前言
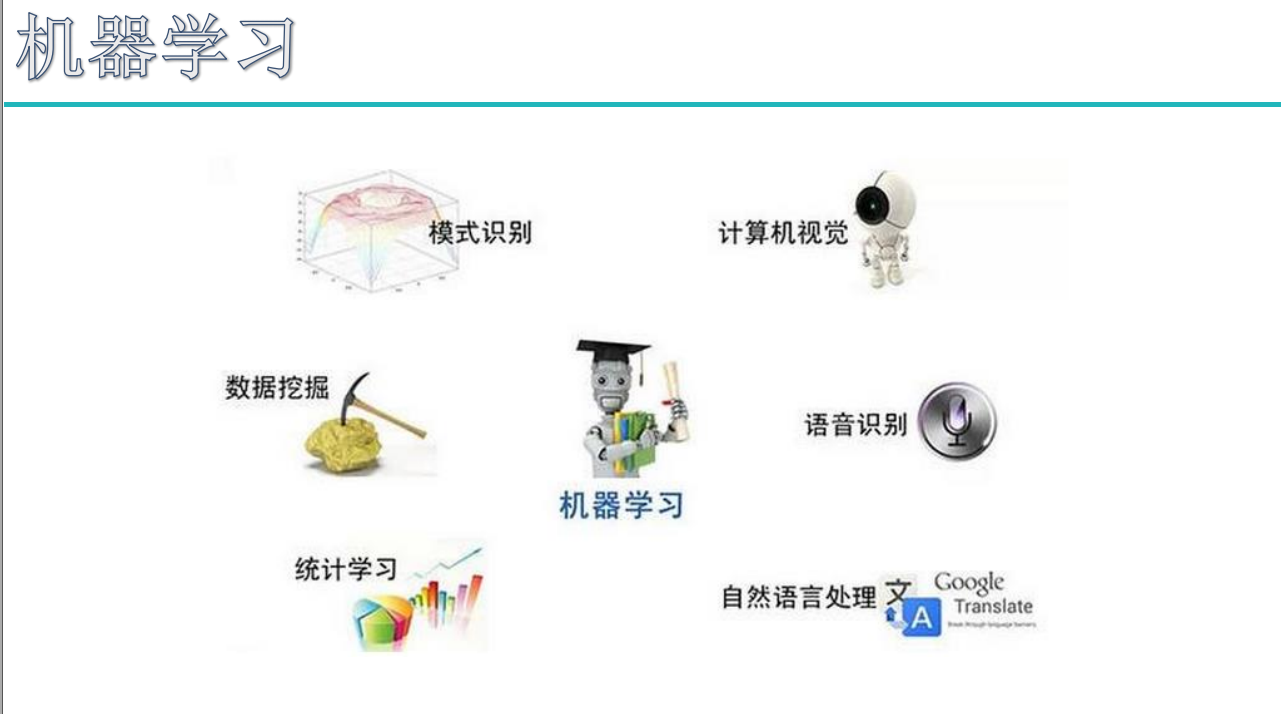
AI,机器学习和深度学习的区别到底是什么?
