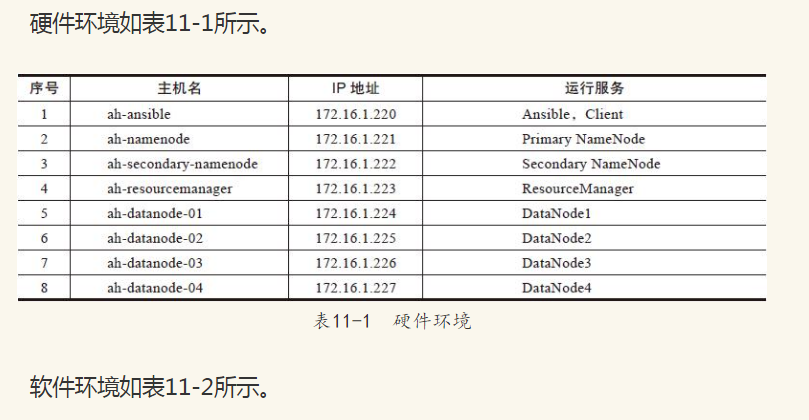
第五章 大数据环境的应用实战
随着云时代的到来,大数据也吸引了越来越多的关注。大数据不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理,即在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。大数据的价值体现在以下方面:
·对大量消费者提供产品或服务的企业,可以利用大数据进行精准营销。
·做小而美模式的中长尾企业,可以利用大数据做服务转型。
·面临互联网压力之下必须转型的传统企业,需要与时俱进充分利用大数据的价值。
大数据与云计算就像一枚硬币的正反面一样密不可分。大数据必然需要采用分布式架构,对海量数据进行分布式数据挖掘,涌现出了大量创新、适用于大数据的技术,包括大规模并行处理(MPP)数据库、数据挖掘电网、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统等。实时的大型数据集分析需要像MapReduce这样的框架来向数十、数百或甚至数千台主机分配任务,并在容忍时长内有效地处理、输出分析结果,这需要支撑数据处理的海量资源环境能够高度动态自动伸缩调整。
对于这种大规模的应用场景特别需要有自动化运维支撑手段,本章将结合某运营商大数据环境,介绍如何采用Ansible进行维护管理。
有些读者可能已经在使用Hadoop服务了,甚至也已经做了大量的日常维护操作,对于这些读者阅读本章仍然有助于深入理解如何维护大规模Hadoop集群。
5.1 某运营商大数据环境
某运营商拥有大量数据资源,有BSS、OSS、MSS数据,有DPI、信令、位置等网络和网管数据,有电信增值业务、行业和公众客户应用数据,有终端、渠道、支付和客服等数据,涵盖参与人、产品、财务、市场营销、事件、地域、资源和账务等类数据。对这几类数据进行加工处理、分析挖掘,对数据进行脱敏处理后,构建数据应用和产品,形成有价值的信息增值。对运营商内部提供面向企业内部的客户行为和消费特征的分析挖掘,实现精确营销、精准维系、效益评价等数据应用业务需求;对合作伙伴通过数据出售、数据咨询、数据能力和数据解决方案四种业务形态实现数据资产的数据运营,最终实现数据资产的增值。
因此统一建设大数据能力产品与应用平台,支持平台、数据对外开放和集约管理,为运营商内外提供大数据服务能力和大数据应用,提供统一能力开发接口、数据产品服务能力封装、数据平台能力封装、资源管理、平台管控等服务,提供RTB、精准营销、保险反欺诈、选址分析等大数据产品应用。内容主要包括:
·数据仓储和分析能力:包括基础数据导入、数据访问、数据处理的能力,数据采集和汇总,网络爬虫和规则库管理。
·数据服务能力组件封装:基于大数据基础数据分析能力,针对不同业务产品特点封装形成数据服务能力组件,包括关键词分析组件、客户识别组件、标签产品组件、行为分析组件等。
·服务能力统一开放:在数据服务能力组件基础上,对外提供服务能力开放,并对服务过程进行统一管理,包括接入与签权、服务控制、安全管理等。
·数据管控:包括数据质量管理、数据规则管理、元数据管理等。
·平台管控与系统管理:对基础计算/存储资源管理、服务能力管理、任务和进程调度管理、安全管理、系统管理等。
根据业务需求对整个大数据能力平台进行设计,共分8大功能区,包括数据接入区(FTP服务)、数据汇聚总线(Kafka、FTP)、数据生产加工区(数据存储、计算、封装)、数据分析区(结构化、非结构化数据)、预上线测试区(中间过程)、服务门户区(产品服务、管理服务、数据接口)、运维服务区(运维管理、ETL服务、集群应用客户端、堡垒审计),如图11-1所示。

整个大数据平台系统涵盖了数据采集、导入和预处理、统计和分析、数据展现一系列过程。Hadoop已经是对大数据集进行分布式计算的标准工具,具有完整、充满活力的开源生态环境。构建整个大数据环境涉及部署Hadoop集群、HBase、Hive、MySQL、Nginx、Redis、Kafka、Flume、Zookeeper、Storm、Ganglia等软件。
下面将详细讲解如何用Ansible准备Hadoop集群基础环境、集群软件部署配置等。
5.2 准备大数据集群环境
目前在国内主流的Hadoop有Apache Hadoop(最原始的、所有发行版均基于这个版本进行改进)、Cloudera CDH(Cloudera’s Distribution Hadoop)、Hortonworks HDP(Hortonworks Data Platform)。对于初学者或小规模应用大多选择CDH版本,与Apache发行版本相比,CDH具有如下优点:
1)CDH对比Hadoop版本的划分非常清晰,当前主要有CDH4、CDH5,分别对应原生Hadoop 2.0、Hadoop 2.3。原生的Apache Hadoop版本则比较混乱,在兼容性、安全性、稳定性上也需要大量额外的增强。
2)当前CDH5版本是基于Apache Hadoop 2.3改进的,融入了最新的软件补丁,CDH总能及时跟进最新的Bug补丁、新功能组件,比Apache Hadoop同功能版本提早发布,更新也较快。
3)CDH增强了安全认证,支持Kerberos,Apache Hadoop只是使用用户名匹配认证。
4)特别是CDH支持Yum/Apt包、Tar包等多种安装方式。适用于各种操作系统,建议直接用Yum/Apt安装,能够自动匹配安装版本、下载安装依赖软件,升级非常方便。
下面将详细介绍基于CDH5的Ansible自动化部署过程,包括操作系统基础环境、Hadoop基础环境、Hadoop集群部署的详细过程。

参照Ansible最佳实践建议,整个配置管理主要包含在以下3个目录:
·group_vars:全局定义的变量参数。
·playbooks:下面又分为:conf(环境配置)、operation(日常维护)两个目录的脚本。
·roles:包含各个服务的角色,每个角色一般包含defaults、vars、files、tasks、handlers等目录。
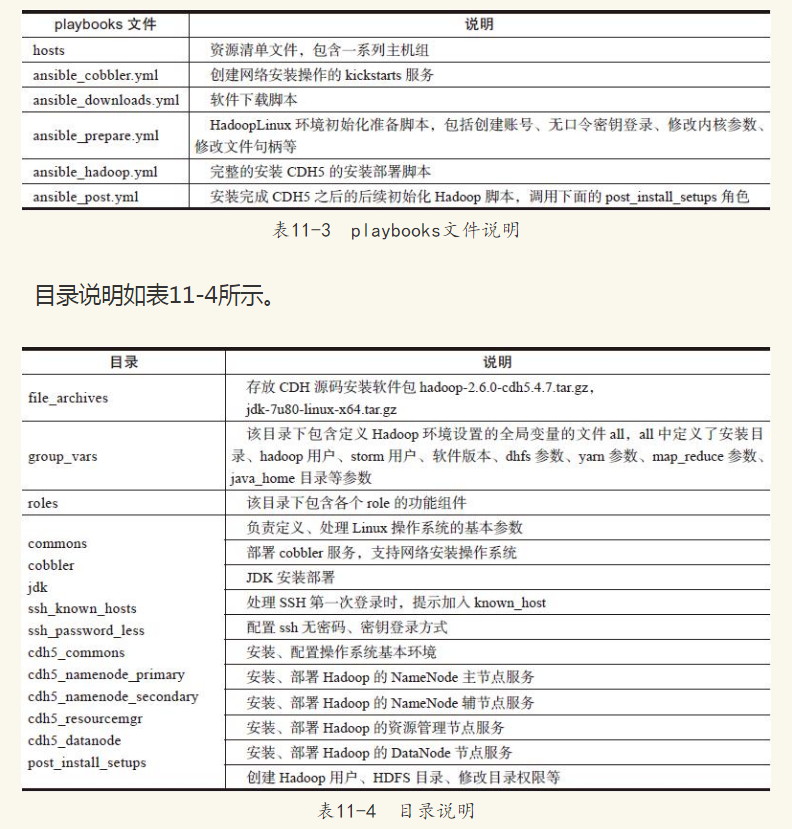
playbooks文件见表11-3。
如果有多个Hadoop集群环境,如有生产集群、测试集群等,可以分别定义,分开管理。也可以定义多个资源清单文件来表示各个集群环境,这样也方便由ansible-playbook指定不同的集群环境进行操作。
5.2.1 安装操作系统
对于Hadoop环境,有大量的主机需要初始化安装操作系统,Cobbler是无需进行人工干预即可安装操作系统的理想选择。Cobbler设置一个PXE引导环境,并控制与安装相关的所有方面。Cobbler功能如下:
·使用一个以前定义的模板来配置DHCP服务(如果启用了管理DHCP)。
·将在一个存储库(yum或rsync)建立镜像,以注册一个新操作系统。
·在DHCP配置文件中为需要安装的服务器创建一个条目,并使用您指定的参数(IP和MAC地址)。
·在TFTF服务目录下创建适当的PXE文件。
·重新启动DHCP服务以反映更改。
Cobbler支持众多的发行版:Red Hat、Fedora、CentOS、Debian、Ubuntu和SuSE。下面介绍Ansible如何编写自动化脚本来部署一个完整的Cobbler环境,主要脚本及其实现功能见表11-5。

1.Cobbler资源清单文件
在资源清单文件hosts中配置[cobbler]主机组,下面包含需要部署Cobbler的主机:
[cobbler] cobbler
2.cobbler.yml
是playbook程序执行的入口,将会调用cobbler/tasks/main.yml文件:
--- - hosts: cobbler user: root sudo: yes vars_files: - group_vars/cobbler.yml tasks: - include: cobbler/tasks/main.yml handlers: - include: common/handlers/cobbler.yml - include: cobbler/handlers/main.yml
