一、索引开发
如何进行高质量的SQL编程,对索引的掌握和理解是关键。正确地使用索引可使SQL语句运行得更快,而错误地添加和使用索引可能带来有灾难性的结果。然而,如果DBA或开发人员能够了解索引的本质,例如索引是怎么实现的,优化器是怎么使用索引的,显然这会为SQL编程带来极大的提高。此外,不要盲从于一些所谓的规律,比如联合索引(a, b),索引不会用于对b列的查询。笔者始终相信,只要理解事物的本质,那么所有的问题都会迎刃而解。
9.1 缓冲池、顺序读取与随机读取
根据存储介质的不同,可以将数据库分为基于磁盘的数据库系统、基于内存的数据库系统,以及混合型数据库系统。基于磁盘的数据库系统(disk-base database)是最为常见的一种关系型数据库,比如MySQL、Oracle、SQL Server、DB2数据库。随着内存容量的不断增加,基于内存的数据库系统(in-memory database)也变得十分流行,MySQL NDB Cluster, Oracle Ten Times等数据库厂商都提供了内存关系型数据库系统。而混合型数据库系统(hybrid database)将上述两种数据库的优点进行了结合。
毫无疑问,基于内存的数据库系统是最快的,因为数据库不需要对磁盘进行操作。磁盘的速度要远慢于内存的速度,因此基于磁盘的数据库系统一般都有缓冲池,即一块内存区域,其作用是将从磁盘上读取的指定大小数据——称为页(或块),放入缓冲池。当再次读取时,数据库首先判断该页是否在缓冲池中,如果在则直接读取缓冲池中的页,如果不在则读取磁盘上的页。对于写操作,数据库将页读入缓冲池,然后在缓冲池中对页进行修改,修改完成后的页一般被异步地写入磁盘上。对于缓冲池的维护一般采用最近最少使用(Least Recently Used, LRU)算法。由此可见,缓冲池的大小决定了数据库的性能。若数据库中的数据可以完全存放于缓冲池中,则可以认为这时数据库的性能是最优的。除了同步/异步的写磁盘操作外,所有其他操作都可以在内存中完成。
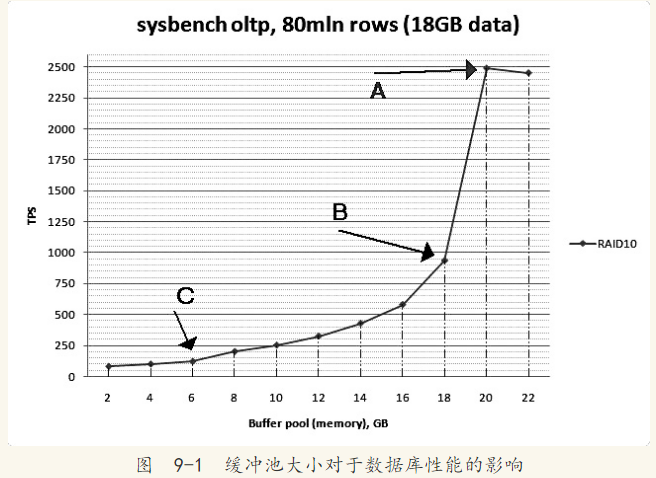
对于MySQL数据库系统,由于其有着各种不同的存储引擎,因此其缓冲池是基于存储引擎的,也就是说每个存储引擎都有自己的缓冲池。对于MyISAM存储引擎来说,变量key_buffer_size决定了缓冲池的大小。对于InnoDB存储引擎来说,变量innodb_buffer_pool_size决定了缓冲池的大小。图9-1是Percona公司CTO Vadim对缓冲池所做的性能测试
图9-1中的A点表示此时缓冲池为20GB,数据库的数据全部被缓存在缓冲池中,这时数据库的性能是最优的,测试的结果为2500TPS(transaction per second)。因为数据已经全部被缓存,继续增大缓冲池为22GB并不会对性能有多大的提升。B点表示缓冲池的大小为18 GB,此时只有一小部分的数据不能被缓存,测试的结果为900TPS。可见缓冲池大小减少了10%,性能却下降了164%。C点表示缓冲池的大小为6GB,只能缓存30%的数据,这时数据库的性能更差,测试结果为130 TPS。
备注:有些同学对测试的名词可能不了解:http://www.ha97.com/5095.html 此篇链接详细介绍了专业测试的名词。例如tps,qps等,
通过上文个人总结:经过严格的基准测试既然缓冲池决定了Mysql的性能,那我们就来研究一下它,并调整其大小,然后在进行测试。
此链接介绍了怎么调整其大小,解释的比较详细还有个人案例做枚举:https://my.oschina.net/realfighter/blog/368225
在现实的生产环境中,在大多数情况下经过线上的一段运行时间后,数据库的大小通常都会大于内存的大小。例如数据库的大小是500GB,而服务器的内存可能只有96GB或者128GB。这种情况非常正常,一般来说,对于500GB的数据库,热点的数据可能是小部分的,具体占据多大的比重,这取决于具体的应用。
在生产环境中缓冲池的大小小于数据文件的大小,因此不可避免地存在磁盘的读取操作。但是传统的机械硬盘的特性决定了顺序读取要远快于离散读取。图9-2显示了传统机械硬盘的构造。

传统机械硬盘由磁头(head)、磁道(track)、扇区(sector)、柱面(cylinder)组成。读取时需要通过磁头的移动来定位数据,这个时间称为寻道时间(seek time)。目前,一块15000转SAS传统的机械硬盘的平均寻道时间为2.58ms。需要注意的是,这指的是平均时间。根据平均寻道时间,可以大致估算IOPS(IO per second),即1000/2.58=380 IOPS,而在实际情况下单块磁盘的IOPS一般为150左右。如果数据都是顺序存放的,显然寻道时间会快很多,这时的寻道时间一般只需0.14ms。可见,比平均寻道时间提高了18倍。
在介绍完上述内容后,可以给出顺序读取、随机读取的定义。顺序读取(sequntial read)是指顺序地读取磁盘上的页。随机读取(random read)是指访问的页不是连续的,需要磁盘的磁头不断移动。这里需要注意的是,这里的“顺序”指的是逻辑上的顺序,在物理上不可能保证所有的数据都是顺序的。而为了保证顺序,数据库存储引擎一般都根据区(extent)来管理页,例如在InnoDB存储引擎中1个区是连续的64个页。因此在顺序读取数据库时,可以保证这64个页是连续的,而区与区之间的页,可能是连续的也可能是不连续的。
固态硬盘是近几年出现的一种新的存储设备,其内部由闪存(flash memory)组成。因为具有低延迟性、低功耗、轻量,以及防震性,闪存设备已在移动设备上得到了广泛的应用。而企业级的生产应用使用固态硬盘,同时通过并联多块闪存来进一步提高数据传送的吞吐量。
图9-3显示了一个双通道的固态硬盘架构,通过支持4路的闪存交叉存储来降低固态硬盘的访问延时,同时增大并发的读写操作。而通过进一步增加通道的数量,固态硬盘的性能可以有线性的提高,例如常见的Intel SSD X-25M就是10通道的固态硬盘。
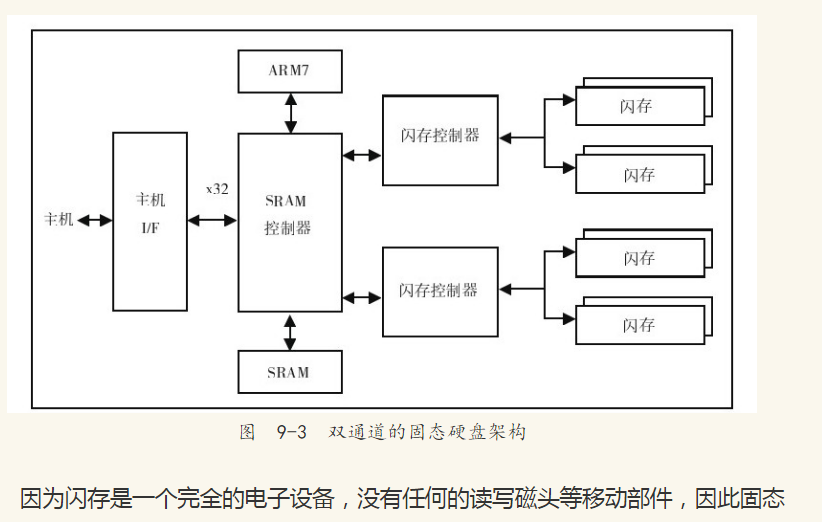
硬盘有着较低的访问延时。当主机发布一个读写请求时,固态硬盘的控制器会把I/O命令从逻辑地址映射到实际的物理地址,写操作还需要修改相应的映射表信息。算上这些额外的开销,固态硬盘的访问延时一般小于0.1 ms左右,随机读取可达4000 IOPS甚至更高。即使是固态硬盘,顺序读取还是要快于随机读取。因此对于固态硬盘的优化需要不同于传统机械硬盘的思考,但是这更多的是数据库存储引擎内部需要考虑的问题。
上述巴拉巴拉一大堆读个热闹就行,不必深究,总之一句话,性能不行:机械换固态。
9.2 数据结构与算法
B+树索引是最为常见,也是在数据库中使用最为频繁的一种索引。在介绍该索引之前先介绍与之密切相关的一些算法与数据结构,这有助于读者更好地理解B+树索引的工作方式。
9.2.1 二分查找法
二分查找法(binary search)也称为折半查找法,用来查找一组有序记录数组中某一项记录。其基本思想是:将记录按有序化(递增或递减)排列,查找过程中采用跳跃式方式查找,即先以有序数列的中点位置为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。
例如对于5、10、19、21、31、37、42、48、50、52这10个数,要从中查找48这条记录,其查找过程如图9-4所示。
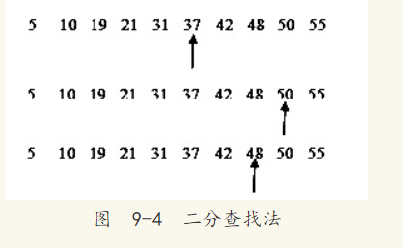
从图9-4可以看出,3次就找到了48这个数。如果是顺序查找,则需要8次。因此二分查找法的效率比顺序查找法要好(平均来说),如果说查5这条记录,顺序查找只需1次,而二分查找法需要4次。对于上面10个数来说,平均查找次数为(1+2+3+4+5+6+7+8+9+10)/10=5.5次,而二分查找法为(4+3+2+4+3+1+4+3+2+3)/10=2.9次。在最坏的情况下,顺序查找的次数为10,而二分查找的次数为4。
二分查找法的应用极其广泛,并且它的思想易于理解。第一个二分查找算法早在1946年就出现了,但是第一个完全正确的二分查找算法直到1962年才出现。
在B+树索引中,B+树索引只能找到某条记录所在的页,需再根据二分查找法来进一步找到记录所在页的具体位置。
9.2.2 二叉查找树和平衡二叉树
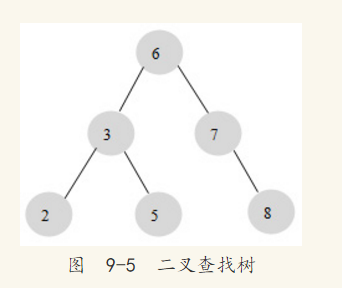
在介绍B+树前,先要了解一下二叉查找树。B+树是通过二叉查找树,再由平衡二叉树、B树演化而来。相信在任何一本有关数据结构的书中都可以找到二叉查找树的章节,二叉查找树是一种经典的数据结构。图9-5显示了一棵二叉查找树。
图9-5中的数字代表每个节点的键值。在二叉查找树中,左子树的键值总是小于根的键值,右子树的键值总是大于根的键值,因此可以通过中序遍历得到键值的排序输出。对图9-5进行中序遍历后输出:2、3、5、6、7、8。
对图9-5的这棵二叉树进行查找,如查找键值为5的记录,先找到根,其键值是6,6大于5,因此查找6的左子树,找到3;而5大于3,再找右子树……一共找了3次。如果按2、3、5、6、7、8的顺序来找同样需要3次。用同样的方法再查找键值为8的这条记录,这次用了3次查找,而顺序查找时需要6次。如果计算平均查找次数可得:顺序查找的平均查找次数为(1+2+3+4+5+6)/6=3.3次,二叉查找树的平均查找次数为(3+3+3+2+2+1)/6=2.3次。二叉查找树比顺序查找的平均效率要高。
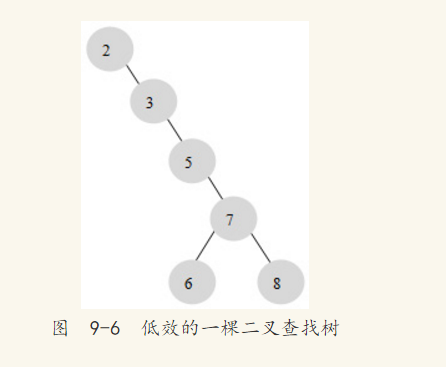
二叉查找树可以任意构造,同样是2、3、5、6、7、8这五个数字,也可以按照图9-6的方式建立二叉查找树。
图9-6的平均查找次数为(1+2+3+4+5+5)/6=3.16次,和顺序查找差不多。显然这棵二叉查找树的效率就差很多。因此若想最大性能地构造一个二叉查找树,需要这棵二叉查找树是平衡的,因此引入了新的定义——平衡二叉树,又称为AVL树。
平衡二叉树的定义如下:首先符合二叉查找树的定义,其次必须满足任何节点的两棵子树的高度最大差为1。显然,图9-6不满足平衡二叉树的定义,而图9-5是一棵平衡二叉树。平衡二叉树在查找方面的性能是比较高的,但不是最高的,只是接近最高性能。要达到最好的性能需要建立一棵最优二叉树,但是最优二叉树的建立和维护需要大量的操作,因此一般只需建立一棵平衡二叉树即可。
平衡二叉树的查询速度的确很快,但是维护一棵平衡二叉树的代价非常大,通常需要1次或多次左旋或右旋来得到经过插入或更新操作后二叉树的平衡性。对于图9-5所示的平衡树,当我们需要插入一个新的键值为9的节点时,需要做如图9-7所示的变动。
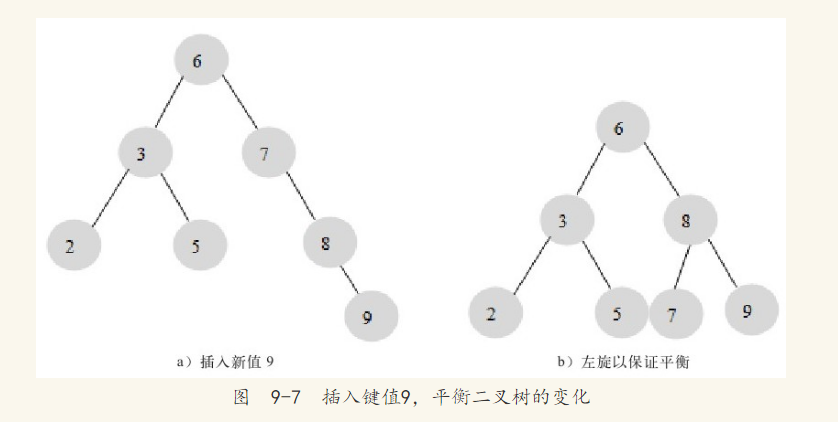
这里通过一次左旋操作就将插入后的树重新变为平衡二叉树。但是有的情况可能需要进行多次的旋转操作,如图9-8所示。