1. 深度学习与AI。本质上来讲,人工智能相比深度学习是更宽泛的概念。人工智能现阶段分为弱人工智能和强人工智能,实际上当下科技能实现的所谓“人工智能”都是弱AI,奥创那种才是强AI(甚至是boss级的)。而深度学习,是AI中的一种技术或思想,曾被MIT技术评论列为2013年十大突破性技术(Deep Learning居首)。或者换句话说,深度学习这种技术(我更喜欢称其为一种思想,即end-to-end)说不定就是实现未来强AI的突破口。 2. 深度学习与ML。DL与ML两者其实有着某种微妙的关系。在DL还没有火起来的时候,它是以ML中的神经网略学习算法存在的,随着计算资源和big data的兴起,神经网络摇身一变成了如今的DL。学界对DL一般有两种看法,一种是将其视作feature extractor,仅仅用起提取powerful feature;而另一种则希望将其发展成一个新的学习分支,也就是我上面说的end-to-end的“深度学习的思想”。
AI发展史
1956年,在达特茅斯会议(Dartmouth Conferences)上,计算机科学家首次提出了“AI”术语,AI由此诞生,在随后的日子里,AI成为实验室的“幻想对象”。几十年过去了,人们对AI的看法不断改变,有时会认为AI是预兆,是未来人类文明的关键,有时认为它只是技术垃圾,只是一个轻率的概念,野心过大,注定要失败。坦白来讲,直到2012年AI仍然同时具有这两种特点。
在过去几年里,AI大爆发,2015年至今更是发展迅猛。之所以飞速发展主要归功于GPU的广泛普及,它让并行处理更快、更便宜、更强大。还有一个原因就是实际存储容量无限拓展,数据大规模生成,比如图片、文本、交易、地图数据信息。
AI:让机器展现出人类智力
回到1956年夏天,在当时的会议上,AI先驱的梦想是建造一台复杂的机器(让当时刚出现的计算机驱动),然后让机器呈现出人类智力的特征。
这一概念就是我们所说的“强人工智能(General AI)”,也就是打造一台超棒的机器,让它拥有人类的所有感知,甚至还可以超越人类感知,它可以像人一样思考。在电影中我们经常会看到这种机器,比如 C-3PO、终结者。
还有一个概念是“弱人工智能(Narrow AI)”。简单来讲,“弱人工智能”可以像人类一样完成某些具体任务,有可能比人类做得更好,例如,Pinterest服务用AI给图片分类,Facebook用AI识别脸部,这就是“弱人工智能”。
上述例子是“弱人工智能”实际使用的案例,这些应用已经体现了一些人类智力的特点。怎样实现的?这些智力来自何处?带着问题我们深入理解,就来到下一个圆圈,它就是机器学习。
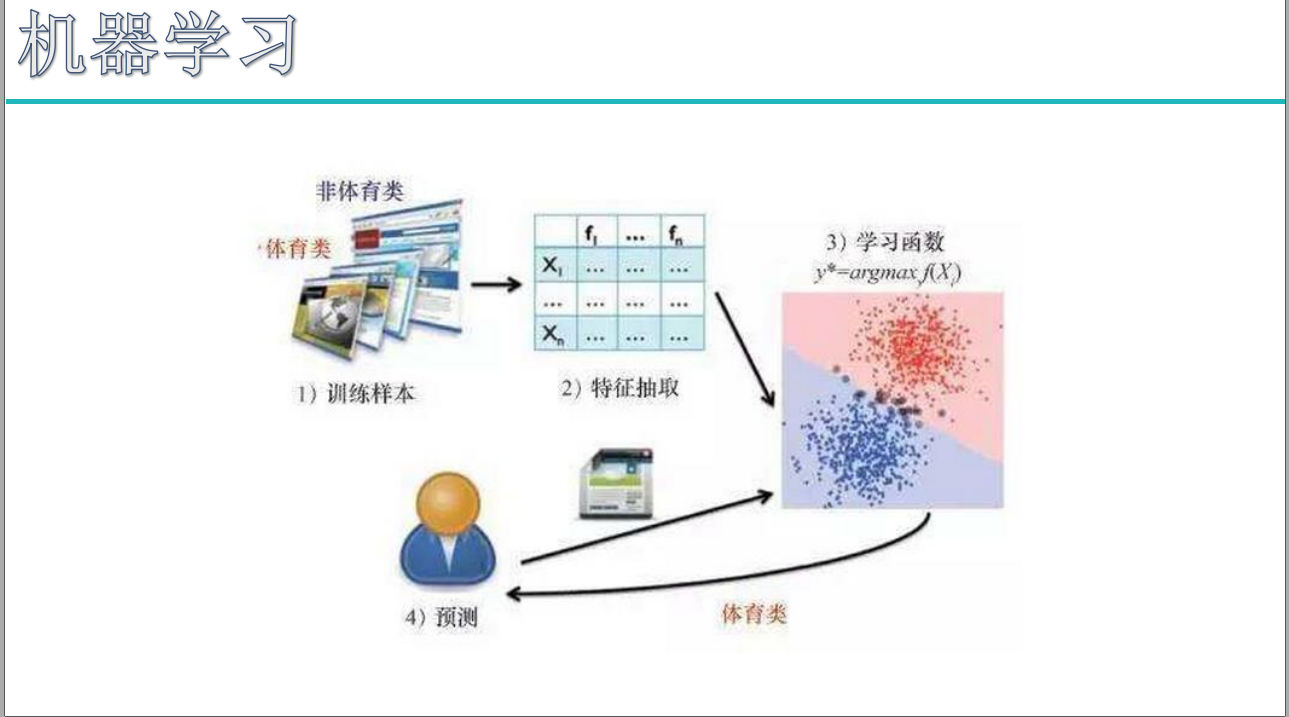
机器学习:抵达AI目标的一条路径
大体来讲,机器学习就是用算法真正解析数据,不断学习,然后对世界中发生的事做出判断和预测。此时,研究人员不会亲手编写软件、确定特殊指令集、然后让程序完成特殊任务,相反,研究人员会用大量数据和算法“训练”机器,让机器学会如何执行任务。
