前言
此书是去哪网DBA撰写,含金量比价高,堪称业界的数据库运维的内功心法,用过Inception的小伙伴都用该知道。周末准备充充电。
为了不侵犯原作者的权益,此笔记会用小编自己的话和一些原创以及转载文章进行概念细节上的补充。建议做运维的小伙伴可以去图书馆或者当当进行购买,当然也可以看我的笔记哈~
一、连接的建立与关闭
等待用户连接,并给他分配个线程。
在内部有个函数叫(handle_connections_methods),此函数提供了三种连接方式 a、命名管道、b、套接字 c、共享内存。
这里我们要注意两个参数、max_connections(最大连接数) 、connection_count(当前系统连接数) 这里小编在补充一个参数、wait_timeout(服务器关闭非交互连接之前等待活动的秒数)
我们常在网页中看到的错误关键字“Too many connections”就是因为 connection_count > max_connections.
当用户退出后,服务器没有立马的就销毁该线程,而是将它缓存起来,以后有新的请求过来,会直接交给这个用户使用,可以提高资源的利用率。这个处理机制在代码里的函数叫(handle_one_connection)。所以建议哈,在很多应用中要稍微限制max_connections 的值防止建立的线程太多,从而浪费系统资源。
创建连接的过程
1、首先判断connection_count 是否大于等于Max_connections +1 ,如果是否就将记录数+1 并把新连接存储到连接队列中。
2、然后在查看当前的thread_case 是否有闲置的线程,有的话就唤醒利用起来,如果没有闲置的,就重新创建一个线程。
3、新创建的线程将会将它保存到 show processlist (threads列表)中。
解释:线程池(thread_case)的概念是mysql5.6的一个核心功能,所以低于5.6的很容易出现Too many 错误。还有就是mysql自己不存在连接池的模式,需要第三方来解决,java的我知道有c3p0、dbcp等。so后期维护服务器端的连接管理,也一定要深入了解这些客户端的连接池的技术风险和调优管理。
以下是过往的转载的博客对mysql连接池和调度算法的补充。
以下链接是以上内容的互补
https://www.ztloo.com/2018/01/10/mysql日常故障处理/
https://www.ztloo.com/2017/08/14/2017/08/14/mysql线程池总结一/
https://www.ztloo.com/2017/08/14/mysql线程池总结二/
https://www.ztloo.com/2017/08/14/mysql连接数与线程池调优和算法详解/
https://www.ztloo.com/2017/08/14/mysql-线程池内幕/
二、表缓存的应用
缓存的核心存储还是用到了大家都不陌生的哈希原理。
一般的DBA很少有比较不错的编程功底,so,对哈希表理解的也不深。
从根本角度分析,它就是一个map,数据结构就是很简单的key -value 形式。如何散列、映射的规则,请自行百度。
稍微解释:
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
它的特点是“寻址容易,插入删除也容易的数据结构,详细的自己百度去吧。
重点来啦:mysql表对象的缓存,也是通过hash表来进行管理的。然后其中省略了,部分代码的解释,小编重点关心的还是配置的参数。
底下三个参数在之前的博客,很多次小编都有写过,但是理解度不高,怎么去按照占比和固定公式来设置这三个参数的值。一直是有点小疑问:
1、table_open_case
这是查博客,大家默认的公式:
Open_tables / Opened_tables >= 0.85
Open_tables / table_open_cache <= 0.95
这个是源码中默认数量的处理方式:
table_open_cache = (req_open_files-10-max连接数)/ 2 ,table_open_cache_min)
小编的理解是:请求打开的文件数减去10 再减去max的连接数,除以2为table_open_cache的值。
如果打开文件数量小于max连接数,默认的table_open_cache的值是64.
