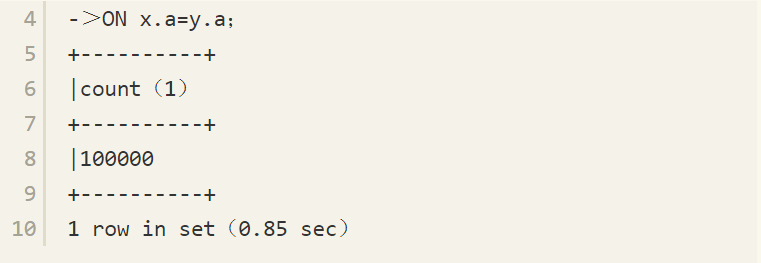
性能提高了3000多倍!促使这个查询时间大幅减少的原因很简单,就是在添加索引后避免了笛卡儿表的产生,因此大幅缩短了语句运行的时间。我们可以通过EXPLAIN命令来查看经SQL优化器优化后MySQL数据库实际选择的执行方式,如下所示:


添加索引是非常有技巧的一项工作,正确地利用索引的特性能显著提高SQL语句运行的效率。但是一味地添加很多索引反而会导致数据库运行得更慢。在后面的章节会详细介绍索引的数据结构,通过内部的实现来更好地理解如何使用索引。目前,读者要明白的是物理查询会根据索引来进行优化,这也是MySQL数据库优化器的一项重要工作。
3.3 小结
理解逻辑查询各个处理阶段对于理解SQL编程所需要的特殊观念是非常重要且有必要的。本章详细介绍了逻辑处理的11个步骤,3个过滤处理器ON、WHERE和HAVING,以及这3个过滤器的使用过程和不同之处。其中,稍微涉及了一些关于NULL值的讨论,这在后面的章节也会遇到。
在本章最后,简单介绍了物理查询处理。逻辑查询只是描述了应该产生什么样的结果。至于MySQL数据库通过SQL解析器完成对于SQL语句的解析,并通过SQL优化器选择最优的执行路径,这是物理查询处理过程。物理查询可以利用表上的索引来缩短SQL语句运行的时间,以此来提高数据库的整体性能。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