机器学习这个概念是早期的AI研究者提出的,在过去几年里,机器学习出现了许多算法方法,包括决策树学习、归纳逻辑程序设计、聚类分析(Clustering)、强化学习、贝叶斯网络等。正如大家所知的,没有人真正达到“强人工智能”的终极目标,采用早期机器学习方法,我们连“弱人工智能”的目标也远没有达到。
在过去许多年里,机器学习的最佳应用案例是“计算机视觉”,要实现计算机视觉,研究人员仍然需要手动编写大量代码才能完成任务。研究人员手动编写分级器,比如边缘检测滤波器,只有这样程序才能确定对象从哪里开始,到哪里结束;形状侦测可以确定对象是否有8条边;分类器可以识别字符“S-T-O-P”。通过手动编写的分组器,研究人员可以开发出算法识别有意义的形象,然后学会下判断,确定它不是一个停止标志。
这种办法可以用,但并不是很好。如果是在雾天,当标志的能见度比较低,或者一棵树挡住了标志的一部分,它的识别能力就会下降。直到不久之前,计算机视觉和图像侦测技术还与人类的能力相去甚远,因为它太容易出错了。
深度学习:实现机器学习的技术
“人工神经网络(Artificial Neural Networks)”是另一种算法方法,它也是早期机器学习专家提出的,存在已经几十年了。神经网络(Neural Networks)的构想源自于我们对人类大脑的理解——神经元的彼此联系。二者也有不同之处,人类大脑的神经元按特定的物理距离连接的,人工神经网络有独立的层、连接,还有数据传播方向。
例如,你可能会抽取一张图片,将它剪成许多块,然后植入到神经网络的第一层。第一层独立神经元会将数据传输到第二层,第二层神经元也有自己的使命,一直持续下去,直到最后一层,并生成最终结果。
每一个神经元会对输入的信息进行权衡,确定权重,搞清它与所执行任务的关系,比如有多正确或者多么不正确。最终的结果由所有权重来决定。以停止标志为例,我们会将停止标志图片切割,让神经元检测,比如它的八角形形状、红色、与众不同的字符、交通标志尺寸、手势等。
神经网络的任务就是给出结论:它到底是不是停止标志。神经网络会给出一个“概率向量”,它依赖于有根据的推测和权重。在该案例中,系统有86%的信心确定图片是停止标志,7%的信心确定它是限速标志,有5%的信心确定它是一支风筝卡在树上,等等。然后网络架构会告诉神经网络它的判断是否正确。
即使只是这么简单的一件事也是很超前的,不久前,AI研究社区还在回避神经网络。在AI发展初期就已经存在神经网络,但是它并没有形成多少“智力”。问题在于即使只是基本的神经网络,它对计算量的要求也很高,因此无法成为一种实际的方法。尽管如此,还是有少数研究团队勇往直前,比如多伦多大学Geoffrey Hinton所领导的团队,他们将算法平行放进超级电脑,验证自己的概念,直到GPU开始广泛采用我们才真正看到希望。