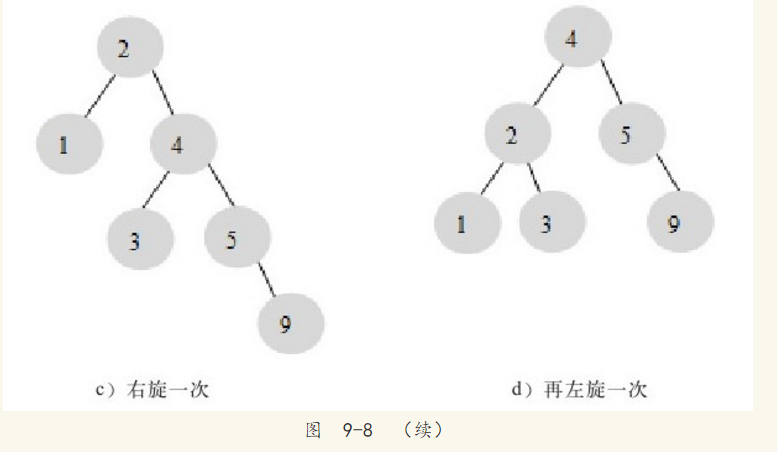
图9-7和图9-8演示了向一棵平衡二叉树插入一个新的节点后,平衡二叉树需要做的旋转操作。除了插入操作,还有更新和删除操作,不过进行这些操作后在恢复二叉树的平衡性上没有本质的区别,它们都是通过左旋或者右旋来完成。因此对一棵平衡树的维护是有一定开销的,不过平衡二叉树多用于内存结构对象中,因此维护的开销相对较小。
9.3 B+树
B+树和二叉树、平衡二叉树都是经典的数据结构。B+树由B树和索引顺序访问方法(ISAM,是不是很熟悉?对,这也是MyISAM引擎最初参考的数据结构)演化而来,但是在实现过程中几乎没有使用B树的情况了。
相信在任何一本数据结构书中都能找到B+树的定义,其定义十分复杂,这里列出B+树的定义只会让读者感到更加困惑。因此这里只精简地给出B+树的介绍:B+树是为磁盘或其他直接存取辅助设备设计的一种平衡查找树,在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点,各叶子节点通过指针进行链接。先来看一个B+树,如图9-9所示,其高度为2,每页可存放4条记录,扇出(fan out)为5:

从图9-9可以看出,所有记录都在叶子节点上,并且是顺序存放的,如果我们从最左边的叶子节点开始顺序遍历,可以得到所有键值的顺序排序:5、10、15、20、25、30、50、55、60、65、75、80、85、90。
9.3.1 B+树的插入操作
B+树的插入要求必须保证插入后叶子节点中的记录依然顺序排列,同时需要考虑插入到B+树的3种情况,每种情况都可能导致不同的插入算法,如表9-1所示。

通过实例来分析B+树的插入。对于图9-9中的这棵B+树,我们插入28这个键值,发现当前Leaf Page和Index Page都没有满,直接插入就可以了,如图9-10所示。
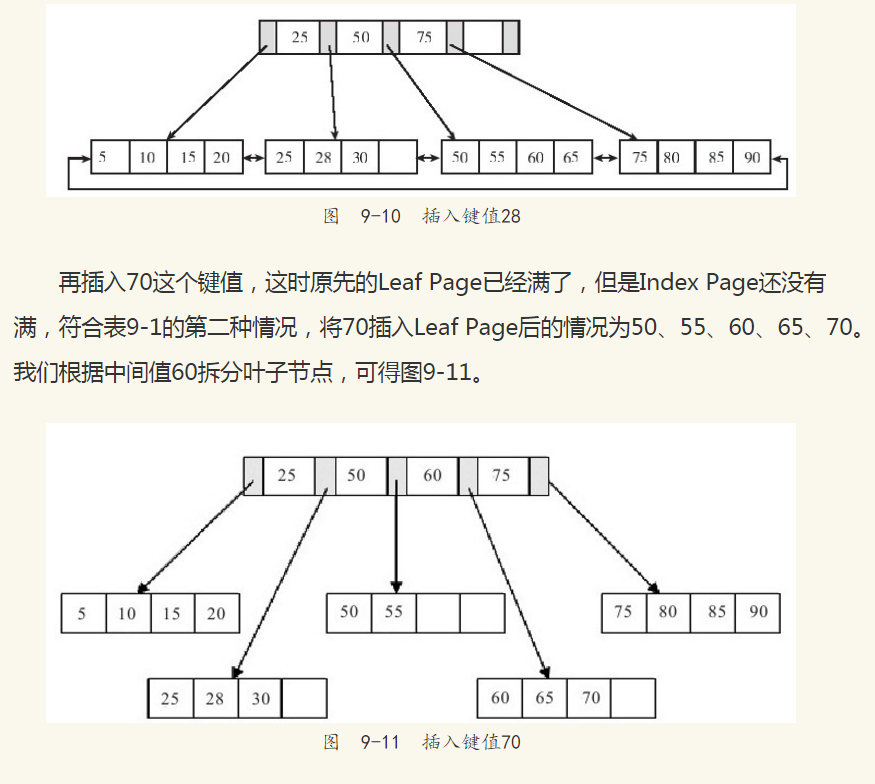
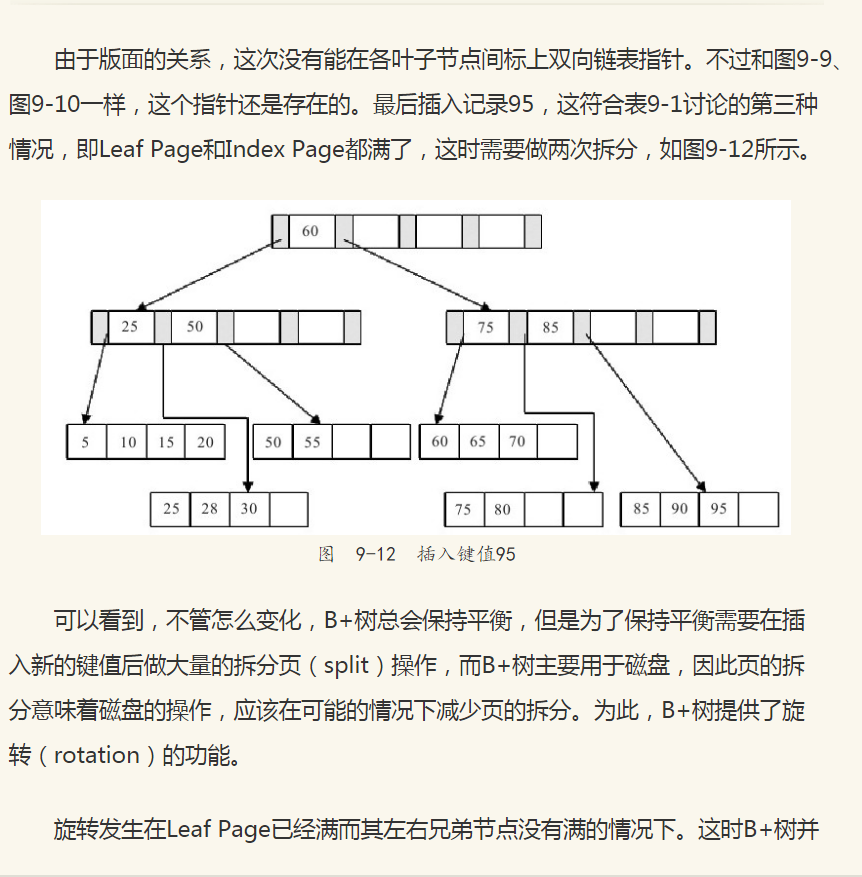
不会急于进行拆分页的操作,而是将记录移到所在页的兄弟节点上。通常先判断左兄弟是否被用来做旋转操作,因此对于图9-10的情况,在插入键值70时,B+树并不会急于拆分叶子节点,而是去做旋转操作,如图9-13所示。
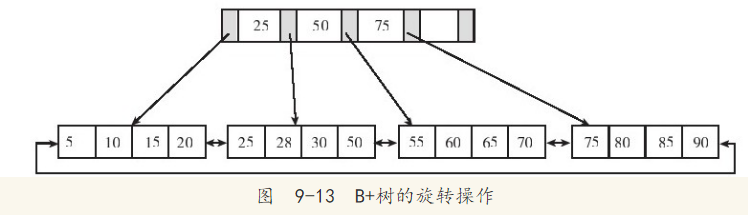
图 9-13 B+树的旋转操作
从图9-13可以看到,采用旋转操作使B+树减少了一次页的拆分操作,这时B+树的高度依然还是2。
9.3.2 B+树的删除操作
B+树使用填充因子(fill factor)来控制树的删除变化,填充因子可设的最小值是50%。B+树的删除操作同样必须保证删除后叶子节点中的记录依然按序排列。同插入一样,B+树的删除操作同样需要考虑以下3种情况。与插入不同的是,删除根据填充因子的变化来衡量。

