1.5 追踪数据中的错误
如果你严格地检查查询和更新的结果,就会发现很多问题,这些问题可能持续数周而未被察觉,然后慢慢变得越来越严重,直到最后无可避免地引发很多让人苦恼的问题。然而,问题确实在慢慢地接近你。有时,SELECT查询突然开始返回错误的结果,但是你对该查询的经验使你确信它没有什么问题。
在这种情况下,你应该反向模拟用户操作,直到发现错误的根源。如果幸运,你会一步就发现问题的原因。不过通常你会进行多步操作,有时甚至消耗很长的时间。
大部分这种问题是由于复制环境中主从节点的数据不一致造成的。一个常见的错误情形是期望唯一值的时候出现了重复值(例如,如果用户使用INSERT ON DUPLICATE KEY UPDATE语句,但是主从服务器中的表结构是不同的)。在这样的环境设置下,用户往往直到从节点执行SELECT语句的时候才会发现问题,而不会在INSERT发生时就注意到问题。在循环复制时情况会更糟糕。
为了说明这个问题,我们将使用一个存储过程从保存其他查询结果的临时表向另一个表插入数据。这是另一个常用技巧,用于当用户想要处理大表中的数据,同时担心意外修改数据的风险,或者担心在使用这些大表时对其他应用造成堵塞的情形。
我们来创建表并填充临时数据。在实际应用中,临时表会用于保存等待存入主表的计算结果集:

现在向临时表中插入数据:

存储例程将临时表中的数据移入主表。它在迁移前会先确认数据在临时表中。我们的版本如下:

在调用该存储例程时,如果指定的临时表不存在则会创建新的临时表。这样做可以避免由于临时表不存在而产生问题,但同时也会带来新问题。
提示 提示
该示例使用MAX函数检查表中是否至少存在一行记录。推荐用MAX计数,因为InnoDB表不会保存记录的行数,而是在每次调用COUNT函数的时候现进行计算。因此,MAX(indexed_field)函数比COUNT快。
如果从服务器在第一个插入之后,存储过程调用之前重启,那么从服务器中的临时表将会是空的并且从服务器上的主表没有任何数据。在这种情况下,我们访问主节点会得到:

与此同时,在从服务器上得到:
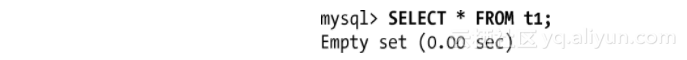
更糟的是,如果我们在存储过程调用后向t1表中插入数据,从服务器中的数据将会完全混乱。
假设我们注意到应用程序中主从表读取数据时的错误。现在我们应该弄清数据是怎么插入从表的:是直接更新从服务器还是从主节点复制的数据?
警告 警告
MySQL复制不会帮你检查数据一致性,因此对同一个对象,同时使用SQL复制线程和从节点上的用户线程更新会使数据与主服务器不同,这会导致随后的复制事件失败。
因为我们在示例中模拟这种情形,所以我们知道发生数据损坏问题的关键点:从服务器在第一次插入之后,存储过程调用之前重启了。在实际场景中,问题一般会在用户执行下面查询的时候被发现:
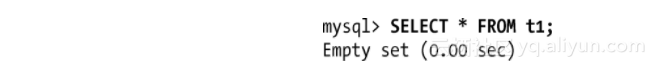
当你从SELECT查询中获得非预期结果时,你需要找出该问题发生的原因,是由于查询本身的问题,还是由于早些时候的一些错误引起的。刚才展示的插入非常简单,除非表损坏了,否则它不可能产生错误,因此我们必须回头检查一下表是如何修改的。
通常的示例是在建立在从服务器只读的复制环境下,因此我们可以确保错误产生有两种可能的原因:要么是主服务器插入了错误的数据,要么是数据在复制时损坏。
所以,首先检查主服务器的数据是否有错误:

主服务器数据正常,因此问题的原因在于复制层。然而,这是怎么发生的?复制看起来运行正常[3],因此我们猜想是主节点有逻辑错误。当发现了这个可能的原因的时候,你应该去分析存储过程并在主节点上调用以寻找修复方案。
如前所述,在向临时表中插入数据完成复制并清空临时表的事件之后,且在调用查询并向主表插入数据的存储过程之前,重启服务器。因此,从服务器仅是重新创建一个空的临时表并且没有插入任何数据。
在这种情况下,可以选择转换成基于行的复制或者重写存储过程,使其不依赖于已经存在的临时表。另一种方法是清空然后重新填充表,这样突然重启不会导致从服务器数据丢失。
有人可能觉得这个示例太过人为了,你不可能预知服务器何时会突然重启。没错,但是重启确实每时每刻都有可能发生。因此,你需要考虑这样的错误。
事实上,从服务器一个接一个地复制二进制日志事件,当数据在一个原子事件(例如,一个事务或者存储过程调用)中产生时,从服务器不会受上述情况的影响。不过回过头来说,这个示例仅仅是为了说明现实生活中发生的事件背后的原理。
当你在明知是正确的情况下遇到了一个问题时,请检查在看到这个问题之前你的应用程序的运行情况。
关于复制错误的更多详细信息会在第5章进行介绍。
单服务器示例
我曾经处理过一个存储由不同的切割系统产生的度量数据的Web应用程序。用户可以添加一个系统,然后编辑保存度量数据的规则。
我第一次遇到错误的时候,我测试了一个含有系统列表的Web页面:

该列表不该包含重复的系统,因为描述同样的规则两次是没有意义的。因此我非常惊奇地看到有很多同名的条目。
输出数据的代码使用的是对象,并且,我无法仅通过阅读代码查看发送到MySQL服务器的语句是什么样的:

我通过日志获取了真实的查询,它看来是正确的:
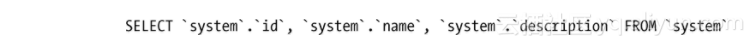
接下来,我检查了表的内容:

SELCET语句准确地返回了表中存在的数据集。我转而检查更新表的代码:

我再次通过日志获取真实的请求语句:

该语句也是正确的!id似乎是自增的字段,因此会自动设置。
不过同时,该语句也暴露了潜在的问题:它一定在没有检查唯一性的情况下重复执行了。带着这种假设,我决定检查一下表的定义:
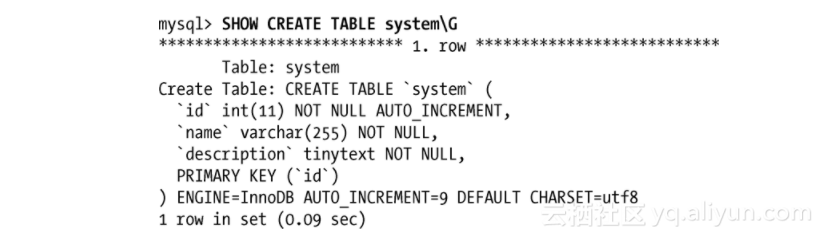
问题的源头很显然了:name字段没有定义成UNIQUE(唯一的)。当创建表的时候,我通常使用id作为唯一标识符,但是我也会使用MySQL的特性在INSERT时去给id生成一个自增的值,没有什么使我避免重复使用同一个name。
为了解决这个问题,我手动删除了多余的行并且增加了唯一(UNIQUE)索引。

我们已经介绍完了与错误结果相关的问题,接下来将介绍其他一些经常发生的问题。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