3.cobbler/tasks/main.yml
该脚本包含Cobbler及其依赖软件包的安装,然后启动tftp、分发Cobbler模板文件、拷贝kickstarts模板文件,最后确保tftp、dhcp、obblerd、xinetd、httpd等服务在运行着:
--- - name: Install Cobbler yum: name=$item state=installed with_items: - cobbler - cobbler-web - xinetd - tftp - pykickstart - httpd - dhcp - syslinux - name: Enable tftp lineinfile: dest=/etc/xinetd.d/tftp regexp=^disable= line=disable=no notify: Restart service xinetd tags: - services - xinetd - name: Cobbler templates template: src=cobbler/templates/etc/cobbler/$item dest=/etc/cobbler/ owner=root group=root with_items: - dhcp.template - modules.conf - settings notify: - Sync cobbler - Restart service cobblerd tags: - templates - name: Cobbler kickstart script copy: src=cobbler/files/var/lib/cobbler/kickstarts/cluster.ks dest= /var/lib/cobbler/kickstarts/ owner=root group=root - name: Enable and Start Services service: name=$item state=started enabled=yes with_items: - cobblerd - xinetd - httpd tags: - services - name: Enable dhcpd Services service: name=dhcpd enabled=yes notify: - Sync cobbler - Restart service cobblerd tags: - services
4.var/cobbler.yml
定义Cobbler部署主机IP地址范围参数cobbler_temporary_range,本例中为172.16.1.11~172.16.1.254。
cobbler_temporary_range: 172.16.1.11 ~ 172.16.1.254
5.2.2 操作系统初始化
要部署Hadoop,首先需要对操作系统进行初始化,每台主机节点需要配置:
·主机节点的主机名、IP地址信息需要在所有主机节点的/etc/hosts中保持一致。
·关闭SELinux服务。
·关闭IPv6选项。
·配置Linux内核参数,包括句柄数、TCP参数。
上述基础环境需要对每台主机都进行配置,对于大型的Hadoop集群架构通过手工命令操作是很费时费力的任务。
而Ansible自动化可以很容易完成这些任务。
我们做了8台服务器组的实例,但很容易扩展到数百台的Hadoop集群环境。每台主机节点安装CentOS 6.5 x64操作系统,并安装了Python和libselinux-python安装包。即使关闭selinux服务,libselinux-python的软件包也是需要安装的,当然这也可以通过Ansible进行安装。
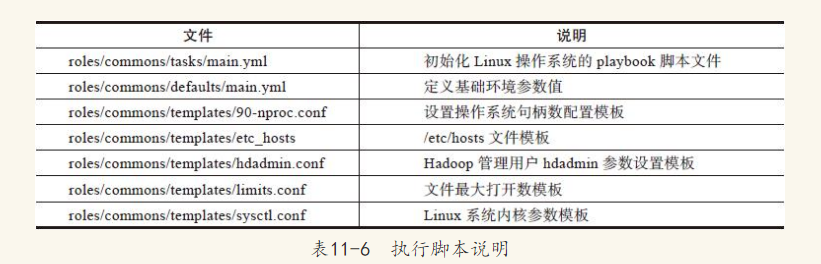
初始化Linux操作系统基础环境,我们单独编写了个角色commons,在commons角色中包含3个目录defaults、templates、task分别对应配置参数值设置、配置文件模板、playbook执行脚本,具体如表11-6所示。
1.定义环境变量参数
这些参数主要是配置系统句柄数、内存参数、TCP参数,将在模板文件中被引用,详见下面:
$cat ~/roles/commons/defaults/main.yml nproc_conf: all_user_soft_limit: 10240 all_user_hard_limit: 10240 root_user_soft_limit: unlimited # hdadmin nproc parameters. hdadmin_soft_nofile: 32768 hdadmin_soft_nproc: 65536 hdadmin_hard_nofile: 1048576 hdadmin_hard_nproc: unlimited hdadmin_hard_memlock: unlimited # limits.conf variables #limits_conf: all_user_soft_limit: 1000001 all_user_hard_limit: 1000001 # sysctl.conf variables #sysctl_conf: # vm setting vm_swappiness: 10 vm_dirty_ratio: 10 vm_min_free_kbytes: 65536 vm_max_map_count: 262144 # kernel parameter kernel_msgmnb: 100000 kernel_msgmax: 100000 # filesystem fs_file-max: 2097152 # net core parameters net_core_rmem_default: 1048576 net_core_rmem_max: 16777216 net_core_wmem_default: 1048576 net_core_wmem_max: 16777216 net_core_optmem_max: 25165824 net_core_somaxconn: 65536 net_core_netdev_max_backlog: 65536 # ipv4 Setting net_ipv4_tcp_moderate_rcvbuf: 0 net_ipv4_conf_all_rp_filter: 1 net_ipv4_tcp_slow_start_after_idle: 0 net_ipv4_tcp_fin_timeout: 10 net_ipv4_tcp_ecn: 0 net_ipv4_tcp_max_syn_backlog: 100000 net_ipv4_tcp_max_orphans: 262144 net_ipv4_tcp_max_tw_buckets: 2000000 net_ipv4_tcp_sack: 1 net_ipv4_tcp_timestamps: 1 net_ipv4_tcp_fin_timeout: 10 net_ipv4_tcp_slow_start_after_idle: 0 # Congestion Algo to use. net_ipv4_tcp_congestion_control: cubic # tcp memory net_ipv4_tcp_mem_min: 30000000 net_ipv4_tcp_mem_default: 30000000 net_ipv4_tcp_mem_max: 30000000 net_ipv4_tcp_rmem_min: 30000000 net_ipv4_tcp_rmem_default: 30000000 net_ipv4_tcp_rmem_max: 30000000 net_ipv4_tcp_wmem_min: 30000000 net_ipv4_tcp_wmem_default: 30000000 net_ipv4_tcp_wmem_max: 30000000 net_ipv4_tcp_tw_reuse: 1 net_ipv4_tcp_tw_recycle: 1 net_unix_max_dgram_qlen: 100 net_ipv4_ip_nonlocal_bind: 1 net_ipv4_tcp_synack_retries: 2 net_ipv4_tcp_syn_retries: 2