回到识别停止标志的例子,如果我们对网络进行训练,用大量的错误答案训练网络,调整网络,结果就会更好。研究人员需要做的就是训练,他们要收集几万张、甚至几百万张图片,直到人工神经元输入的权重高度精准,让每一次判断都正确为止——不管是有雾还是没雾,是阳光明媚还是下雨都不受影响。这时神经网络就可以自己“教”自己,搞清停止标志的到底是怎样的;它还可以识别Facebook的人脸图像,可以识别猫——吴恩达(Andrew Ng)2012年在谷歌做的事情就是让神经网络识别猫。
吴恩达的突破之处在于:让神经网络变得无比巨大,不断增加层数和神经元数量,让系统运行大量数据,训练它。吴恩达的项目从1000万段YouTube视频调用图片,他真正让深度学习有了“深度”。
到了今天,在某些场景中,经过深度学习技术训练的机器在识别图像时比人类更好,比如识别猫、识别血液中的癌细胞特征、识别MRI扫描图片中的肿瘤。谷歌AlphaGo学习围棋,它自己与自己不断下围棋并从中学习。
有了深度学习AI的未来一片光明
有了深度学习,机器学习才有了许多实际的应用,它还拓展了AI的整体范围。 深度学习将任务分拆,使得各种类型的机器辅助变成可能。无人驾驶汽车、更好的预防性治疗、更好的电影推荐要么已经出现,要么即使出现。AI既是现在,也是未来。有了深度学习的帮助,也许到了某一天AI会达到科幻小说描述的水平,这正是我们期待已久的。你会有自己的C-3PO,有自己的终结者。
接下来我们了解机器学习能干什么!
因现阶Python语言是支持AI最好的编程语言,所以重点介绍它

生活里中的机器学习:
最近我和一对夫妇共进晚餐,他们问我从事什么职业,我回应道:“机器学习。”妻子回头问丈夫:“亲爱的,什么是机器学习?”她的丈夫答道:“T-800型终结者。”在《终结者》系列电影中,T-800是人工智能技术的反面样板工程。不过,这位朋友对机器学习的理解还是有所偏差的。本书既不会探讨和计算机程序进行对话交流,也不会与计算机探讨人生的意义。机器学习能让我们自数据集中受到启发,换句话说,我们会利用计算机来彰显数据背后的真实含义,这才是机器学习的真实含义。它既不是只会徒然模仿的机器人,也不是具有人类感情的仿生人。
现今,机器学习已应用于多个领域,远超出大多数人的想象,下面就是假想的一日,其中很多场景都会碰到机器学习:假设你想起今天是某位朋友的生日,打算通过邮局给她邮寄一张生日贺卡。你打开浏览器搜索趣味卡片,搜索引擎显示了10个最相关的链接。你认为第二个链接最符合你的要求,点击了这个链接,搜索引擎将记录这次点击,并从中学习以优化下次搜索结果。然后,你检查电子邮件系统,此时垃圾邮件过滤器已经在后台自动过滤垃圾广告邮件,并将其放在垃圾箱内。接着你去商店购买这张生日卡片,并给你朋友的孩子挑选了一些尿布。结账时,收银员给了你一张1美元的优惠券,可以用于购买6罐装的啤酒。之所以你会得到这张优惠券,是因为款台收费软件基于以前的统计知识,认为买尿布的人往往也会买啤酒。然后你去邮局邮寄这张贺卡,手写识别软件识别出邮寄地址,并将贺卡发送给正确的邮车。当天你还去了贷款申请机构,查看自己是否能够申请贷款,办事员并不是直接给出结果,而是将你最近的金融活动信息输入计算机,由软件来判定你是否合格。最后,你还去了赌场想找些乐子,当你步入前门时,尾随你进来的一个家伙被突然出现的保安给拦了下来。“对不起,索普先生,我们不得不请您离开赌场。我们不欢迎老千。”