MYSQL默认的table_open_cache为64,这个数值是偏小的,如果max_connections较大,则容易引起性能问题。
2、table_definition_case (以表的个数为单位)
如果你没有显示的声明其值,它的变化就是(从400+table_open_case /2 到2000的范围 ), 如果table_opne_case大于3千2,table_definition的大小就不变化了。必须要声明式进行配置。这是注意的点。
3、table_open_cache_instances
表缓存实例数,为通过减小会话间争用提高扩展性,表缓存会分区为table_open_cache/table_open_cache_instances大小的较小的缓存实例。DML语句会话只需要锁定所在缓存实例,这样多个会话访问表缓存时就可提升性能(DDL语句仍会锁定整个缓存)。默认该值为1,当16核以上可设置为8或16
之前看到网易DBA,姜承尧发表的一篇博客,比较粗暴的设置了一个常量值4096,不知道他们是按照什么计算出来的,或者完全按照经验以及系统服务器最大负载评估的。 感觉三个值反而跟MaxConnect值关系不大。
table_open_cache = table_definition_case = innodb_open_files =4096
innodb_open_files
作用:限制Innodb能打开的表的数据。
分配原则:如果库里的表特别多的情况,请增加这个。这个值默认是300。
mysql最佳配置文件的生成规则,还是留给广大同学自己来探索吧。
https://www.ztloo.com/2018/01/05/mysql最佳配置文件/
https://www.ztloo.com/2017/05/18/myql优化,启动mysql缓存机制,实现命中率100/
https://www.ztloo.com/2017/08/20/mysql-数据库性能优化之缓存参数优化/
总结: 如果一个表的定义非常大,高并发的情况下,就会建立多个实例化表对象,如果对象个数接近于table_open_cache ,有可能会把内存耗光,并且是不可控的。
so,MySQL数据库就不喜欢字段非常多的大表,很影响性能。建表的时候,一定要考虑,字段的实用性,可拆分性,以最小原则来建表和定义表。
三、数据字典
在低版本的时候,可能mysql 还没有数据字典的概念,甚至通过sql直接查不到相关,库表、巴拉巴拉的相关信息。
在高版本的innodb存储引擎上,有了数据字典的概念以及实现,并提供了4个基本表:
sys_tables 从名字上也能猜到,一个存储所有表的相关信息的表。
sys_index : 一个是存储所有表的索引的表。
sys_fields :存储所有索引中定义的索引列。
sys_columns: 用来存储所有表中的所有列的信息,
四、表空间文件的管理办法
图中的文件,组建成了一个关系型数据库管理系统,每个文件都是相互关联,依赖。
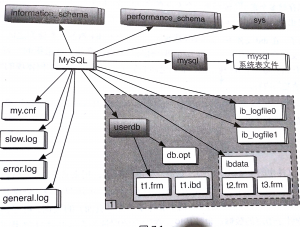
MySQL5.6.7之后默认开启,所以建议就抛弃共享表空间的这种模式,因为他缺点太多。
InnoDB 默认会将所有的数据库InnoDB引擎的表数据存储在一个共享空间中:ibdata1,这样就感觉不爽,增删数据库的时候,ibdata1文件不会自动收缩,单个数据库的备份也将成为问题。
通常只能将数据使用mysqldump 导出,然后再导入解决这个问题。
5.6.7 版本以下的,需要自行开启:innodb_file_per_tablei =1
INNODB 对于表的存储有两种形式
一种是共享表空间,及多张表放在一个文件中,还有一种是独立表空间,每个表都有独立的数据文件。
下面实验分别展示了两种形式
1 共享表空间
1.1 共享表空间配置
1.2.1 查看当前共享表空间
mysql> show variables like '%innodb_data_file_path%' ; +-----------------------+------------------------+ | Variable_name | Value | +-----------------------+------------------------+ | innodb_data_file_path | ibdata1:12M:autoextend | +-----------------------+------------------------+ 1 row in set (0.00 sec)
[root@localhost mysql]# du -h ibdata1 12M ibdata1
1.2.2 增加共享表空间
[root@localhost mysql]# cat /etc/my.cnf [mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock user=mysql # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 innodb_data_file_path=ibdata1:12M;ibdata2:24M:autoextend
1.2.3 查看变更后配置