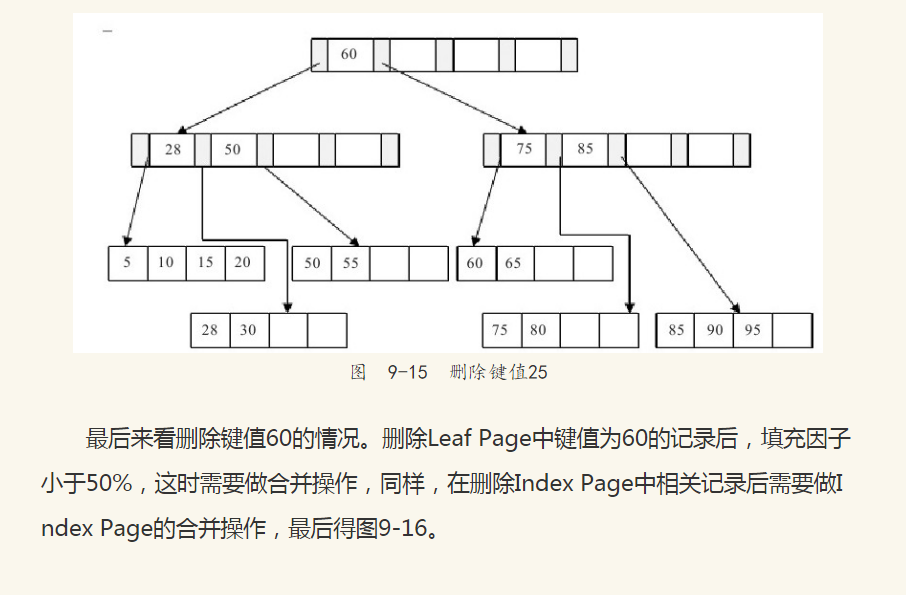
接着删除键值为25的记录,这也符合表9-2讨论的第一种情况,但是该值还是Index Page中的值,因此在删除Leaf Page中的25后,还应将25的右兄弟节点28更新到Page Index中,最后可得图9-15。
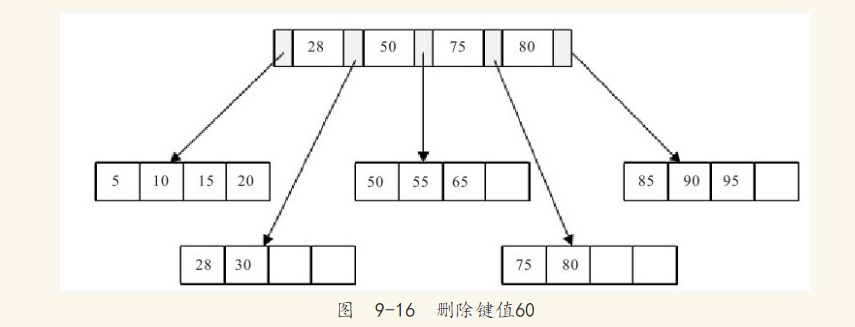
9.4 B+树索引
前面讨论的都是B+树的数据结构及其一般操作,B+树索引的本质就是B+树在数据库中的实现,而B+树索引在数据库中的一个特点就是高扇出性。例如在InnoDB存储引擎中,每个页的大小为16KB。
因此在数据库中,B+树的高度一般都在2~4层,这意味着查找某一键值最多只需要2到4次IO操作,这还不错。因为现在一般的磁盘每秒至少可以做100次IO操作,2~4次的IO操作意味着查询时间只需0.02~0.04秒。
在MySQL数据库中,索引是在存储引擎层实现的,这意味着每个引擎的B+树索引的实现方式可能是不同的,取决于存储引擎实现的本身。
B+树索引可以分为聚集索引与辅助索引(非聚集索引),但是这两者本身都与之前讨论的B+树的数据结构一样,区别仅在于所存放数据的内容。
9.4.1 InnoDB B+树索引
InnoDB存储引擎是索引组织表(Index Organized Table, IOT),也就是说数据文件本身就是按照B+树方式存放数据的。其中,B+树的键值为主键,若在建立时没有显式地指定主键,则InnoDB存储引擎会自动创建一个6字节的列作为主键。因此在InnoDB存储引擎中,可以将B+树索引分为聚集索引(clustered index)和辅助索引(secondary index)。无论是何种索引,每个页的大小都为16KB,且不能更改。
聚集索引是根据主键创建的一棵B+树,聚集索引的叶子节点存放了表中的所有记录。辅助索引是根据索引键创建的一棵B+树,与聚集索引不同的是,其叶子节点仅存放索引键值,以及该索引键值指向的主键。也就是说,如果通过辅助索引来查找数据,那么当找到辅助索引的叶子节点后,很有可能还需要根据主键值查找聚集索引来得到数据,这种查找方式又被称为书签查找(bookmark lookup)。因为辅助索引不包含行记录的所有数据,这就意味着每页可以存放更多的键值,因此其高度一般都要小于聚集索引。
注意 若辅助索引是一个包含主键的联合索引,那么并不需要一个额外的列来存放主键值。辅助索引会选择通过联合索引中的主键进行查找。
图9-17显示了在InnoDB存储引擎中聚集索引和辅助索引的关系。
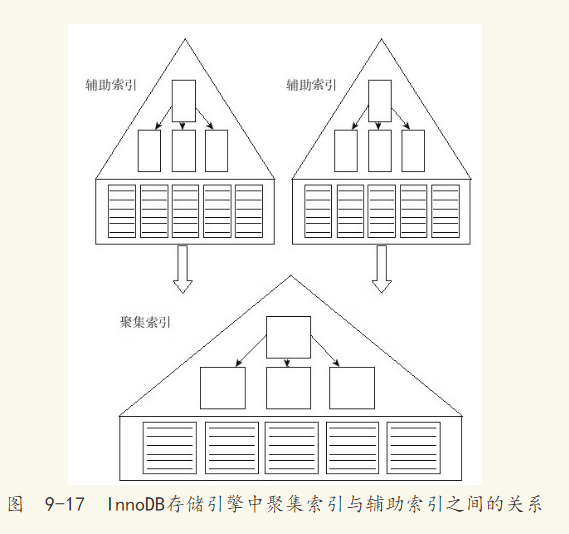
接着来看一张表,这里以人为方式使其每个页只能存放两个行记录,例如:

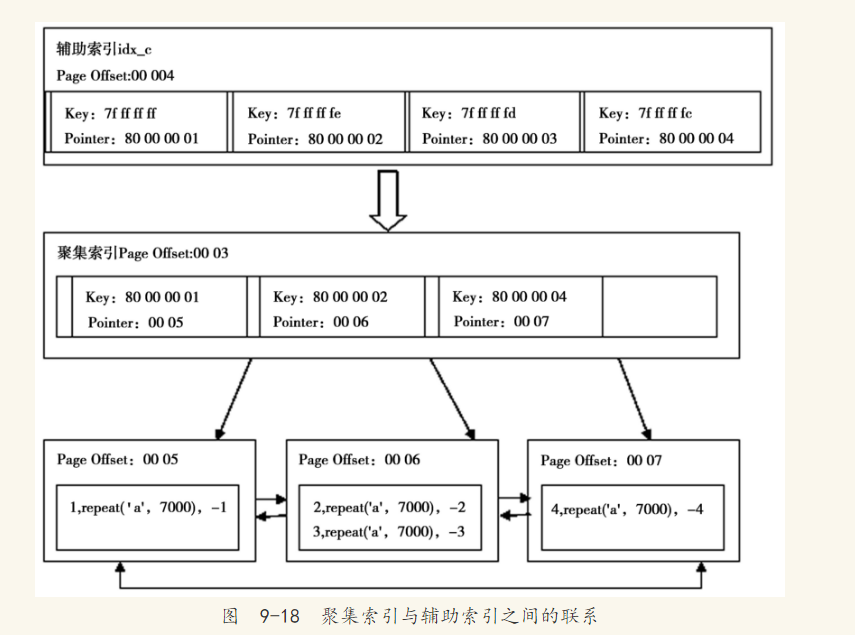
可见辅助索引idx_c是一棵高度为1的B+树,叶子节点存放了所有的索引键值及其对应的主键(-1,1),(-2,2),(-3,3),(-4,4)。由于c列是有符号的整型,因此在数据库内部用0x7FFFFFFF来表示-1。聚集索引是一棵高度为2的B+树,叶子节点存放了所有的记录(1,repeate('a',7000),-1)、(2,repeat('a',7000),-2)、(3,repeat('a',7000),-3)、(4,repeat('a',7000),-4)。
注意 《MySQL技术内幕:InnoDB存储引擎》一书中对InnoDB存储引擎的B+树索引有更为详细和深入的分析,强烈建议高级DBA和开发人员阅读此书,这对更好地理解InnoDB存储引擎的实现有着极大的帮助。
9.4.2 MyISAM B+树索引
此处介绍略,因感觉弊端太大,一般不会用MyIAM引擎。
9.5 Cardinality
9.5.1 什么是Cardinality
并不是所有在查询条件中出现的列都需要添加索引。对于什么时候添加B+树索引,一般的经验是,在访问表中很少一部分行时使用B+树索引才有意义。对于性别字段、地区字段、类型字段,它们可取值的范围很小,称为低选择性,例如:

按性别进行查询时,可取值的范围一般只有“M”和“F”,因此上述SQL语句得到的结果可能是该表50%的数据(我们假设男女比例1:1),这时添加B+树索引是完全没有必要的。相反,如果某个字段的取值范围很广,几乎没有重复,即是高选择性的,那么此时使用B+树索引是最适合的。例如姓名字段,基本上在每一个应用中都不允许出现重名。
怎样查看索引是否是高选择性的呢?可以通过SHOW INDEX语句中的Cardinality列来观察。Cardinality值非常关键,表示索引中唯一只记录数量的预估值。这里需要注意的是,Cardinality是一个预估值,而不是一个准确值,用户也不可能得到一个准确的值。在实际应用中,Cardinality/n_rows_in_table应尽可能接近1,
如果非常小,那么需要考虑是否还要建这个索引。因此在访问高选择性属性的字段,并从表中取出很少一部分数据时,对这个字段添加B+树索引是非常有必要的,例如:
SELECT*FROM member WHERE usernick='David'
表member大约有500万行数据,usernick字段上有一个唯一的索引。这时如果查找用户名为David的用户时,得到执行计划如下:
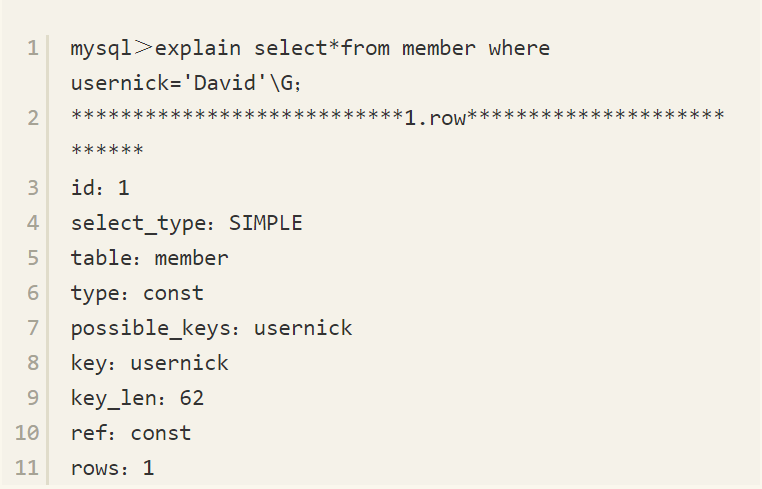

9.5.2 InnoDB存储引擎怎样统计Cardinality
上一小节介绍了Cardinality的重要性,并且告诉读者Cardinality表示索引的选择性。建立的索引是高选择性的这对数据库来说才是有意义的,但是数据库是怎样来统计Cardinality信息的呢?因为MySQL数据库中有各种不同的存储引擎,而每种存储引擎对B+树索引的实现又各不相同,所以对Cardinality的统计放在存储引擎中。
需要考虑到的是,在生产环境中,索引的更新操作可能非常频繁。如果在每次索引发生更新操作时就对其进行Cardinality的统计,那么将会给数据库带来很大的负担。另外需要考虑的是,如果一张表的数据量非常大,比如一张表有50GB的数据,那么统计一次Cardinality信息所需要的时间可能非常长。这在生产环境的应用中也是不能接受的。因此,数据库对于Cardinality的统计都是通过采样(sample)的方法来完成的。
在InnoDB存储引擎中,Cardinality统计信息的更新发生在两个操作中:INSERT和UPDATE。根据前面的叙述,不可能在每次发生INSERT和UPDATE时都去更新Cardinality的信息,这会增加数据库系统的负荷,同时对大表进行统计时,时间上也不允许。因此InnoDB存储引擎对于更新Cardinality信息的策略为:
表中1/16的数据已发生变化。
stat_modified_counter>2 000 000 000。
第一种策略为自上次统计Cardinality信息后,表中1/16的数据已经发生变化。这时需要更新Cardinality信息。第二种策略考虑的是,如果对表中某一行数据频繁地进行更新操作,这时表中的数据实际并没有增加,发生变化的还是这一行数据,那么第一种更新策略就无法适用,故在InnoDB存储引擎内部有一个计数器stat_modified_counter,用来表示发生变化的次数,当计数器的值大于2 000 000 000时,同样需要更新Cardinality信息。
接着考虑InnoDB存储引擎内部是怎样进行Cardinality信息的统计和更新操作的呢?同样是通过采样的方法。InnoDB存储引擎只对8个叶节点进行采样。采样的过程为:
取得B+树索引中叶节点的数量,即为A。
随机取B+树索引中的8个叶节点。统计每个页不同记录的个数,即为P1,P2,……,P8。
根据采样信息给出Cardinality的预估值:Cardinality=(P1+P2+……+P8)*A/8。
通过上述的说明可以发现,在InnoDB存储引擎中,Cardinality的值是通过对8个叶节点预估而得到的,不是一个精确的值。再者,每次对于Cardinality值的统计都是通过随机读取8个叶子节点得到的,这又暗示了另一个Cardinality的现象,即每次得到的Cardinality值可能是不同的。例如:

上述这句SQL语句会触发MySQL数据库对于Cardinality值的统计,第一次运行得到的结果如图9-20所示。
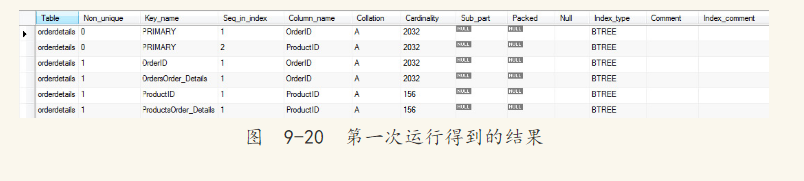
在上述测试过程中,并没有INSERT、UPDATE这类操作来改变表OrderDetails中的内容,但是当第二次运行SHOW INDEX FROM语句时,Cardinality的值还是发生了如图9-21所示的变化。

可以看到,在第二次运行SHOW INDEX FROM语句时,虽然表OrderDetails本身并没有发生任何的变化,但是表OrderDetails中索引的Cardinality值都发生了变化。由于Cardinality是对随机的8个叶子节点进行分析,因此即使表没有发生变化,用户观察到的索引Cardinality值还是会发生变化的,这本身并不是InnoDB存储引擎的Bug,只是随机采用数据导致的结果。
当然,可能会有用户每次观察到的索引Cardinality值都是一样的情况,那是因为表足够小,表的叶子节点小于或等于8个。这时即使随机采样,也总是会采取到这些页,因此每次得到的Cardinality值都相同。
9.6 B+树索引的使用
9.6.1 不同应用中B+树索引的使用
在了解了B+树索引的本质和实现后,下一个问题需要考虑怎样正确地使用B+树索引?这不是一个简单的问题。笔者所总结的可能并不适用于所有的应用场,这里只是概括出一个大概的方向,在实际的生产环境中,每个DBA和开发人员还要根据具体应用来使用索引,观察索引使用的情况,判断是否需要添加索引。“Think Different”,不要盲从任何人给你的经验意见。
根据第1章的介绍,我们知道数据库中存在两种类型的应用:OLTP和OLAP应用。在OLTP应用中,查询操作只从数据库中取得一小部分数据,一般都在10条记录以下,甚至大多数情况只获取1条记录,如根据主键值来取得用户信息、根据订单号取得订单的详细信息,这都是典型OLTP应用的查询语句。在这种情况下,建立B+树索引后,对该索引的使用应该只是通过该索引取得表中小部分的数据。这时建立B+树索引才是有意义的,否则即使建立了,优化器也可能选择不使用索引。
对于OLAP应用,情况可能稍显复杂一些。不过概括来说,在OLAP应用中都需要访问表中大量的数据,并根据这些数据来产生查询的结果,而这些查询多是面向分析的查询,目的是为决策者提供支持。比如这个月每个用户的消费情况、销售额同比或环比增长的情况。因此在OLAP中添加索引依据的是宏观的信息,而不是微观信息,这是因为最终要得到的结果是提供给决策者的。例如不需要在OLAP中对姓名字段进行索引,因为很少会对单个用户进行查询。但是对于OLAP中的复杂查询,需要涉及多张表之间的联接操作,这时索引的添加是有意义的。如果联接操作使用Hash Join,那么索引可能又变得不是非常重要了,所以DBA或开发人员要认真并仔细地研究自己的应用。不过在OLAP应用中,通常会需要对时间字段进行索引,这是因为大多数统计需要根据时间维度来进行判断。
9.6.2 联合索引
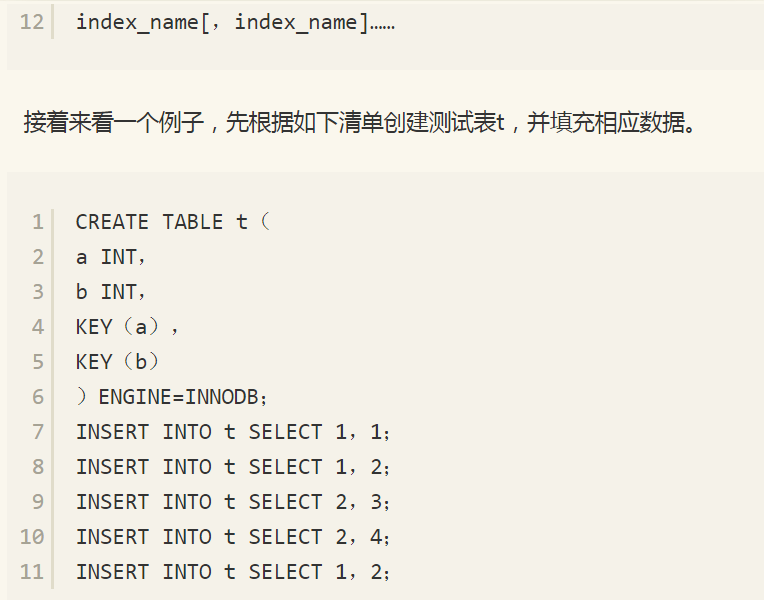
联合索引是指对表上的多个列进行索引。前面讨论的情况都是只对表中的一个列进行索引。联合索引的创建方法与单个索引创建的方法一样,不同之处仅在于有多个索引列。下面的语句创建了一张t表,其中索引idx_a_b是联合索引,联合的列为(a, b)。
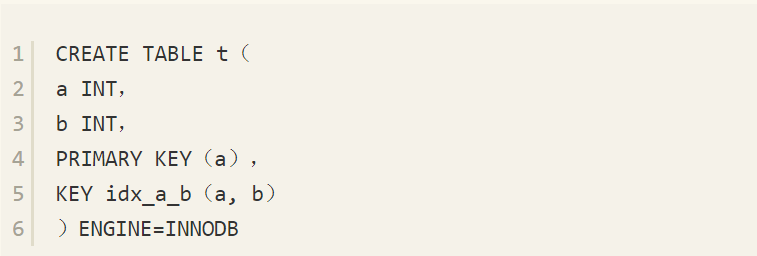
何时需要使用联合索引呢?在讨论这个之前,先来看一下联合索引内部的结果。从本质上来说,联合索引还是一棵B+树,不同的是联合索引的键值数量不是1,而是大于等于2。我们来讨论由两个整型列组成的联合索引,假定两个键值的名称分别为a、b,如图9-22所示。
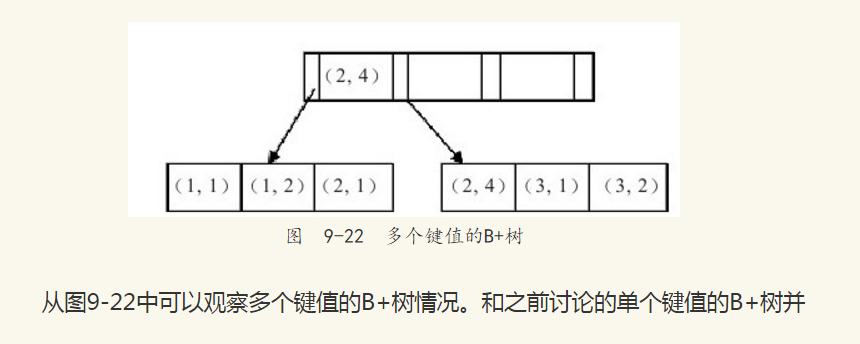
没有什么不同,键值都是排序的,通过叶子节点可以逻辑上顺序地读出所有数据,这里是:(1,1),(1,2),(2,1),(2,4),(3,1),(3,2)。数据按(a, b)的顺序进行了存放。
因此,对于查询SELECT*FROM TABLE WHERE a=xxx and b=xxx,显然是可以使用(a, b)这个联合索引的。对于单个的a列查询SELECT*FROM TABLE WHERE a=xxx也可以使用这个(a, b)索引。但是对于b列的查询SELECT*FROM TABLE WHERE b=xxx,不可以使用这棵B+树索引。可以看到叶子节点上的b值为1、2、1、4、1、2,显然不是顺序的,因此对于b列的查询不能使用(a, b)的索引。
联合索引的另一个好处是可以对第二个键值进行排序。例如,在很多情况下我们都需要查询某个用户的购物情况,并按照时间排序,取出最近三次的购买记录,这时使用联合索引可以减少一次排序操作,因为索引本身在叶子节点已经排序了。来看一个例子,先根据如下语句来创建测试表buy_log。