2.定义模板文件
在Linux环境中部署Hadoop,由于Hadoop有大量的连接请求,而Linux是有文件句柄限制的,默认配置不是很高,一般是1024,生产服务器很容易就达到这个数量,这将严重影响服务器的最大并发数:
$cat ~/roles/commons/templates/90-nproc.conf
* soft nproc {{ nproc_conf['all_user_soft_limit'] }}
* hard nproc {{ nproc_conf['all_user_hard_limit'] }}
root soft nproc {{ nproc_conf['root_user_soft_limit'] }}
配置每台主机的/etc/hosts文件,将根据Ansible的清单文件中配置的hosts生成,将分发到定义的所有主机节点,是的所有节点的名字解析都一样。
$cat ~/roles/commons/templates/etc_hosts
127.0.0.1 localhost
{% for host in groups['allnodes'] %}
{{ hostvars[host]['inventory_hostname'] }} {{ hostvars[host].host_name }}
{% endfor %}
设置hdadmin用户的句柄参数:
$cat ~/roles/commons/templates/hdadmin.conf
# Current below User -> 10240 and root -> max limit.
{{ hadoop_user }} soft nofile {{ nproc_conf['hdadmin_soft_nofile'] }}
{{ hadoop_user }} soft nproc {{ nproc_conf['hdadmin_soft_nproc'] }}
{{ hadoop_user }} hard nofile {{ nproc_conf['hdadmin_hard_nofile'] }}
{{ hadoop_user }} hard nproc {{ nproc_conf['hdadmin_hard_nproc'] }}
{{ hadoop_user }} hard memlock {{ nproc_conf['hdadmin_hard_memlock'] }}
设置最大文件打开数:
$cat ~/roles/commons/templates/limits.conf
# - nofile - max number of open file descriptors
* soft nofile {{ limits_conf['all_user_soft_limit'] }}
* hard nofile {{ limits_conf['all_user_hard_limit'] }}
设置主机节点的内核参数、内存参数、网络连接参数:
roles/commons/templates/sysctl.conf
net.ipv4.ip_forward = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
kernel.sysrq = 0
kernel.core_uses_pid = 1
net.ipv4.tcp_syncookies = 0
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
vm.dirty_ratio = {{ sysctl_conf['vm_dirty_ratio'] }}
vm.swappiness = {{ sysctl_conf['vm_swappiness'] }}
kernel.msgmnb = {{ sysctl_conf['kernel_msgmnb'] }}
kernel.msgmax = {{ sysctl_conf['kernel_msgmax'] }}
fs.file-max = {{ sysctl_conf['fs_file-max'] }}
net.core.rmem_default = {{ sysctl_conf['net_core_rmem_default'] }}
net.core.rmem_max = {{ sysctl_conf['net_core_rmem_max'] }}
net.core.wmem_default = {{ sysctl_conf['net_core_wmem_default'] }}
net.core.wmem_max = {{ sysctl_conf['net_core_wmem_max'] }}
net.core.optmem_max = {{ sysctl_conf['net_core_optmem_max'] }}
net.core.somaxconn = {{ sysctl_conf['net_core_somaxconn'] }}
net.core.netdev_max_backlog = {{ sysctl_conf['net_core_netdev_max_backlog'] }}
net.ipv4.tcp_moderate_rcvbuf = {{ sysctl_conf['net_ipv4_tcp_moderate_rcvbuf'] }}
net.ipv4.conf.all.rp_filter = {{ sysctl_conf['net_ipv4_conf_all_rp_filter'] }}
net.ipv4.ip_local_port_range = 4096 65535
net.ipv4.tcp_congestion_control = {{ sysctl_conf['net_ipv4_tcp_congestion_control'] }}
net.ipv4.tcp_ecn = {{ sysctl_conf['net_ipv4_tcp_ecn'] }}
net.ipv4.tcp_max_syn_backlog = {{ sysctl_conf['net_ipv4_tcp_max_syn_backlog'] }}
net.ipv4.tcp_max_orphans = {{ sysctl_conf['net_ipv4_tcp_max_orphans']}}
net.ipv4.tcp_max_tw_buckets = {{ sysctl_conf['net_ipv4_tcp_max_tw_buckets'] }}
net.ipv4.tcp_sack = {{ sysctl_conf['net_ipv4_tcp_sack'] }}
net.ipv4.tcp_timestamps = {{ sysctl_conf['net_ipv4_tcp_timestamps'] }}
net.ipv4.tcp_fin_timeout = {{ sysctl_conf['net_ipv4_tcp_fin_timeout'] }}
net.ipv4.tcp_slow_start_after_idle = {{ sysctl_conf['net_ipv4_tcp_slow_start_after_idle'] }}
net.ipv4.tcp_mem = {{ sysctl_conf['net_ipv4_tcp_mem_min'] }} {{ sysctl_conf['net_ipv4_tcp_mem_default'] }} {{ sysctl_conf['net_ipv4_tcp_mem_max'] }}
net.ipv4.tcp_rmem = {{ sysctl_conf['net_ipv4_tcp_rmem_min'] }} {{ sysctl_conf['net_ipv4_tcp_rmem_default'] }} {{ sysctl_conf['net_ipv4_tcp_rmem_max'] }}