mysql> show variables like '%innodb_data_file_path%' ; +-----------------------+------------------------------------+ | Variable_name | Value | +-----------------------+------------------------------------+ | innodb_data_file_path | ibdata1:12M;ibdata2:24M:autoextend | +-----------------------+------------------------------------+ 1 row in set (0.00 sec) [root@localhost mysql]# ll total 135200 -rw-rw---- 1 mysql mysql 56 Nov 29 09:45 auto.cnf drwx------ 2 mysql mysql 4096 Nov 29 16:17 dao -rw-rw---- 1 mysql mysql 12582912 Nov 29 16:58 ibdata1 -rw-rw---- 1 mysql mysql 25165824 Nov 29 16:58 ibdata2 -rw-rw---- 1 mysql mysql 50331648 Nov 29 16:58 ib_logfile0 -rw-rw---- 1 mysql mysql 50331648 Nov 29 08:16 ib_logfile1 -rw-rw---- 1 mysql mysql 5 Nov 29 16:58 localhost.localdomain.pid drwx------ 2 mysql mysql 4096 Nov 29 08:16 mysql srwxrwxrwx 1 mysql mysql 0 Nov 29 16:58 mysql.sock drwx------ 2 mysql mysql 4096 Nov 29 08:16 performance_schema -rw-r--r-- 1 root root 117 Nov 29 08:16 RPM_UPGRADE_HISTORY -rw-r--r-- 1 mysql mysql 117 Nov 29 08:16 RPM_UPGRADE_MARKER-LAST drwx------ 2 mysql mysql 4096 Nov 29 16:05 test [root@localhost mysql]# du -h ibdata* 12M ibdata1 24M ibdata2
2 独立表空间
2.1 独立表空间参数
mysql> show variables like '%innodb_file_per_table%' ; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_file_per_table | ON | +-----------------------+-------+ 1 row in set (0.00 sec)
2 查看目录
[root@localhost dao]# ll total 4 -rw-rw---- 1 mysql mysql 65 Nov 29 16:04 db.opt [root@localhost dao]# ls db.opt
3 建表
4 查看目录
[root@localhost dao]# ls dao_table.frm dao_table.ibd db.opt
补充:frm 是数据表的定义,ibd 是innodb表空间数据文件 。 opt是数据库结构定义和设置。
5 文件作用
mysql> use dao ; Database changed mysql> create table dao_table(c1 int) ; Query OK, 0 rows affected (0.04 sec)
6、共享表空间不足的处理方法 (旧版本处理办法,新版本不要尝试)
官方给出的解决方案:
添加和删除 InnoDB 数据和日志文件
这一节描述在InnoDB表空间耗尽空间之时,或者你想要改变日志文件大小之时,你可以做的一些事情。
最简单的,增加InnoDB表空间大小的方法是从开始配置它为自动扩展的。为表空间定义里的最后一个数据文件指定autoextend属性。然后在文件耗尽空间之时,InnoDB以8MB为 增量自动增加该文件的大小。增加的大小可以通过设置innodb_autoextend_increment值来配置,这个值以MB为单位,默认的是8。
作为替代,你可以通过添加另一个数据文件来增加表空间的尺寸。要这么做的话,你必须停止MySQL服务器,编辑my.cnf文件 ,添加一个新数据文件到innodb_data_file_path的末尾,然后再次启动服务器。
如果最后一个数据文件是用关键字autoextend定义的,编辑my.cnf文件的步骤必须考虑最后一个数据文件已经增长到多大。获取数据文件的尺寸,把它四舍五入到最接近乘积1024 × 1024bytes (= 1MB),然后在innodb_data_file_path中明确指定大致的尺寸。然后你可以添加另一个数据文件。记得只有innodb_data_file_path里最后一个数据可以被指定为自动扩展。
作为一个例子。假设表空间正好有一个自动扩展文件ibdata1:
innodb_data_home_dir =innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