userid索引和(userid, buy_date)联合索引。优化器最终的选择是userid,因为该叶子节点包含单个键值,所以一个页能存放的记录应该更多。
接着假定要取出userid为1的最近3次的购买记录,其SQL语句如下,执行计划如图9-24所示。
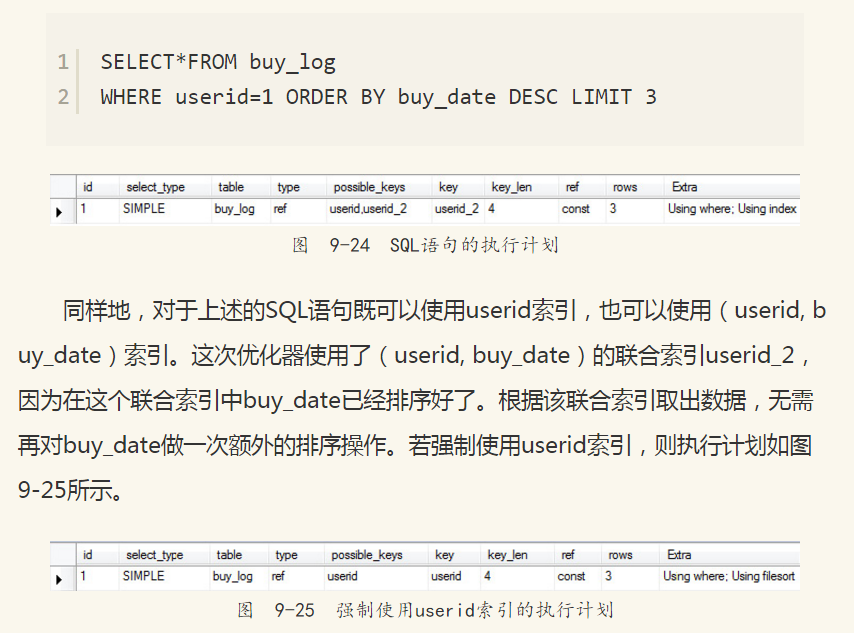
在Extra列可以看到Using filesort,即需要额外的一次排序才能完成查询。而这次需要排序的显然是buy_date,因为索引userid中的buy-date是未排序的。
9.6.3 覆盖索引
InnoDB存储引擎支持覆盖索引(covering index),或称索引覆盖(index coverage),即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。使用覆盖索引的好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。
注意:覆盖索引技术最早在InnoDB Plugin中完成并实现。这意味着对于InnoDB版本小于1.0的,或者MySQL数据库版本为5.0或以下的,InnoDB存储引擎不支持覆盖索引特性。
对于InnoDB存储引擎的辅助索引而言,由于其中包含了主键信息,因此其叶子节点存放的数据为(primary key1,primary key2,……,key1,key2,……)。下面语句都可以仅使用一次辅助联合索引来完成查询。


覆盖索引的另一个好处是对于某些统计问题,辅助索引小于聚集索引,可以减少IO操作。还是通过上一小节创建的表buy_log进行说明,如果要进行如下的查询:

这时InnoDB存储引擎并不会选择通过查询聚集索引来进行统计,因为该表上还有辅助索引,同样的理由,因为辅助索引小于聚集索引,可以减少IO操作,故优化器的选择如图9-26所示。
通过图9-26可以看到,possible_keys列为NULL,但是实际执行时优化器却选择了userid索引,而Extra列的Using index就是代表了优化器进行了覆盖索引操作。

从图9-27可以发现,possible_keys列依然为NULL,但是key列为userid_2,即表示(userid, buy_date)的联合索引。从Extra列同样可以发现Using index提示,表示为覆盖索引。
9.6.4 优化器选择不使用索引的情况
在某些情况下,当执行EXPLAIN时,会发现优化器并没有选择索引去查找数据,而是通过扫描聚集索引,也就是直接进行全表的扫描来得到数据。这种情况多发生于范围查找、JOIN操作等,例如:
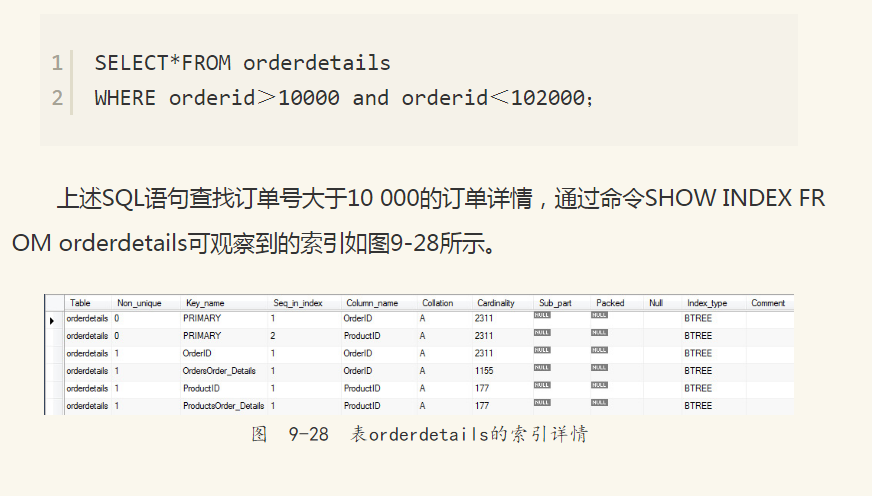
可以看到表orderdetails有(OrderID, ProductID)的联合主键,此外还有对列OrderID的单个索引。这句SQL显然是可以通过OrderID来查找数据的。然而通过EXPLAIN命令,会发现优化器并没有按照OrderID上的索引来查找数据,如图9-29所示。

在possible_keys列可以看到查询可以使用PRIMARY、OrderID、OrdersOrder_Details三个索引,但是在最后的索引中,优化器选择了PRIMARY聚集索引,而非OrderID辅助索引。
这是为什么呢?原因在于我们要选取的数据是整行信息,而OrderID索引不能覆盖到我们要查询的信息,因此在对OrderID索引进行查询到指定数据的操作后,还需要进行一次书签访问来查找整行数据的信息。虽然在OrderID的索引中数据是顺序存放的,但是再一次的书签查找数据是无序的,因此变为了磁盘上的离散读取操作。如果要求访问的数据量很小,那么优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的很大一部分时(一般是20%左右),优化器会选择通过聚集索引来查找数据。在9.1节中已经提到顺序读取要远远快于离散读取。图9-30演示的是用sysbench测试的顺序读取和随机读取的速度对比,同时对比了RAID开启Write Back和Write Through的性能差异。测试的磁盘是由4块15 000转的硬盘组成的RAID10。测试文件大小为2GB,页大小64KB。
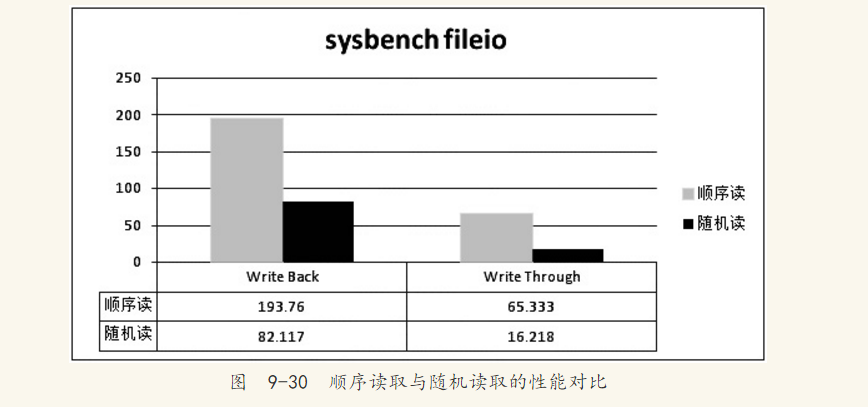
从图9-30可以发现,不管是否开启RAID卡的Write Back功能,磁盘的随机读取性能都远远小于顺序读取的性能。通过图9-30的比较也大致可以知道Write Back相对于Write Through的性能提升。
因此对于不能进行索引覆盖的情况,优化器选择辅助索引的情况是,通过辅助索引查找的数据是少量的,这是由当前传统机械硬盘的特性所决定,即利用顺序读取来替换随机读取的查找。若用户使用的磁盘是固态硬盘,随机读取操作非常快,同时有足够的自信来确认使用辅助索引可以带来更好的性能,那么可以使用关键字FORCE INDEX来强制使用某个索引,例如:
9.6.5 INDEX HINT
MySQL数据库支持INDEX HINT(索引提示),显式地告诉优化器使用哪个索引。以下两种情况可能需要用到INDEX HINT。
MySQL数据库的优化器错误地选择了某个索引,导致SQL语句运行得很慢。这种情况非常少见。优化器在绝大部分情况下工作都非常有效和正确。这时有经验的DBA或开发人员可以强制优化器使用某个索引,以达到提高SQL运行速度的目的。
某SQL语句可以选择的索引非常多,这时优化器选择执行计划时间的开销可能会大于SQL语句本身。例如,优化器分析Range查询本身就是比较耗时的操作,这时DBA或开发人员分析最优的索引选择,通过INDEX HINT来强制使优化器不进行各个执行路径的成本分析,直接执行选择指定的索引来完成查询。
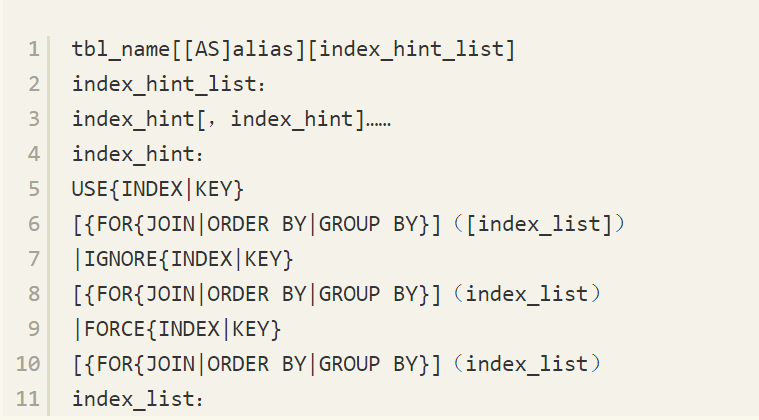
在MySQL数据库中INDEX HINT的语法如下:


9.7 Multi-Range Read
MySQL数据库5.6版本开始支持Multi-Range Read(MRR)优化。MRR优化的目的就是减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,可为IO-bound类型的SQL查询语句带来性能的极大提升。MRR优化适用于range、ref和eq_ref类型的查询。
MRR优化有以下几个好处:
使得数据访问变得较为顺序。在查询辅助索引时,先对得到的查询结果按照主键进行排序,并按照主键排列的顺序进行书签查找。
减少缓冲池中页被替换的次数。
批量处理对键值的查询操作。
对于InnoDB和MyISAM存储引擎的范围查询和联接查询,MRR的工作方式如下:将查询得到的辅助索引键值存放于一个缓存中,这时缓存中的数据是根据辅助索引键值排序的。
将缓存中的键值根据RowID进行排序。
根据RowID的排序顺序来访问实际的数据文件。
此外,若InnoDB存储引擎或MyISAM存储引擎的缓冲池不是足够大,即不能存放下一张表中的所有数据,此时频繁的离散读取操作还会导致将缓存中的页替换出缓冲池,然后又不断地读入缓冲池。若按照主键顺序进行访问,则可以将重复行为的次数降为最低。例如下面的SQL语句:

salary上有一个辅助索引idx_s,因此除了通过辅助索引查找键值外,还需要通过书签查找来进行对整行数据的查询。当不启用MRR特性,看到的执行计划如图9-35所示。

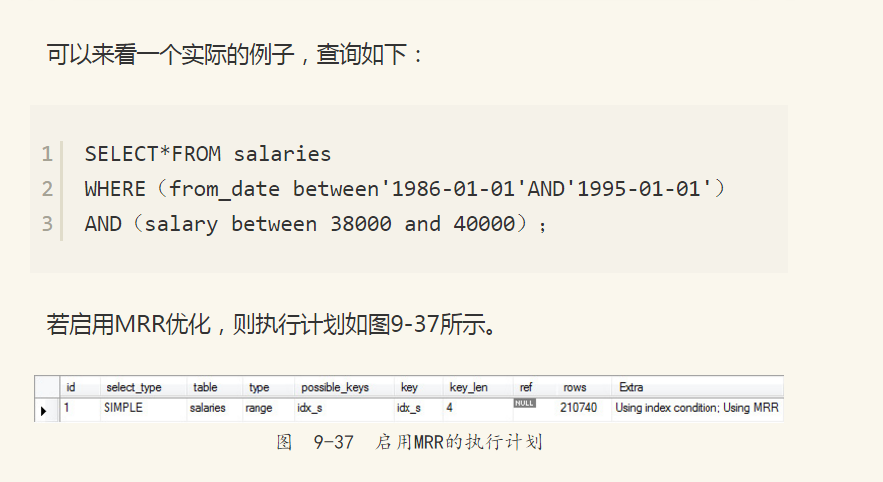
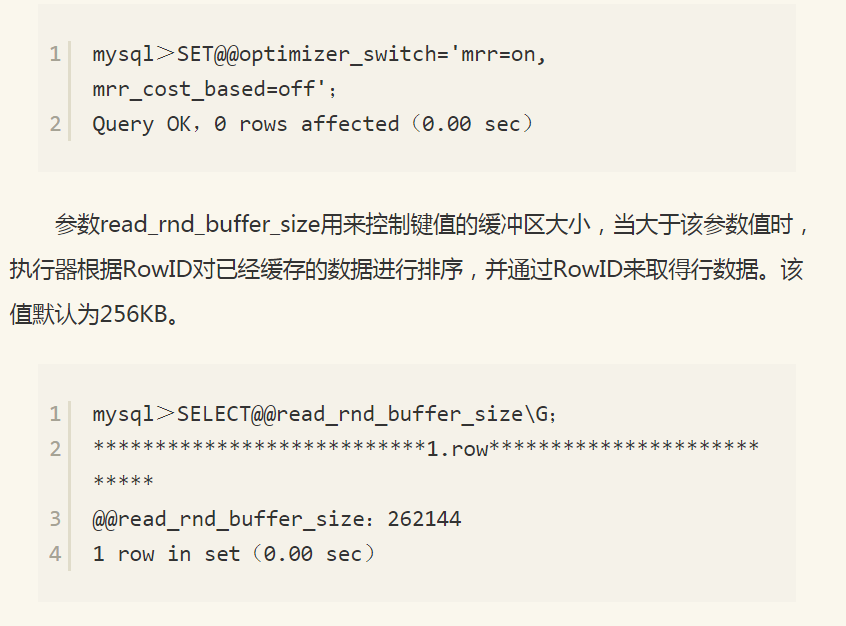
从图9-37中可以看出表salaries上有对salary的索引idx_s。在执行上述SQL语句时,因为启用了MRR优化,所以会对查询条件进行拆分,在Extra列中可以看到Using MRR选项。是否启用MRR优化可以通过参数optimizer_switch中的标记(flag)来控制。当启用mrr为on时,表示启用MRR优化。mrr_cost_based标记表示是否通过cost based的方式来选择是否启用mrr。若将mrr设为on, mrr_cost_based设为off,则总是启用MRR优化。下面的语句可以将MRR优化总是设为开启状态。
9.8 Index Condition Pushdown
和MRR一样,Index Condition Pushdown(ICP)同样是MySQL 5.6开始支持的一种根据索引进行查询的优化方式。之前的MySQL版本不支持ICP,当进行索引查询时,首先根据索引来查找记录,然后再根据WHERE条件来过滤记录。在支持ICP后,MySQL数据库会在取出索引的同时,判断是否可以进行WHERE条件的过滤,即将WHERE的部分过滤操作放在了存储引擎层。在某些查询中,ICP会大大减少上层SQL层对于记录的索取(fetch),从而提高数据库的整体性能。
ICP优化支持range、ref、eq_ref和ref_or_null类型的查询,当前支持MyISAM和InnoDB存储引擎。当优化器选择ICP优化时,可在执行计划的Extra列看到Using index condition提示。
注意 NDB Cluster存储引擎支持Engine Condition Pushdown优化。不仅支持索引的Condition Pushdown,也可以支持非索引的Condition Pushdown,不过这是由其引擎本身的特性所决定的。MySQL 5.1版本NDB Cluster存储引擎就开始支持Engine Condition Pushdown优化。
假设某张表中有联合索引(zip_code, last_name, firset_name),并且查询语句如下:


对于上述语句,MySQL数据库可以通过索引来定位zipcode等于95 054的记录,但是索引对WHERE条件的lastname LIKE'%etrunia%'AND address LIKE'%Main Street%'没有任何的帮助。若不支持ICP优化,则数据库需要先通过索引取出所有zipcode等于95 054的记录,然后再过滤WHERE之后的两个条件。
若支持ICP优化,则在取出索引时,就会进行WHERE条件的过滤,然后再去获取记录,这将极大提高查询的效率。当然,WHERE可以过滤的条件是该索引可以覆盖到的范围。再来看上一节中的SQL语句:

若不启用MRR优化,则其执行计划如图9-38所示。
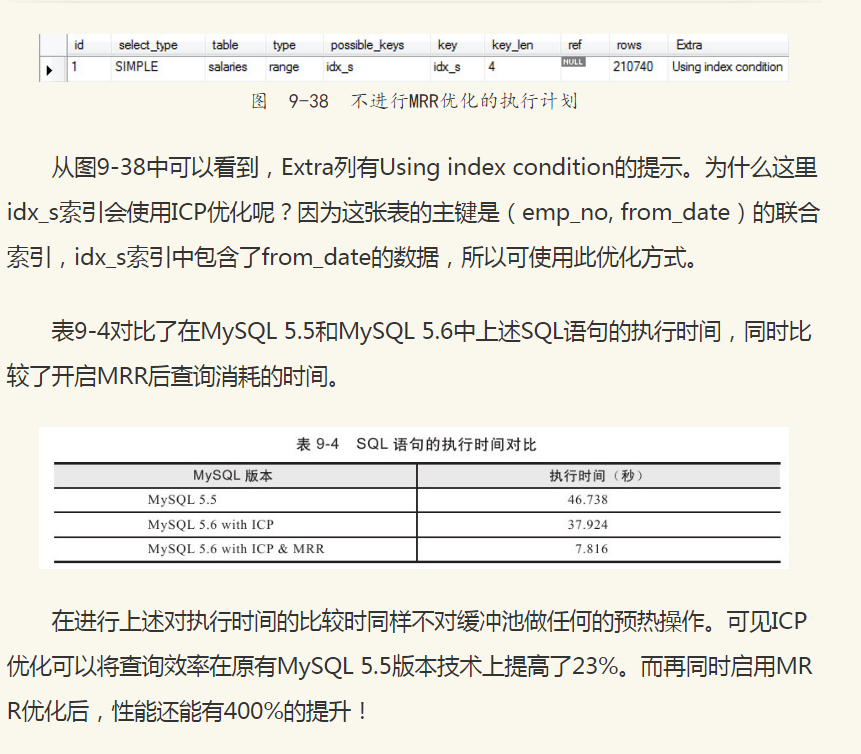
总结:总体来说,5.5可以升级到5.6玩下MRR优化了!sql语句逇执行时间提高百分之400,尼玛什么概念~。
MRR 仅仅针对 二级索引 的范围扫描 和 使用二级索引进行 join 的情况。
MRR 的优势是将多个随机IO转换成较少数量的顺序IO。所以对于 SSD 来说价值还是有的,但是相比机械磁盘来说意义小一些。
9.9 T树索引
9.9.1 T树概述
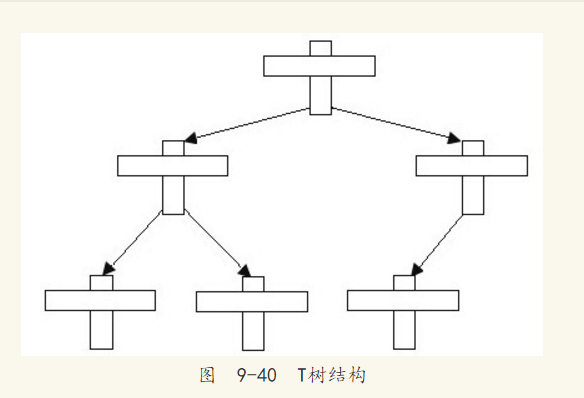
对于MySQL数据库的NDB Cluster内存存储引擎,在使用它时可将其视为内存数据库(从MySQL 5.1开始NDB Cluster引擎可以将非索引数据存放在磁盘上,这种情况又可以视为混合存储引擎)。在内存数据库中,一般使用T树(T-Tree)作为其索引的数据结构。T树是由平衡二叉树和B树发展而来。NDB Cluster存储引擎中的Order Index,也就是普通索引,使用的就是T树结构。T树的好处是节点不存放数据,只存放指针,这样能减少对内存的使用,这对内存数据库来说显得尤为重要。同时T树也是一棵平衡二叉树,以此保证查找的性能。T树中的T指的是T树中节点的形状。图9-39显示了T树节点(T-tree node)。
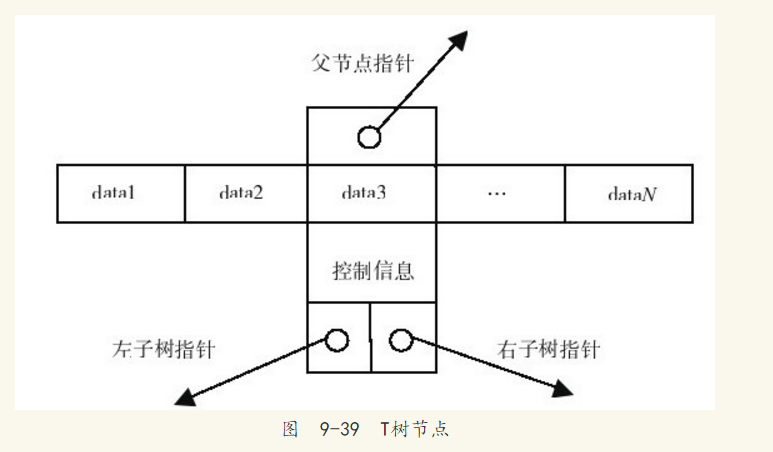
T树节点由3个指针、一个有序数组(array),以及控制信息组成。3个指针分别为指向父节点和左右子树的指针。有序数组保存的是数据指针,而非实际的数据。数组中的第一个数据称为最小元素(minimum element),最后一个数据称为最大元素(maximum element)。控制信息中存放了关于该T树节点的一些额外信息。T树的结构如图9-40所示。
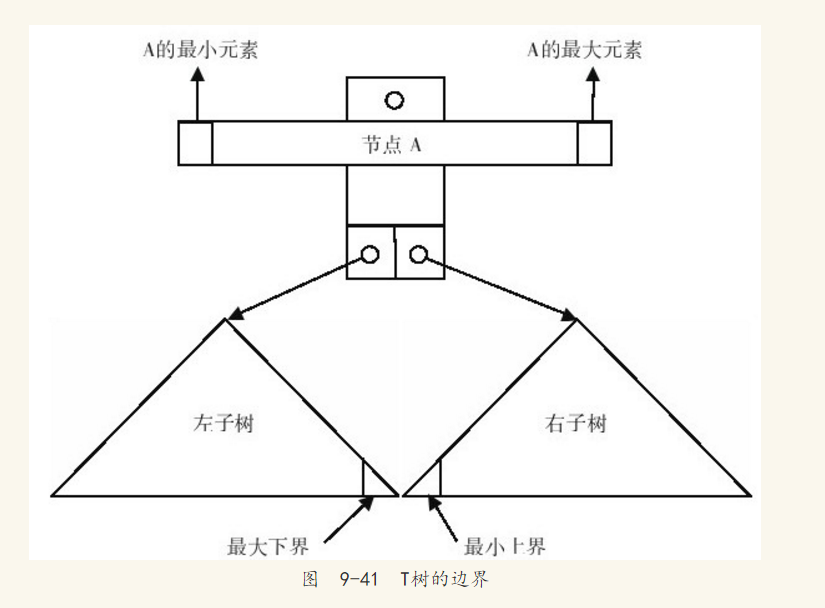
在T树中,含有左右子树的节点称为内部节点(internal node),没有子树的节点称为叶节点(leaf node),仅有一个子树的节点称为半叶节点(half-leaf node)。对于每个内部节点,存在一个相对应的叶节点或半叶节点存放内部节点的最小值,该值称为最大下界(greatest lower bound)。同时也存在相对应的叶节点或半叶节点用于存放内部节点的最大值,该值称为最小上界(least upper bound),如图9-41所示。如果一个值x在T树的节点N上,那么称x在N的边界内,N为x的边界页。通过上述的内容,可以看出T树的节点借鉴了B树和平衡二叉树的思想。
9.9.2 T树的查找、插入和删除操作
T树的查找和二叉查找树类似,其查找算法为:
从根节点(root)开始查找,比较节点中最大值和最小值。如果查找的值在边界内,则用二叉法查找T树中的数组。
若查找的值比根节点的最小值小,则递归查找左子树。
若查找的值比根节点的最大值大,则递归查找右子树。
若不存在该值,返回为NULL。
T树的插入操作:先通过查找来定位边界页,新插入的值被插入边界页后需要对T树进行检查,看其是否平衡。如果不平衡,则需要通过旋转来保证T树的平衡。由于T树的节点可以存放多个值,因此其旋转的次数,较之平衡二叉树又减少了很多。
T树的插入算法为:
查找边界页。
如果查到边界页,则判断是否有空间插入新的值。如果有,则直接插入,插入操作完成。如果没有空间,则删除该节点的最小值,插入新值。接着查询原插入值最大下界所在的节点,将删除的值插入该节点,并成为新的最大下界值。
如果没有查到边界页,那么在最后查询的节点中尝试插入记录。若该节点有空间可以插入,则直接插入,并且该记录成为该节点的最小或最大记录值。若没有空间插入,则分配一个叶节点进行插入。
如果分配了一个叶节点,则需要检查T树是否平衡。如果不平衡,即子树高度的差值大于1,则需要进行与平衡二叉树同样的旋转操作,以保证T树重新回到平衡状态。当T树恢复到平衡状态,此次操作完成。
T树的删除操作同插入操作类似,首先需要找到边界页,然后完成删除操作,最后判断是否需要旋转来完成平衡操作。其具体步骤如下:
查找删除记录所在的边界页。如果查找失败,则报告错误并停止操作。
如果删除不会引起下溢出(underflow)问题,即删除该记录后,节点中的记录数大于所要求该节点的最小记录数,那么直接删除记录。否则,如果节点是内部节点,那么删除该记录,同时将该节点的最大下界值放回该内部节点中。如果节点是叶节点或半叶节点,则直接删除记录(叶节点允许下溢出,半叶节点还需进行下一步操作)。
如果是半叶节点,则观察半叶节点是否可以和叶节点进行合并(merge)。如果可以,则强制将两个节点合并为一个节点,并删除半叶节点。
观察删除后的节点是否是空节点,若是则删除该节点。
观察T树是否平衡,若不平衡则通过旋转操作使T树重新回到平衡状态。
9.9.3 T树的旋转
T树的旋转操作和平衡二叉树十分相似。当插入或进行触发叶的添加或删除操作时,需要重新检查树是否平衡,需要判断是否通过旋转操作来使T树重新变为平衡。检查的路径为插入的节点到根节点所有的路径,观察左右子树的高度差值是否大于1。若是,则需要执行旋转操作。对于插入操作,只需要进行一次旋转操作;对于删除操作,可能需要多次的旋转操作。图9-42显示了插入操作所触发的LL旋转和较为复杂的LR旋转操作。和平衡二叉树一样,共有四种类型的旋转,分为LL、LR、RR、RL。其中RR、RL和LL、LR是对称的,这里不进行讨论。删除操作与插入操作一样,但是,删除操作使子树的高度变矮,而不是像插入操作一样使子树变高。
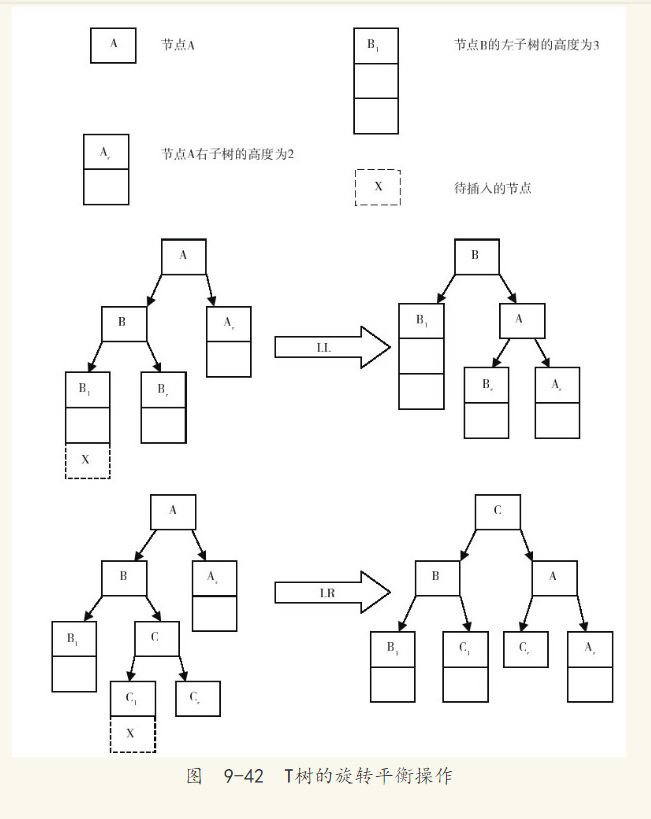
T树存在一种特殊的旋转,这是平衡二叉树所不存在的一种平衡操作。当LR或RL旋转操作完成后,如果节点C是叶节点,并且A、B节点都是半叶节点,那么通常的旋转平衡操作会将C节点变成一个内部节点,如图9-43所示。
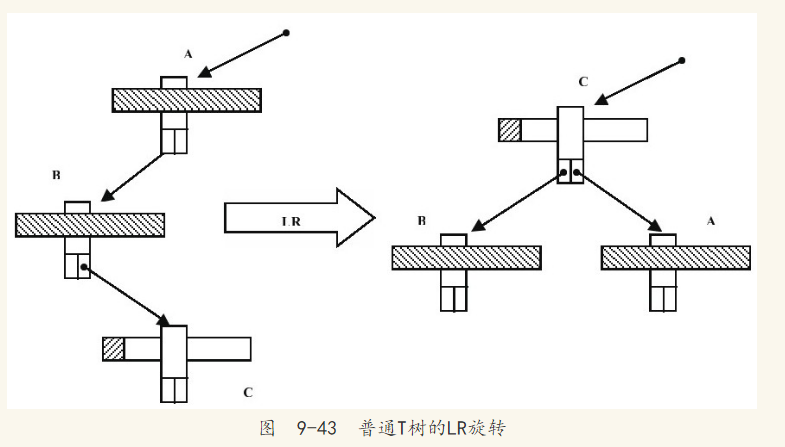
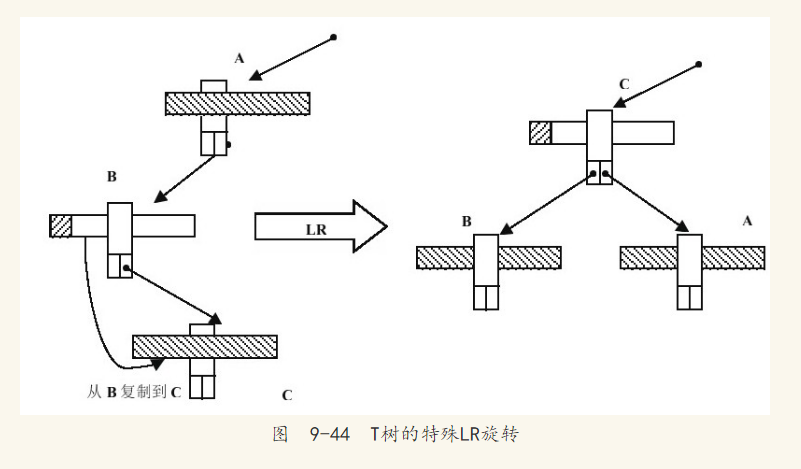