net.ipv4.udp_rmem_min = 16384
net.ipv4.tcp_wmem = {{ sysctl_conf['net_ipv4_tcp_wmem_min'] }} {{ sysctl_conf['net_ipv4_tcp_wmem_default'] }} {{ sysctl_conf['net_ipv4_tcp_wmem_max'] }}
vm.max_map_count = {{ sysctl_conf['vm_max_map_count'] }}
net.ipv4.tcp_tw_reuse = {{ sysctl_conf['net_ipv4_tcp_tw_reuse'] }}
net.ipv4.tcp_tw_recycle= {{ sysctl_conf['net_ipv4_tcp_tw_recycle'] }}
net.unix.max_dgram_qlen = {{ sysctl_conf['net_unix_max_dgram_qlen'] }}
net.ipv4.ip_nonlocal_bind = {{ sysctl_conf['net_ipv4_ip_nonlocal_bind'] }}
net.ipv4.tcp_synack_retries = {{ sysctl_conf['net_ipv4_tcp_synack_retries'] }}
net.ipv4.tcp_syn_retries = {{ sysctl_conf['net_ipv4_tcp_syn_retries'] }}
vm.min_free_kbytes = {{ sysctl_conf['vm_min_free_kbytes'] }}
这些模板中的变量值已经在前面的参数默认值进行了设置,这里只是引用。
3.定义执行部署的playbook。
把这些模板拷贝到目被管节点上,然后进行配置:
$cat ~/roles/commons/tasks/main.yml
---
- name: Update sysctl.conf on the server.
template: src=sysctl.conf dest=/etc/sysctl.conf owner=root group=root backup=yes mode=0600
- name: Update limits.conf on the server.
template: src=limits.conf dest=/etc/security/limits.conf backup=yes mode=0644
- name: Update '90-nproc.conf' on the server.
template: src="90-nproc.conf" dest=/etc/security/limits.d/ owner=root group=root backup=yes mode=0644
- name: Update 'etc/hosts' on the server.
template: src=etc_hosts dest=/etc/hosts owner=root group=root backup=yes mode=0644
- name: Update `{{ hadoop_user }}.conf` on the server.
template: src=hdadmin.conf dest=/etc/security/limits.d/{{ hadoop_user }}.conf owner=root group=root backup=yes mode=0644
- name: Setting `sysctl.conf` configuration.
command: sysctl -p
- name: Update Hostname (/etc/sysconfig/network)
lineinfile: dest=/etc/sysconfig/network regexp='^HOSTNAME' line="HOSTNAME={{ host_name }}" state=present
- name: Setting the Hostname Without a restart.
command: hostname {{ host_name }}
上述playbook文件中包含了一系列的处理步骤。为了让selinux配置生效,需要把所有的主机都重启一遍。Ansible具有等幂特性,也就是多次执行同样的playbook,只要主机节点已经配置好就不会对配置内容进行修改。这个特性可以用于检查配置项是否发生变化,或者增加新的主机节点到主机组中。
5.2.3 Ansible无口令密钥执行环境
在配置Ansible无口令密钥执行环境时,请先检查epel-release、libselinux-python、sshpass这三个软件包确保已经安装,然后按照如下步骤操作。
1.known_hosts中添加远程节点的公钥信息
为了不在SSH第一次登录时候出现添加到known_hosts的提示,先把公钥信息附加到/etc/ssh/ssh_known_hosts文件中:
$cat ~/role/ssh_known_hosts/tasks/main.yml
---
- name: Make sure the known hosts file exists
file: "path={{ ssh_known_hosts_file }} state=touch"
- name: Check host name availability
shell: "ssh-keygen -f {{ ssh_known_hosts_file }} -F {{ item }}"
with_items: groups['sshknownhosts']
register: ssh_known_host_results
- name: Scan the public key
shell: "{{ ssh_known_hosts_command}} {{ item.item }} >> {{ ssh_
known_hosts_file }}"
with_items: ssh_known_host_results.results
when: item.stdout == ""
2.无密码SSH远程登录
把生产的密钥对放在role/ssh_password_less/templates/目录下,包括id_rsa、id_rsa.pub。然后在tasks目录下添加playbook执行脚本:
$cat ~/role/ssh_password_less/tasks/main.yml
---
- name: Create a User `"{{ hadoop_user }}"` for all our Hadoop Modules.
user: name={{ hadoop_user }} password={{ hadoop_password }}
- name: Create a .ssh Directory.
file: path=~/.ssh state=directory owner={{ hadoop_user }} group={{ hadoop_group }} mode=0700
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Lets copy the template id_rsa to auth_keys location.
template: src=id_rsa.pub dest=~/.ssh/authorized_keys mode=644
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Lets copy id_rsa to location .ssh.
template: src=id_rsa dest=~/.ssh/id_rsa mode=600
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Lets copy id_rsa.pub to location .ssh.