假设这个数据文件过一段时间已经长到988MB。下面是添加另一个总扩展数据文件之后的配置行:
innodb_data_home_dir =innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
当你添加一个新文件到表空间的之后,请确信它并不存在。当你重启服务器之时,InnoDB创建并初始化这个文件。
当前,你不能从表空间删除一个数据文件。要增加表空间的大小,使用如下步骤:
1. 使用mysqldump 转储所有InnoDB表。
2. 停止服务器。
3. 删除所有已存在的表空间文件。
4. 配置新表空间。
5. 重启服务器。
6. 导入转储文件。
如果你想要改变你的InnoDB日志文件的数量和大小,你必须要停止MySQL服务器,并确信它被无错误地关闭。随后复制旧日志文件到 一个安全的地方以防万一某样东西在关闭时出错而你需要用它们来恢复表空间。从日志文件目录删除所有旧日志文件,编辑my.cnf来改变日志文件配置,并再 次启动MySQL服务器。mysqld 在启动之时发现没有日志文件,然后告诉你它正在创建一个新的日志文件。
实际中的简化版:
mysql ibdata1存放数据,索引等,是MYSQL的最主要的数据。
如果不把数据分开存放的话,这个文件的大小很容易就上了G,甚至10+G。对于某些应用来说,并不是太合适。因此要把此文件缩小。
方法:数据文件单独存放。
步骤:
1,备份数据库
从命令行进入MySQL Server 5.0bin
备份全部数据库,执行命令mysqldump -q -uusername -pyourpassword --add-drop-table -all-databases > /all.sql
做完此步后,停止数据库服务。
2,修改mysql配置文件
修改my.ini文件,增加下面配置
innodb_file_per_table
对每张表使用单独的innoDB文件, 修改/etc/my.cnf文件
3,删除原数据文件
删除原来的ibdata1文件及日志文件ib_logfile*,删除data目录下的应用数据库文件夹(mysql文件夹不要删)
4,还原数据库
启动数据库服务
从命令行进入MySQL Server 5.0bin
还原全部数据库,执行命令mysql -uusername -pyourpassword < /all.sql
经过以上几步后,可以看到新的ibdata1文件就只有几十M了,数据及索引都变成了针对单个表的小ibd文件了,它们在相应数据库的文件夹下面。
五、InnoDB日志管理
MySQL有多种类型的日志:Error Log、General Query Log、Binary Log 、Slow Query Log、Relay log(slave server)还有undo log/redo log 来实现事务。
查看有哪些mysql日志命令
lsof -nc mysqld | grep -vE '(.so(..*)?$|.frm|.MY?|.ibd|ib_logfile|ibdata|TCP)'
1957是上条命令查出来的pid
lsof -p 1957| grep -vE '(.so(..*)?$)'
对于DBA来说,最重要核心的,redo/ undo 日志是用来做数据库crash recovery 的。
比较核心的概念:LSN,相当于标识日志信息中某行的id。来确定记录日志的信息的位置,每提交一个物理事务,LSN就加1.
物理事务:MTR,它具有ACID性,是针对文件修改,文件读取等物理操作的。深入点说:MTR是Buffer Pool 中的内存Page与文件之间的一个桥梁。
虽说,数据库的核心是日志,任何的数据库恢复和审核都离不开日志。但是最终也会被刷入磁盘变成持久化数据。
那什么时候才能被刷入磁盘呢? 这里有五种时机:
1、首先MTR提交时产生的例子,都会先写入到log buffer中。log buffer 空间用完了,便会将已经产生的log buffer 中的日志刷写到磁盘中。
2、主线程在后台每秒刷新一次,将当前log buffer中的例子刷写到磁盘中。
3、每次执行的DML操作,主动检查日志空间是否足够,如果不够了,就会主动刷写日志,保证在后面真正执行,但此时只会写文件,不会直接刷到磁盘中。 (到底什么时候刷进去,在看源码)
4、做检查点的时候,保证所有页面的lsn最小,最旧的日志已经被刷写到磁盘,如果此时数据库挂了,日志不存在,但数据页面被修改,从而导致数据不一致。
5、提交逻辑事务时候,会因为参数“innodb_flush_log_at_trx_commit”的值不同,而有不同的行为。如果为0,不会刷缓冲区,会造成丢失最新修改的数据。如果为1,会产生强刷到磁盘的行为,保证数据完全不丢失。(这种 设置强刷的操作,会降低数据库的性能。)如果设置为2.则在事务提交时,会将日志刷新到文件中,但不会刷盘。只要操作系统不挂,数据不会丢失。
一般innodb_flush_log_at_trx_commit 设置为2 即可!
【redo log】
在innoDB存储引擎中,redo日志会以ib_logfile0 、ib_logfile1. 来保存。
用于在实例故障恢复时,继续那些已经commit但数据尚未完全回写到磁盘的事务。
The redo log is a disk-based data structure used during crash recovery to correct data written by incomplete transactions.