图1-1集中展示了使用到的机器学习应用。
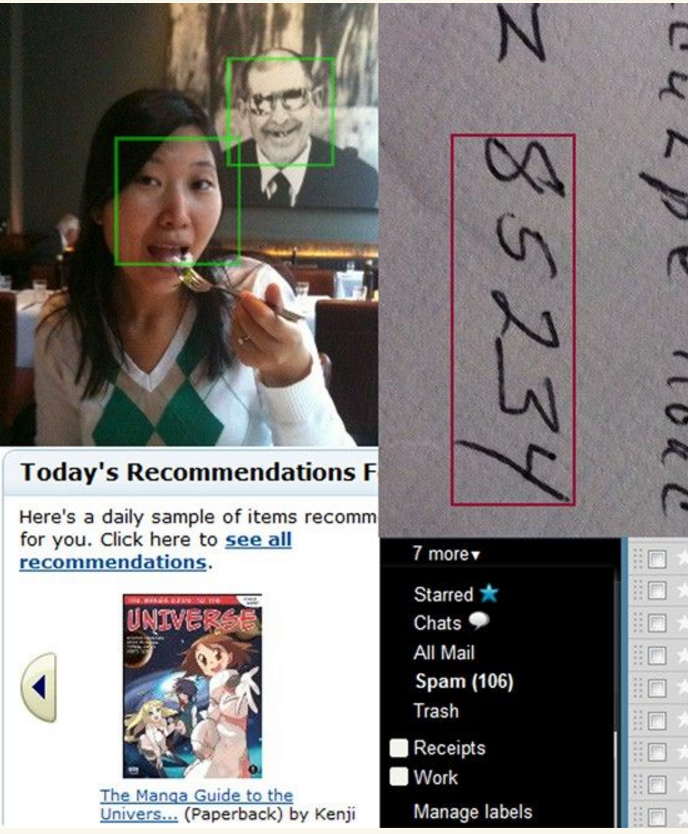
图1-1 机器学习在日常生活中的应用,从左上角按照顺时针方向依次使用到的机器学习技术分别为:人脸识别、手写数字识别、垃圾邮件过滤和亚马逊公司的产品推荐
上面提到的所有场景,都有机器学习软件的存在。现在很多公司使用机器学习软件改善商业决策、提高生产率、检测疾病、预测天气,等等。随着技术指数级增长,我们不仅需要使用更好的工具解析当前的数据,而且还要为将来可能产生的数据做好充分的准备。
现在正式进入本书机器学习的主题。本章我们将首先介绍什么是机器学习,日常生活中何处将用到机器学习,以及机器学习如何改进我们的工作和生活;然后讨论使用机器学习解决问题的一般办法;最后介绍为什么本书使用Python语言来处理机器学习问题。我们将通过一个Python模块NumPy来简要介绍Python在抽象和处理矩阵运算上的优势。
1.1 何谓机器学习
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息。例如,对于垃圾邮件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅以考察邮件长度及其他因素,人们就可以更准确地判定该邮件是否为垃圾邮件。简单地说,机器学习就是把无序的数据转换成有用的信息。
机器学习横跨计算机科学、工程技术和统计学等多个学科,需要多学科的专业知识。稍后你就能了解到,它也可以作为实际工具应用于从政治到地质学的多个领域,解决其中的很多问题。甚至可以这么说,机器学习对于任何需要解释并操作数据的领域都有所裨益。
机器学习用到了统计学知识。在多数人看来,统计学不过是企业用以炫耀产品功能的一种诡计而已。(Darell Huff曾写过一本《如何使用统计学说谎》(How to Lie With Statistics)的书,颇具讽刺意味的是,它也是有史以来卖得最好的统计学书。)那么我们这些人为什么还要利用统计学呢?拿工程实践来说,它要利用科学知识来解决具体问题,在该领域中,我们常会面对那种解法确凿不变的问题。假如要编写自动售货机的控制软件,那就最好能让它在任何时候都能正确运行,而不必让人们再考虑塞进的钱或按下的按钮。然而,在现实世界中,并不是每个问题都存在确定的解决方案。在很多时候,我们都无法透彻地理解问题,或者没有足够的计算资源为问题精确建立模型,例如我们无法给人类活动的动机建立模型。为了解决这些问题,我们就需要使用统计学知识。
在社会科学领域,正确率达60%以上的分析被认为是非常成功的。如果能准确地预测人类当下60%的行为,那就很棒了。这怎么可以呢?难道我们不应该一直都保持完美地预测吗?如果真的达不到,是否意味着我们做错了什么?