template: src=id_rsa.pub dest=~/.ssh/id_rsa.pub mode=644
sudo: yes
sudo_user: "{{ hadoop_user }}"
注:模板中的配置参数是定义在group_vars目录下。
5.2.4 安装、配置JDK
把下载的Hadoop软件、Java源码安装包复制到file_archives目录。
在本例中将用到两个主要源码文件:hadoop-2.6.0-cdh5.4.7.tar.gz(CDH5源码安装包)和jdk-7u80-linux-x64.tar.gz(Java源码安装包)。
对于安装Java构成比较简单,首先对Java的软件源、软件版本进行定义,然后创建目录、安装解压、设置环境变量、创建链接等就完成了。
1)定义JDK部署的参数。
$cat ~/roles/jdk/defaults/main.yml jdk_download_filename: jdk-7u80-linux-x64.tar.gz jdk_version: jdk1.7.0_80
2)JDK部署脚本。创建Java安装目录、设置环境变量、创建软件链接:
$cat ~/roles/jdk/tasks/main.yml
- name: JDK | Make sure openjdk is uninstalled
yum: pkg=openjdk state=absent
- name: JDK | Make a directory that holds the Java binaries
file: path=/usr/local/java state=directory
- name: JDK | Unarchive Oracle JDK
unarchive: src=file_archives/{{ jdk_download_filename }} dest=/usr/local/java chdir=/usr/local/java creates=/usr/local/java/{{ jdk_version }}
- name: JDK | Update the symbolic link to the JDK install
file : path={{ java_home }} src=/usr/local/java/{{ jdk_version }} state=link force=yes
- name: JDK | Add the JDK binaries to the system path (/etc/profile)
lineinfile: dest=/etc/profile regexp='^JAVA_HOME={{ java_home }}' line="JAVA_HOME={{ java_home }}" state=present
- name: JDK | Add the JDK binaries to the system path (/etc/profile)
lineinfile: dest=/etc/profile regexp='^PATH=.*JAVA_HOME.*' line="PATH=$PATH:$HOME/bin:$JAVA_HOME/bin" state=present
- name: Remove alternatives before we set them.
command: rm -f /var/lib/alternatives/{{ item }}
with_items:
- java
- javac
- javaws
- javah
- jar
- jps
- name: JDK | Inform the system where Oracle JDK is located
alternatives: name={{ item }} link=/usr/bin/{{ item }} path=/usr/local/java/jdk/bin/{{ item }}
with_items:
- java
- javac
- javaws
- javah
- jar
- jps
5.3 部署Hadoop集群
在Ansible自动化管理中,首先需要分析被管节点的功能、需要部署软件、使用的配置文件,根据节点配置参数相同、相似、可继承等方式对节点进行分组,形成Ansible的资源清单(inventory),再由ansible-playbook对这些分组进行模板、任务的组织。
在本实例中,资源清单直接在hosts文件中定义,该文件中包含最顶层的sshknown hosts、allnodes主机组,sshknownhosts主机组包含hadoopcluster主机组,然后是hadoopcluster包含namenodes、secondarynamenode、resourcemanager、jobhistoryserver、datanodes等主机组。
下面是hosts文件清单:
#需要初始化Linux环境的所有节点
[allnodes] 172.16.1.220 host_name=ah-ansible 172.16.1.221 host_name=ah-namenode 172.16.1.222 host_name=ah-secondary-namenode 172.16.1.223 host_name=ah-resourcemanager 172.16.1.224 host_name=ah-datanode-01 172.16.1.225 host_name=ah-datanode-02 172.16.1.226 host_name=ah-datanode-03 172.16.1.227 host_name=ah-datanode-04 # hadoop cluster [namenodes] 172.16.1.221 [secondarynamenode] 172.16.1.222 [resourcemanager] 172.16.1.223 [jobhistoryserver] 172.16.1.223 [datanodes] 172.16.1.224 172.16.1.225 172.16.1.226 172.16.1.227 [hadoopcluster:children] namenodes secondarynamenode resourcemanager jobhistoryserver datanodes # sshknown hosts list. [sshknownhosts:children] hadoopcluster
在编写Ansible自动化脚本时,通常把playbook脚本封装成角色(role),便于管理、重用。在本例中我们把Hadoop部署的playbook脚本封装成多个角色,然后通过ansible_hadoop.yml将调用ssh_password_less、cdh5_commons角色,初始化hadoopcluster集群所有节点。然后再对namenodes、secondarynamenode、resourcemanager、datanodes主机组分别再调用cdh5_namenode_active、cdh5_namenode_secondary、cdh5_resourcemgr、cdh5_datanode角色进行部署。
部署Hadoop的playbook脚本ansible_hadoop.yml将用root在hadoopcluster范围内部署,首先调用cdh5_commons角色对所有主机Linux进行初始化,然后对其他不同功能的主机组进行分别部署:
ansible_hadoop.yml - hosts: hadoopcluster remote_user: root roles: - ssh_password_less - cdh5_commons - hosts: namenodes remote_user: root roles: - cdh5_namenode_active - hosts: secondarynamenode remote_user: root roles: - cdh5_namenode_secondary - hosts: resourcemanager remote_user: root roles: - cdh5_ resourcemgr - hosts: datanodes remote_user: root roles: - cdh5_datanode
下面将对每个角色的部署内容进行讲述。
5.3.1 准备Hadoop基础角色
准备Hadoop角色在roles/cdh5_commons目录下,主要包含Hadoop环境配置的模板文件、task任务执行的playbook脚本。
1.模板文件
(1)roles/cdh5_commons/templates/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://{% for server in groups['namenodes'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}{{ server }}{% endfor %}:9000</value>
</property>
</configuration>
(2)roles/cdh5_commons/templates/DatanodeScripts.sh
# Update /etc/hosts
sudo cp /etc/hosts /etc/hosts.bkpz
sudo cp etc_new_hosts /etc/hosts
# Create Directories for NN/DN/JN
sudo mkdir -p /data1/nn /data1/jn
for item in 1 2 3 4 5 6;
do
sudo mkdir -p /data${item}/dn;
sudo mkdir -p /data${item}/yarn/local;
sudo mkdir -p /data${item}/yarn/logs;
sudo chown hdadmin:hdadmin -R /data${item}/dn
sudo chown hdadmin:hdadmin -R /data${item}/yarn
done;
# Change Directory Permissions.
sudo chown hdadmin:hdadmin /data1/nn
sudo chown hdadmin:hdadmin /data1/jn
(3)roles/cdh5_commons/templates/etc_hosts.txt
# ETC HOST FILE
# Service Running on Each Node.
172.16.1.220 AH-ANSIBLE #ANSIBLE / Client
172.16.1.221 AH-NAMENODE # NAMENODE / JOURNALNODE
172.16.1.222 AH -STANDBY-NN # STANDBY NAMENODE / JOURNALNODE
172.16.1.223 AH -RES-MANAGER # RESOURCE MANAGER / JOURNALNODE
172.16.1.224 AH -DATANODE-01 # DATANODE / NODEMANAGER
172.16.1.225 AH -DATANODE-02 # DATANODE / NODEMANAGER
172.16.1.226 AH -DATANODE-03 # DATANODE / NODEMANAGER
172.16.1.227 AH -DATANODE-04 # DATANODE / NODEMANAGER
(4)roles/cdh5_commons/templates/hadoop-env.sh
export JAVA_HOME={{ java_home }}
# The jsvc implementation to use. Jsvc is required to run secure datanodes.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
# Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
# Where log files are stored in the secure data environment.
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by the user that will run the hadoop daemons. Otherwise there is the potential
for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
(5)roles/cdh5_commons/templates/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>{{ hadoop_hdfs['dfs_replication'] }}</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>{% for data_dir_parent in hadoop_hdfs['dfs_dir_parent'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}file://{{ data_dir_parent }}{{ hadoop_hdfs['dfs_dir_namenode'] }}{% endfor %}</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>{% for data_dir in hadoop_hdfs['dfs_dir_datanode'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}file://{{ data_dir }}{% endfor %}</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>{% for server in groups['secondarynamenode'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}{{ server }}{% endfor %}:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>{% for data_dir in hadoop_hdfs['dfs_dir_parent'] %}{% if not loo
p.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}file://{{ data_dir }}{{ hadoop_hdfs['dfs_dir_sec_namenode'] }}{% endfor %}</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>{{ hadoop_hdfs['dfs_datanode_max_xcievers'] }}</value>
</property>
</configuration>
(6)roles/cdh5_commons/templates/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--<property>
<name>mapred.child.java.opts</name>
<value>Xmx1024M</value>
</property> -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>{{ hadoop_map_reduce['mr_map_mem_mb'] }}</value>
</property>
<property>
<name>mapreduce.tasktracker.map.tasks.maximum</name>
<value>{{ hadoop_map_reduce['mr_tt_map_task_max'] }}</value>
</property>
<property>
<name>mapreduce.tasktracker.reduce.tasks.maximum</name>
<value>{{ hadoop_map_reduce['mr_tt_reduce_task_max'] }}</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>{{ hadoop_map_reduce['mr_reduce_mem_mb'] }}</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>{{ hadoop_map_reduce['mr_map_java_opts'] }}</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>{{ hadoop_map_reduce['mr_reduce_java_opts'] }}</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>{% for server in groups['jobhistoryserver'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}{{ server }}{% endfor %}:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>{% for server in groups['jobhistoryserver'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}{{ server }}{% endfor %}:19888</value>
</property>
</configuration>
(7)roles/cdh5_commons/templates/MasterScript.sh
# Update /etc/hosts
sudo cp /etc/hosts /etc/hosts.bkpz
sudo cp etc_new_hosts /etc/hosts
# Create Directories for NN/DN/JN
sudo mkdir -p /data1/nn /data1/jn
# Change Directory Permissions.
sudo chown hdadmin:hdadmin /data1/nn
sudo chown hdadmin:hdadmin /data1/jn
(8)roles/cdh5_commons/templates/slaves
{% for server in groups['datanodes'] %}
{{ server }}
{% endfor %}
(9)roles/cdh5_commons/templates/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>{% for server in groups['resourcemanager'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}{{ server }}{% endfor %}</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>{% for data_dir in hadoop_yarn['yarn_nodemgr_local_dir'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif%}file://{{ data_dir }}{% endfor %}</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>{% for data_dir in hadoop_yarn['yarn_nodemgr_log_dir'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}file://{{ data_dir }}{% endfor %}</value>
</property>
<property>
<name>yarn.log.aggregation-enable</name>
<value>true</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>hdfs://{% for server in groups['namenodes'] %}{% if not loop.first and flag == 1 %},{% else %}{% set flag=1 %}{% endif %}{{ server }}{% endfor %}:9000/var/log/hadoop_yarn/apps</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>{{ hadoop_yarn['yarn_nodemgr_resource_mem_mb'] }}</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>{{ hadoop_yarn['yarn_scheduler_min_alloc_mb'] }}</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>{{ hadoop_yarn['yarn_scheduler_max_alloc_mb'] }}</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>{{ hadoop_yarn['yarn_log_aggr_enable'] }}</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
{{ common['soft_link_base_path'] }}/hadoop/etc/hadoop/*,
{{ common['soft_link_base_path'] }}/hadoop/share/hadoop/common/*,
{{ common['soft_link_base_path'] }}/hadoop/share/hadoop/common/lib/*,
{{ common['soft_link_base_path'] }}/hadoop/share/hadoop/hdfs/*,
{{ common['soft_link_base_path'] }}/hadoop/share/hadoop/hdfs/lib/*,
{{ common['soft_link_base_path'] }}/hadoop/share/hadoop/mapreduce/*,
{{ common['soft_link_base_path'] }}/hadoop/share/hadoop/mapreduce/lib/*,
{{ common['soft_link_base_path'] }}/hadoop/share/hadoop/yarn/*,
{{ common['soft_link_base_path'] }}/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
2.执行任务task的playbook脚本文件
创建hadoop用户账号,设置权限,该用户将用户对Hadoop环境的管理,包括服务的启动、重启、停止等。首先是创建操作系统的账号:
$cat~/roles/cdh5_commons/tasks/main.yml
---
- name: Create a User '"{{ hadoop_user }}"' for all our Hadoop Modules.
user: name={{ hadoop_user }} password={{ hadoop_password }}
- name: Create a .ssh Directory.
file: path=~/.ssh state=directory owner={{ hadoop_user }} group=
{{ hadoop_group }} mode=0700
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Lets copy the template id_rsa to auth_keys location.
template: src=id_rsa.pub dest=~/.ssh/authorized_keys mode=644
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Lets copy id_rsa to location .ssh.
template: src=id_rsa dest=~/.ssh/id_rsa mode=600
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Lets copy id_rsa.pub to location .ssh.
template: src=id_rsa.pub dest=~/.ssh/id_rsa.pub mode=644
sudo: yes
sudo_user: "{{ hadoop_user }}"
然后创建Hadoop的管理账号:
$cat~/roles/cdh5_commons/tasks/user.yml
---
- name: Create a User `"{{ hadoop_user }}"` for all our Hadoop Modules.
user: name="{{ hadoop_user }}" password={{ hadoop_password }}
创建Hadoop安装目录,并把Hadoop的源文件解压,创建软链接如下所示:
$cat~/roles/cdh5_commons/tasks/install.yml
---
- name: Copy and UnArchive the Package in Destination Server.
unarchive: creates={{ common['install_base_path'] }}/{{ hadoop_version }} src=file_archives/{{ hadoop_version }}.tar.gz dest={{ common['install_base_path'] }} owner={{ hadoop_user }} group={{ hadoop_group }}
- name: Change Directory Permissions.
file: path={{ common['install_base_path'] }}/{{ hadoop_version }} owner={{ hadoop_user }} group={{ hadoop_group }} recurse=yes
- name: Creating a Symbolic Link in {{ common['install_base_path'] }}/hadoop.