通常会初始化2个或更多的 ib_logfile 存储 redo log,由参数 innodb_log_files_in_group 确定个数,命名从 ib_logfile0 开始,依次写满 ib_logfile 并顺序重用(in a circular fashion)。
如果最后1个 ib_logfile 被写满,而第一个ib_logfile 中所有记录的事务对数据的变更已经被持久化到磁盘中,将清空并重用之。
在写入量比较高的情况下,redo log 的大小将显著地影响写入性能。
innodb_log_file_size 用来控制 ib_logfile 的大小。5.5版本及以前:默认5MB,最大4G。
所有事务日志累加大小不超过4G,事务日志过大,checkpoint会减少,在节省磁盘io的同时,大的事务日志也意味着数据库crash后,恢复起来较慢。
官方文档建议innodb_log_file_size的设置可参考 show engine innodb status G
Log sequence number -Last checkpoint < (innodb_log_files_in_group * innodb_log_file_size ) * 0.75
【undo log】
记录了数据修改的前镜像。存放于ibdata中。(提一句,DDL操作会修改数据字典,该信息也存放在ibdata中)
当我们对数据进行操作的时候,就会产生undo记录,Undo记录默认记录在系统表空间(ibdata)中,从MySQL 5.6开始,Undo使用的表空间可以分离为独立的Undo log文件。
用于在实例故障恢复时,借助undo log将尚未commit的事务,回滚到事务开始前的状态。
redo日志、undo日志:
存储引擎也会为redo undo日志开辟内存缓存空间,log buffer。磁盘上的日志文件称为log file,是顺序追加的,性能非常高,注:磁盘的顺序写性能比内存的写性能差不了多少。
undo日志用于记录事务开始前的状态,用于事务失败时的回滚操作;redo日志记录事务执行后的状态,用来恢复未写入data file的已成功事务更新的数据。例如某一事务的事务序号为T1,其对数据X进行修改,设X的原值是5,修改后的值为15,那么Undo日志为<T1, X, 5>,Redo日志为<T1, X, 15>。
梳理下事务执行的各个阶段:
(1)写undo日志到log buffer;
(2)执行事务,并写redo日志到log buffer;
(3)如果innodb_flush_log_at_trx_commit=1,则将redo日志写到log file,并刷新落盘。
(4)提交事务。
可能有同学会问,为什么没有写data file,事务就提交了?
在数据库的世界里,数据从来都不重要,日志才是最重要的,有了日志就有了一切。
因为data buffer中的数据会在合适的时间 由存储引擎写入到data file,如果在写入之前,数据库宕机了,根据落盘的redo日志,完全可以将事务更改的数据恢复。好了,看出日志的重要性了吧。先持久化日志的策略叫做Write Ahead Log,即预写日志。
分析几种异常情况:
innodb_flush_log_at_trx_commit=2(innodb_flush_log_at_trx_commit和sync_binlog参数详解)时,将redo日志写入logfile后,为提升事务执行的性能,存储引擎并没有调用文件系统的sync操作,将日志落盘。如果此时宕机了,那么未落盘redo日志事务的数据是无法保证一致性的。
undo日志同样存在未落盘的情况,可能出现无法回滚的情况。
checkpoint:
checkpoint是为了定期将db buffer的内容刷新到data file。当遇到内存不足、db buffer已满等情况时,需要将db buffer中的内容/部分内容(特别是脏数据)转储到data file中。在转储时,会记录checkpoint发生的”时刻“。在故障回复时候,只需要redo/undo最近的一次checkpoint之后的操作。
以下是对redo ,undo 日志相关的补充,和部分内容来自于以下链接。
https://www.ztloo.com/2017/08/20/mysql5-7-可以回收(收缩)undo-log回滚日志物理文件空间/
https://www.ztloo.com/2017/12/19/mysql-·-引擎特性-·-innodb-mini-transation-2/
https://www.ztloo.com/2017/08/16/mysq-》innodb-日志回滚段崩溃恢复实现详解/
https://blog.csdn.net/taoy86/article/details/79657182
https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html
https://blog.csdn.net/daohengshangqian/article/details/50116493
https://www.cnblogscom/anhaogoon/p/8092756.html

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