人类对自身的极乐有着必然的追求。由此生发,我们为何不能准确地预测人们所参与事件的结果呢?”瞧!这些问题就十分经典。我们不可能对它们建立一种精确模型。如何能让众生以同样的方式获得幸福?很难,因为大家对幸福的理解都是迥异不同的。因此,即使人们能达到极乐境地这一假定是成立的,但如此复杂的幸福也使得我们很难对其建立正确的模型。除了人类行为,现实世界中存在着很多例子,我们无法为之建立精确的数学模型,而为了解决这类问题,我们就需要统计学工具。
1.1.1 传感器和海量数据
虽然我们已从互联网上获取了大量的人为数据,但最近却涌现了更多的非人为数据。传感器技术并不时髦,但如何将它们接入互联网确实是新的挑战。有预测表明,在本书出版后不久,20%的互联网非视频流量都将由物理传感器产生。
地震预测就是一个很好的例子,传感器收集了海量的数据,如何从这些数据中抽取出有价值的信息是一个非常值得研究的课题。1989年,洛马·普列埃塔地震袭击了北加利福尼亚州,63人死亡,3757人受伤,成千上万人无家可归;然而,相同规模的地震2010年袭击了海地,死亡人数却超过23万。洛马·普列埃塔地震后不久,一份研究报告宣称低频磁场检测可以预测地震, 但后续的研究显示,最初的研究并没有考虑诸多环境因素,因而存在着明显的缺陷。如果我们想要重做这个研究,以便更好地理解我们这个星球,寻找预测地震的方法,避免灾难性的后果,那么我们该如何入手才能更好地从事该研究呢?我们可以自己掏钱购买磁力计,然后再买一些地来安放它们,当然也可以寻求政府的帮助,让他们来处理这些事。但即便如此,我们也无法保证磁力计没有受到任何干扰,另外,我们又该如何获取磁力计的读数呢?这些都不是理想的解决方法,使用移动电话可以低成本的解决这个问题。
现今市面上销售的移动电话和智能手机均带有三轴磁力计,智能手机还有操作系统,可以运行我们编写的应用软件,十几行代码就可以让手机按照每秒上百次的频率读取磁力计的数据。此外,移动电话上已经安装了通信系统,如果可以说服人们安装运行磁力计读取软件,我们就可以记录下大量的磁力计数据,而附带的代价则是非常小的。除了磁力计,智能电话还封装了很多其他传感器,如偏航率陀螺仪、三轴加速计、温度传感器和GPS接收器,这些传感器都可以用于测量研究。移动计算和传感器产生的海量数据意味着未来我们将面临着越来越多的数据,如何从海量数据中抽取到有价值的信息将是一个非常重要的课题。
1.1.2 机器学习非常重要
在过去的半个世纪里,发达国家的多数工作岗位都已从体力劳动转化为脑力劳动。过去的工作基本上都有明确的定义,类似于把物品从A处搬到B处,或者在这里打个洞,但是现在这类工作都在逐步消失。现今的情况具有很大的二义性,类似于“最大化利润”,“最小化风险”、“找到最好的市场策略”......诸如此类的任务要求都已成为常态。虽然可从互联网上获取到海量数据,但这并没有简化知识工人的工作难度。针对具体任务搞懂所有相关数据的意义所在,这正成为基本的技能要求。正如谷歌公司的首席经济学家Hal Varian所说的那样:
“我不断地告诉大家,未来十年最热门的职业是统计学家。很多人认为我是开玩笑,谁又能想到计算机工程师会是20世纪90年代最诱人的职业呢?如何解释数据、处理数据、从中抽取价值、展示和交流数据结果,在未来十年将是最重要的职业技能,甚至是大学,中学,小学的学生也必需具备的技能,因为我们每时每刻都在接触大量的免费信息,如何理解数据、从中抽取有价值的信息才是其中的关键。这里统计学家只是其中的一个关键环节,我们还需要合理的展示数据、交流和利用数据。我确实认为,能够从数据分析中领悟到有价值信息是非常重要的。职业经理人尤其需要能够合理使用和理解自己部门产生的数据。”
——McKinsey Quarterly,2009年1月
大量的经济活动都依赖于信息,我们不能在海量的数据中迷失,机器学习将有助于我们穿越数据雾霭,从中抽取出有用的信息。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