因为数据的插入总是在内部节点的最大和最小边界范围中,所以当节点C只包含一个数据时,任何数据都不会插入C节点,除非C节点通过旋转再次变为叶节点或半叶节点。这种情况会极大浪费存储空间,尤其对内存存储引擎来说。因此,在T树中有一种特殊的旋转操作,它会将节点B中的数据移动到节点C中,节点C变成满的内部节点,这个操作如图9-44所示
9.10 哈希索引
当前MySQL数据库中,Memory存储引擎支持哈希索引。InnoDB存储引擎支持自适应哈希索引,用户仅能开启该特性,不能对其进行人工干预。散列算法是一种常见算法,时间复杂度为O(1),并且不只存在于索引中,每个数据库应用中都存在该数据库结构。设想这样一个问题,当前服务器的内存为128GB,用户怎样从内存中得到某一个被缓存的页呢?内存中的查询速度很快,但是也不可能每次遍历所有内存进行查找。这时对于字典操作只需O(1)复杂度的散列算法,就能有很好的用武之处。
9.10.1 散列表
散列表(hash table)由直接寻址表改进而来。先来看直接寻址表。当关键字的全域U比较小时,直接寻址是一种简单而有效的技术。假设某应用要用到一个动态集合,其中每个元素都有一个取自全域U={0,1,……,m-1}[注释]的关键字,同时假设没有两个元素具有相同的关键字。
用一个数组(即直接寻址表)T[0..m-1]表示动态集合,其中每个位置(称槽或桶)对应全域U中的一个关键字。如图9-45所示,槽K指向集合中一个关键字为K的元素。如果该集合中没有关键字为K的元素,则T[K]=NULL。
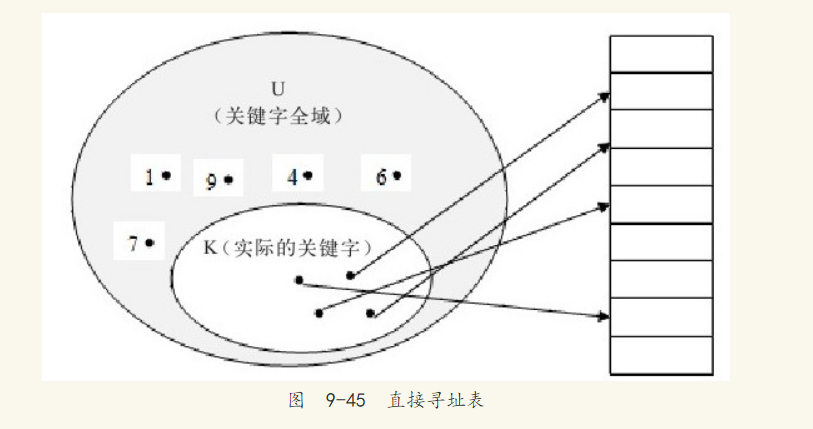
直接寻址技术存在一个很明显的问题,如果全域U很大,在一台典型计算机的可用内存容量限制下,要存储大小为U的一张表T有点不实际,甚至是不可能的。如果实际要存储的关键字集合K相对于U来说可能很小,那么分配给T的大部分空间都要浪费掉。
因此,散列表的数据结构出现了。在散列方式下,该元素处于h(K)中,即利用散列函数h,根据关键字K计算出槽的位置。函数h将关键字全域U映射到散列表T[0..m-1]的槽位上,如图9-46所示。
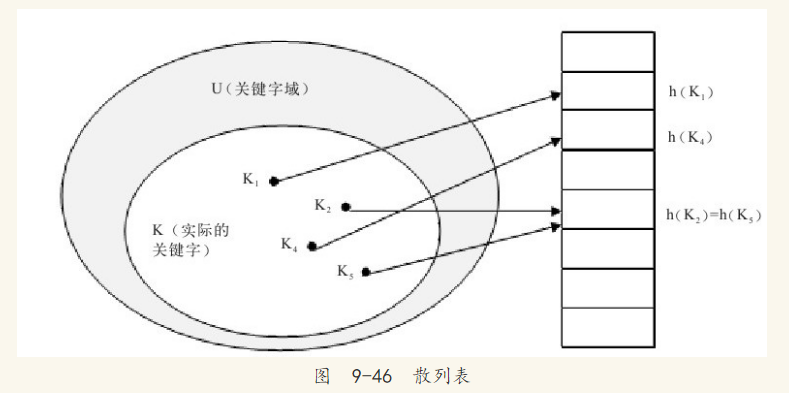
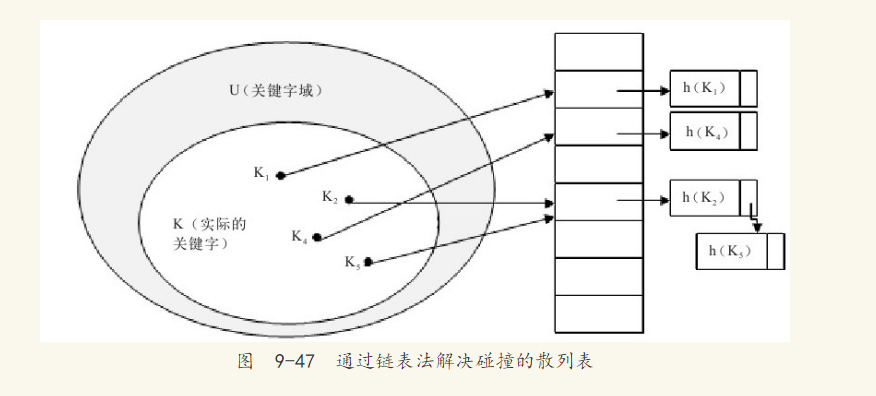
散列表很好地解决了直接寻址遇到的问题,但是这样做有一个小问题,如图9-46所示,两个关键字可能映射到同一个槽上。一般将这种情况称为发生了碰撞(collision)。数据库中一般采用最简单的碰撞解决技术,即链接法(chaining)。
在链接法中,把散列到同一槽中的所有元素都放在一个链表中,如图9-47所示。每个槽中有一个指针,它指向由所有散列元素构成的链表的头,如果不存在这样的元素,则为NULL。
最后要考虑的是散列函数。散列函数h必须可以很好地进行散列。最好的情况是能避免碰撞的发生,即使不能避免,也应该使碰撞在最小程度下产生。一般都将关键字转换成自然数,然后通过除法散列、乘法散列或全域散列来实现。数据库中一般采用除法散列的方法。
[1]此处的m不是一个很大的数。
9.10.2 InnoDB存储引擎中的散列算法
InnoDB存储引擎使用散列算法来对字典进行查找,其冲突机制采用链表方式,散列函数采用除法散列方式。对于缓冲池页的散列表来说,缓冲池中的Page页都有一个chain指针,它指向相同散列函数值的页。而对于除法散列,m的取值为略大于2倍的缓冲池页数量的质数。例如,当前参数innodb_buffer_pool_size的大小为10MB,则共有640个16KB的页,对于缓冲池页内存的散列表来说,需要分配640*2=1280个槽,而1280不是质数,因此需要取比1280略大的一个质数,应该是1399,这样在启动时会分配1399个槽的散列表,用来散列查询所在缓冲池中的页。
那么InnoDB存储引擎对于页是怎么进行查找的呢?上面只是给出了一般的算法,怎么将要查找的页转换成自然数呢?其实也很简单,InnoDB存储引擎的表空间都有一个space号,我们要查找的应该是某个表空间的某个连续16KB的页,即偏移量offset。InnoDB存储引擎将space左移20位,然后加上这个space和offset,即关键字K=space<<20+space+offset,然后通过除法散列到各个槽中去。
9.10.3 自适应哈希索引
自适应哈希索引采用之前讨论的散列表的方式实现。不同的是,自适应哈希索引仅是数据库自身创建并使用的,DBA本身并不能对其进行干预。自适应哈希索引经散列函数映射到一个散列表中,因此对于字典类型的查找非常快速,例如SELECT*FROM TABLE WHERE index_col='xxx',但是对于范围查找就无能为力了。通过命令SHOW ENGINE INNODB STATUS可以看到当前自适应哈希索引的使用状况,例如:

现在可以看到自适应哈希索引的使用信息,包括自适应哈希索引的大小、使用情况、每秒使用自适应哈希索引搜索的情况。需要注意的是,哈希索引只能用来搜索等值的查询,例如select*from table where index_col='xxx',而对于其他查找类型,比如范围查找,是不能使用哈希索引的,因此,这里出现了non-hash searches/s的情况。由hash searches:non-hash searches可以大概了解使用哈希索引后的效率。
由于自适应哈希索引是由InnoDB存储引擎自己控制的,所以这些信息只供我们参考。不过可以通过参数innodb_adaptive_hash_index来禁用或启动此特性,默认为开启。
9.11 小结
本章更倾向于从内部的实现来分析索引,较之前的章节在风格上有很大的不同。这样处理是为了使读者更好地理解数据库中索引的实现,特别是B+树索引。通过这种方式,用户才能进行高质量的SQL编程,写出高质量的应用程序。
参考:Mysql技术内幕SQL编程
MySQL索引使用方法和性能优化:http://feiyan.info/16.html
MySQL索引原理及慢查询优化:http://tech.meituan.com/mysql-index.html

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