file: src={{ common['install_base_path'] }}/{{ hadoop_version }} path={{ common['soft_link_base_path'] }}/hadoop state=link owner={{ hadoop_user }} group={{ hadoop_group }}
部署模板文件到每个节点上。
$cat~/roles/cdh5_commons/tasks/comfigure.yml
---
- name: Updating Configuration File in Zookeeper.
template: src={{ item }} dest={{ common['soft_link_base_path'] }}/hadoop/etc/hadoop/ owner={{ hadoop_user }} group={{ hadoop_group }}
with_items:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- slaves
- mapred-site.xml
- hadoop-env.sh
这些模板就是Hadoop的配置文件,具体内容请参考《Hadoop权威指南》。
5.3.2 部署NameNode角色
在Hadoop中,NameNode负责对HDFS的元数据(metadata)持久化存储,处理来自客户端对HDFS各种操作的交互反馈。为了保证交互速度,HDFS文件系统的元数据被转载到NameNode主机的内存中,并且会将内存中这些元数据保存到磁盘进行持久化存储。为了使这个持久化过程不会成为HDFS操作的瓶颈,Hadoop通常不是对每一次操作的当前文件系统直接snapshot进行持久化,而是对HDFS最近一段时间的操作列表保存到NameNode中的Editlog文件中。当需要重启NameNode时,除了加载fsImage之外,还对EditLog文件中记录的HDFS操作进行重做(replay),恢复HDFS重启之前的最近状态。
部署NameNode包括主NameNode部署角色(cdh5_namenode_primary)和辅助NameNode部署角色(cdh5_namenode_secondary)。
1.部署主NameNode
创建主NameNode的hadoop_hdfs文件系统目录、辅助NameNode的hadoop_hdfs文件系统目录,然后初始化hadoop_hdfs文件系统,最后启动Namenode服务进程,代码如下所示:
$cat~/roles/cdh5_namenode_primary/tasks/main.yml
---
- name: Create 'namenode' directory
file: path={{ item }}{{ hadoop_hdfs.dfs_dir_namenode }} owner={{ hadoop_user }} group={{ hadoop_group }} state=directory
with_items: hadoop_hdfs.dfs_dir_parent
- name: Create 'secondary namenode' directory
file: path={{ item }}{{ hadoop_hdfs.dfs_dir_sec_namenode }} owner={{ hadoop_user }} group={{ hadoop_group }} state=directory
with_items: hadoop_hdfs.dfs_dir_parent
- name: Format the namenode - [[ WILL NOT FORMAT IF current/VERSION]].
command: creates={{ hadoop_hdfs.dfs_dir_parent[0] }}{{ hadoop_hdfs.dfs_dir_namenode }}/current/VERSION sh {{ common['soft_link_base_path'] }}/hadoop/bin/hadoop namenode -format
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Starting Namenode Service.
command: sh {{ common['soft_link_base_path'] }}/hadoop/sbin/hadoop-daemon.sh start namenode
sudo: yes
sudo_user: "{{ hadoop_user }}"
2.部署辅助NameNode
为提高Hadoop系统可靠性,生产系统一般还会部署辅助NameNode,会周期性地将EditLog中记录的HDFS操作合并到一个CheckPoint中,然后清空EditLog。
在NameNode重启时就会装载最新的一个CheckPoint,并重做EditLog中记录的HDFS操作。由于EditLog中记录的是从上一次CheckPoint以后到现在的操作记录,所以比较小,能够快速恢复到重启Hadoop集群最近的状态,保证系统的完整性。
部署辅助NameNode角色与部署主NameNode的playbook脚本基本一样,只是在启动服务时候参数是secondarynamenode,具体的playbook内容如下:
$cat~/roles\cdh5_namenode_secondary\tasks\main.yml
---
- name: Create 'secondary-namenode' data directory.
file: path={{ item }}{{ hadoop_hdfs.dfs_dir_namenode }} owner={{ hadoop_user }} group={{ hadoop_group }} state=directory
with_items: hadoop_hdfs.dfs_dir_parent
- name: Create 'secondary namenode' data directory
file: path={{ item }}{{ hadoop_hdfs.dfs_dir_sec_namenode }} owner={{ hadoop_user }} group={{ hadoop_group }} state=directory
with_items: hadoop_hdfs.dfs_dir_parent
- name: Starting Secondary Namenode.
command: sh {{ common['soft_link_base_path'] }}/hadoop/sbin/hadoop-daemon.sh start secondarynamenode
sudo: yes
sudo_user: "{{ hadoop_user }}"
5.3.3 部署资源管理器角色
通过YARN大大扩展了Hadoop传统应用的潜在应用范围。YARN构建于当前Hadoop集群的现有元素之上,是一个真正的Hadoop资源管理器,改进了JobTracker等元素,提高了可伸缩性和增强许多不同应用程序共享集群的能力,允许多个应用程序同时、高效地运行在一个的集群上。YARN是大数据发展的一个基础性组件。YARN将传统的Hadoop放到了一个可组合的、契合目的(fit-to-purpose)的平台中,以处理数据管理、分析和交易计算等工作。
YARN中的资源管理器(Resource Manager)负责整个系统的资源管理和调度,并内部维护了各个应用程序的ApplictionMaster信息、NodeManager信息、资源使用信息等。
在本例中,我们专门编写了启动资源管理器的角色,主要是启动yarn和jobhistory进程。详细脚本如下:
$cat/roles/cdh5_resourcemgr/tasks/main.yml
---
- name: Start Resource Manager.
command: sh {{ common['soft_link_base_path'] }}/hadoop/sbin/yarn-daemon.sh start resourcemanager
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Start Job Hostory Server.
command: sh {{ common['soft_link_base_path'] }}/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
sudo: yes
sudo_user: "{{ hadoop_user }}"
5.3.4 部署DataNode角色
DataNode是文件系统的工作节点,最终存储数据的位置。它们根据客户端或者NameNode的调度存储和检索数据,并且定期向NameNode发送它们所存储的块(block)的列表。
集群中的每个数据服务节点都运行着一个DataNode后台进程,这个后台进程负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后客户端直接与这个DataNode服务节点的后台程序进行通信,并对相关的数据块进行读/写操作。
对于DataNode部署,我们编写了cdh5_datanode部署的角色,负责目录创建和启动后台进程。具体如下:
$cat~/roles/cdh5_datanode/tasks/main.yml
---
- name: Creating Datanode Directory.
file: path={{ item }} owner={{ hadoop_user }} group={{ hadoop_group }} state=directory
with_items: hadoop_hdfs.dfs_dir_datanode
- name: Creating Yarn Local Directories.
file: path={{ item }} owner={{ hadoop_user }} group={{ hadoop_group }}
state=directory
with_items: hadoop_yarn.yarn_nodemgr_local_dir
- name: Creating Yarn Log Directories.
file: path={{ item }} owner={{ hadoop_user }} group={{ hadoop_group }} state=directory
with_items: hadoop_yarn.yarn_nodemgr_log_dir
- name: Starting Datanode.
