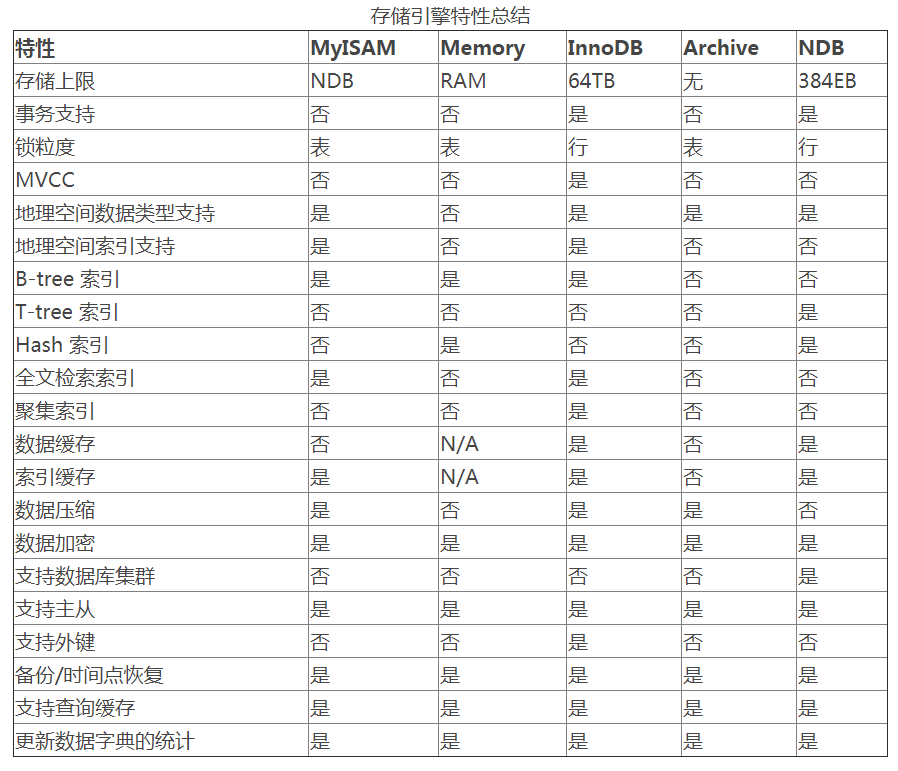
MySql 5.6 所支持的存储引擎
- InnoDB:MySql 5.6 版本默认的存储引擎。InnoDB 是一个事务安全的存储引擎,它具备提交、回滚以及崩溃恢复的功能以保护用户数据。InnoDB 的行级别锁定以及 Oracle 风格的一致性无锁读提升了它的多用户并发数以及性能。InnoDB 将用户数据存储在聚集索引中以减少基于主键的普通查询所带来的 I/O 开销。为了保证数据的完整性,InnoDB 还支持外键约束。
- MyISAM:表级别的锁定限制了它在读写负载方面的性能,因此它经常应用于只读或者以读为主的数据场景。
- Memory:在内存中存储所有数据,应用于对非关键数据由快速查找的场景。Memory 引擎曾被称为 HEAP 引擎。它的使用案例正在减少:InnoDB 的内存缓冲区为将大部分或全部数据保持在内存提供了一个通用并耐用的方式,NDBCLUSTER 为大分布式数据集提供了快速的 key-value 访问。
- CSV:它的表真的是以逗号分隔的文本文件。CSV 表允许你以 CSV 格式导入导出数据,以相同的读和写的格式和脚本和应用交互数据。由于 CSV 表没有索引,你最好是在普通操作中将数据放在 InnoDB 表里,只有在导入或导出阶段使用一下 CSV 表。
- Archive:黑洞存储引擎,类似于 Unix 的 /dev/null,Archive 只接收但却并不保存数据。对这种引擎的表的查询常常返回一个空集。这种表可以应用于 DML 语句需要发送到从服务器,但主服务器并不会保留这种数据的备份的主从配置中。
- NDB:(又名 NDBCLUSTER)——这种集群数据引擎尤其适合于需要最高程度的正常运行时间和可用性的应用。注意:NDB 存储引擎在标准 MySql 5.6 版本里并不被支持。目前能够支持 MySql 集群的版本有:基于 MySql 5.1 的 MySQL Cluster NDB 7.1;基于 MySql 5.5 的 MySQL Cluster NDB 7.2;基于 MySql 5.6 的 MySQL Cluster NDB 7.3。同样基于 MySql 5.6 的 MySQL Cluster NDB 7.4 目前正处于研发阶段。
- Merge:允许 MySql DBA 或开发者将一系列相同的 MyISAM 表进行分组,并把它们作为一个对象进行引用。适用于超大规模数据场景,如数据仓库。
- Federated:提供了从多个物理机上联接不同的 MySql 服务器来创建一个逻辑数据库的能力。适用于分布式或者数据市场的场景。
- Example:这种存储引擎用以保存阐明如何开始写新的存储引擎的 MySql 源码的例子。它主要针对于有兴趣的开发人员。这种存储引擎就是一个啥事也不做的 "存根"。你可以使用这种引擎创建表,但是你无法向其保存任何数据,也无法从它们检索任何索引。
存储引擎的选择
 其他第三方或社区引擎
其他第三方或社区引擎
XtraDB:是InnoDB的一个改进版本,可以作为InnoDB的一个完美的替代产品。
TokuDB:使用了一种新的叫做分形树(Fractal Trees)的索引数据结构。
Infobright:是最有名的面向列的存储引擎。
Groonga:是一款全文索引引擎。
OQGraph:该引擎由Open Query研发,支持图操作(比如查找两点之间的最短路径)。
Q4M:该引擎在MySQL内部实现了队列操作。
SphinxSE:该引擎为Sphinx全文索引搜索服务器提供了SQL接口。
二、选择合适的引擎
大部分情况下,InnoDB都是正确的选择,可以简单地归纳为一句话“除非需要用到某些InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该优先选择InnoDB引擎”。
除非万不得已,否则建议不要混合使用多种存储引擎,否则可能带来一系列负责的问题,以及一些潜在的bug和边界问题。
如果应用需要不同的存储引擎,请先考虑以下几个因素:
事务:
如果应用需要事务支持,那么InnoDB(或者XtraDB)是目前最稳定并且经过验证的选择。
备份:
如果可以定期地关闭服务器来执行备份,那么备份的因素可以忽略。反之,如果需要在线热备份,那么选择InnoDB就是基本的要求。
崩溃恢复
MyISAM崩溃后发生损坏的概率比InnoDB要高很多,而且恢复速度也要慢。
特有的特性
如果一个存储引擎拥有一些关键的特性,同时却又缺乏一些必要的特性,那么有时候不得不做折中的考虑,或者在架构设计上做一些取舍。
有些查询SQL在不同的引擎上表现不同。比较典型的是:
SELECT COUNT(*) FROM table;
对于MyISAM确实会很快,但其他的可能都不行。
三、应用举例
1、日志型应用
MyISAM或者Archive存储引擎对这类应用比较合适,因为他们开销低,而且插入速度非常快。
如果需要对记录的日志做分析报表,生成报表的SQL很可能会导致插入效率明显降低,这时候该怎么办?
一种解决方法,是利用MySQL内置的复制方案将数据复制一份到备库,然后在备库上执行比较消耗时间和CPU的查询。当然也可以在系统负载较低的时候执行报表查询操作,但应用在不断变化,如果依赖这个策略可能以后会导致问题。
另一种方法,在日志记录表的名字中包含年和月的信息,这样可以在已经没有插入操作的历史表上做频繁的查询操作,而不会干扰到最新的当前表上的插入操作。
2、只读或者大部分情况下只读的表
有些表的数据用于编制类目或者分列清单(如工作岗位),这种应用场景是典型的读多写少的业务。如果不介意MyISAM的崩溃恢复问题,选用MyISAM引擎是合适的。(MyISAM只将数据写到内存中,然后等待操作系统定期将数据刷出到磁盘上)
3、订单处理
涉及订单处理,支持事务是必要的,InnoDB是订单处理类应用的最佳选择。
4、大数据量
如果数据增长到10TB以上的级别,可能需要建立数据仓库。Infobright是MySQL数据仓库最成功的方案。也有一些大数据库不适合Infobright,却可能适合TokuDB。
下面是常用存储引擎的适用环境:
- MyISAM:默认的MySQL插件式存储引擎,它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一
- InnoDB:用于事务处理应用程序,具有众多特性,包括ACID事务支持。
- Memory:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供极快的访问。
- Merge:允许MySQL DBA或开发人员将一系列等同的MyISAM表以逻辑方式组合在一起,并作为1个对象引用它们。对于诸如数据仓储等VLDB环境十分适合。
注意
- InnoDB 在 MySQL 5.7.5 及以后的版本才支持地理空间索引
- InnoDB 通过其自适应哈希索引的特性内置进行哈希索引优化
- InnoDB 在 MySql 5.6.4 及以后版本才能支持 FULLTEXT 索引
- MyISAM 只能在行压缩格式时支持数据压缩。使用了行压缩的 MyISAM 表只读
- InnoDB 表压缩要求 InnoDB Barracuda 文件格式
- MySql 的数据加密是由服务器的加密函数提供,并非存储引擎
- 主从支持、备份/时间点恢复等功能也是由服务器提供,而并非存储引擎

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