command: sh {{ common['soft_link_base_path'] }}/hadoop/sbin/hadoop-daemon.sh start datanode
sudo: yes
sudo_user: "{{ hadoop_user }}"
- name: Starting Node Manager.
command: sh {{ common['soft_link_base_path'] }}/hadoop/sbin/yarn-daemon.sh start nodemanager
sudo: yes
sudo_user: "{{ hadoop_user }}"
在DataNode上启动Hadoop进程时将会调用从cdh5_common/templates部署到/opt/hadoop/etc/hadoop/yarn-site.xml的配置文件。
5.4 部署后Hadoop初始化与验证
Hadoop系统部署完成后需要对Hadoop集群DHFS进行初始化,同时运维也需要了解Hadoop运行状态,可以从Web界面和命令行方式分别了解Hadoop集群的使用情况。
5.4.1 部署后初始化
安装好Hadoop软件、启动了服务之后,就准备开始使用。这是需要对Hadoop集群系统做些初始化工作,主要是创建Hadoop用户账号、授权、创建服务目录。
专门放置在post_install_setups角色中,具体内容如下:
$cat~/roles/post_install_setups/tasks/create_hadoop_user.yml
---
- name: Create a User '"{{ storm_user }}"' for all our Hadoop Modules.
user: name="{{ storm_user }}" password={{ storm_user }}
- name: Create /tmp and /var directories in HDFS.
command: sh "{{ common['soft_link_base_path'] }}"/hadoop/bin/hadoop fs -mkdir -p {{ item }}
sudo: yes
sudo_user: "{{ hadoop_user }}"
with_items:
- "/tmp"
- "/var"
- "/user/{{ storm_user }}"
- "/user/{{ hadoop_user }}"
- name: Setting Permission for Hadoop /tmp and /var directories.
command: sh "{{ common['soft_link_base_path'] }}"/hadoop/bin/hadoop fs -chmod 1777 {{ item }}
sudo: yes
sudo_user: "{{ hadoop_user }}"
with_items:
- "/tmp"
- "/var"
- name: Setting Permission for Hadoop /user/{{ storm_user }} directoy.
command: sh "{{ common['soft_link_base_path'] }}"/hadoop/bin/hadoop fs -chown {{ storm_user }}:{{ storm_group }} /user/{{ storm_user }}
sudo: yes
sudo_user: "{{ hadoop_user }}"
然后通过main.yml文件调用create_hadoop_user.yml:
$cat~/roles/post_install_setups/tasks/main.yml --- - include: create_hadoop_user.yml
5.4.2 部署后Hadoop验证
下面分别从Web界面和命令行方式了解Hadoop集群的使用情况。
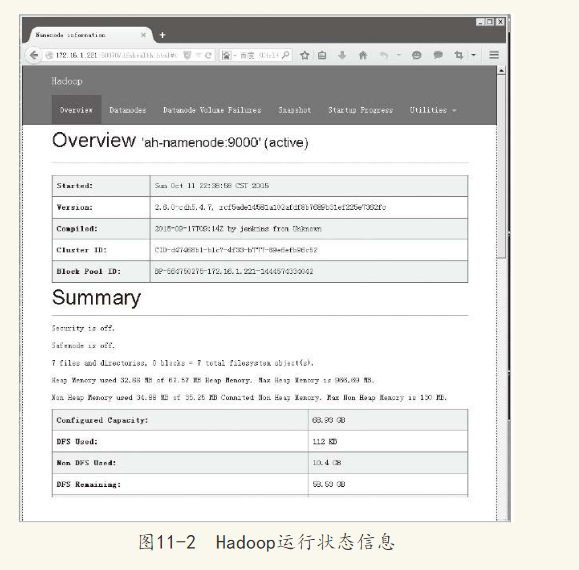
1.Web查看Hadoop集群信息
在浏览器中输入http://172.16.1.221:50070/,将会看到Hadoop集群的主要信息,包括概览(OverView)、DataNodes、Datanode Volume Failures、Snapshot、Startup Progress、Utilities等内容。
图11-2是本例中集群概览的部分内容。
2.命令行创建HDFS文件目录:
$ /usr/local/hadoop-2.6.0-cdh5.4.7/bin/hadoop fs -mkdir /user/ansible $ /usr/local/hadoop-2.6.0-cdh5.4.7/bin/hadoop fs -ls /user Found 3 items drwxr-xr-x - hdadmin supergroup 0 2015-10-12 21:14 /user/ansible drwxr-xr-x - hdadmin supergroup 0 2015-10-11 22:39 /user/hdadmin drwxr-xr-x - stormadmin stormadmin 0 2015-10-11 22:39 /user/stormadmin
修改HDFS文件目录权限:
$ /usr/local/hadoop-2.6.0-cdh5.4.7/bin/hadoop fs -chown ansible:ansible /user/ansible $ /usr/local/hadoop-2.6.0-cdh5.4.7/bin/hadoop fs -ls /user Found 3 items drwxr-xr-x - ansible ansible 0 2015-10-12 21:14 /user/ansible drwxr-xr-x - hdadmin supergroup 0 2015-10-11 22:39 /user/hdadmin drwxr-xr-x - stormadmin stormadmin 0 2015-10-11 22:39 /user/stormadmin
显示输出HDFS文件系统信息:
$ /usr/local/hadoop-2.6.0-cdh5.4.7/bin/hadoop dfsadmin -report DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Configured Capacity: 74014457856 (68.93 GB) Present Capacity: 62851162112 (58.53 GB) DFS Remaining: 62851047424 (58.53 GB) DFS Used: 114688 (112 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (4): Name: 172.16.1.226:50010 (ahmd-datanode-03) Hostname: ahmd-datanode-03 Decommission Status : Normal Configured Capacity: 18503614464 (17.23 GB) DFS Used: 28672 (28 KB) Non DFS Used: 2790846464 (2.60 GB) DFS Remaining: 15712739328 (14.63 GB) Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Mon Oct 12 21:23:49 CST 2015
………
5.5 本章小结
本章从大数据需求入手,介绍如何使用Ansible自动化工具部署基于CDH5的Hadoop环境。从操作系统安装、操作系统初始化、部署Hadoop软件,到最后验证部署系统的完整过程。按照每个功能一个角色的方式进行设计,展现一个完整的、复杂的系统如何进行自动化的工作,可以借鉴本章的内容快速在生产环境中使用。
来源: ansible自动化运维技术与最佳实践
具体API,可以参考:http://www.ansible.com.cn/
如果有一定经费,并且不想看书的童鞋可以在51CTO上购买马哥2016全新实战课程-Ansible自动化运维专题视频课程!
如果经费更加充足的,也可以赞助小编,一起学习,一起飞!
在掌握了基础之后,还得多加练习!才行!

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~




