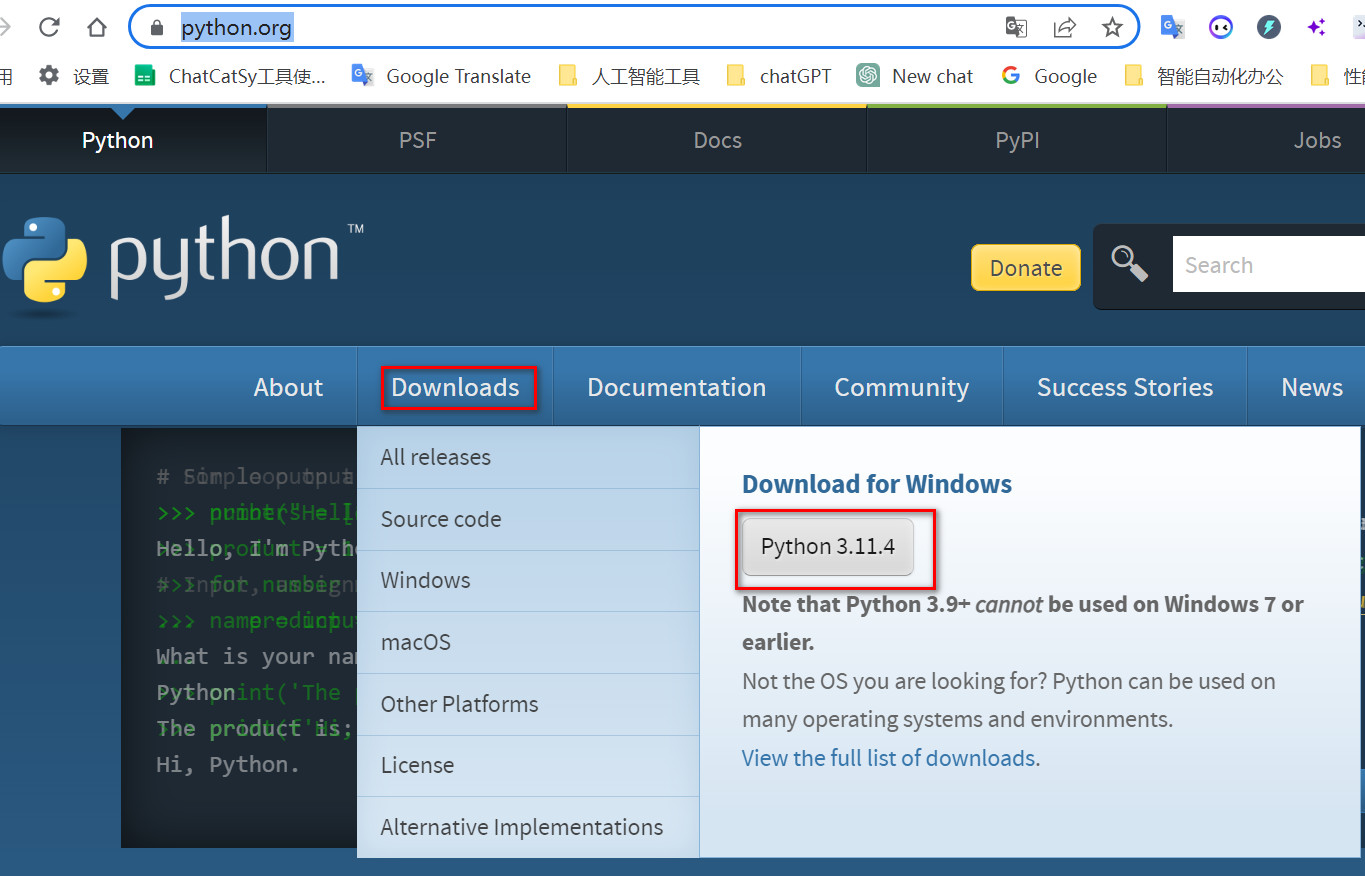
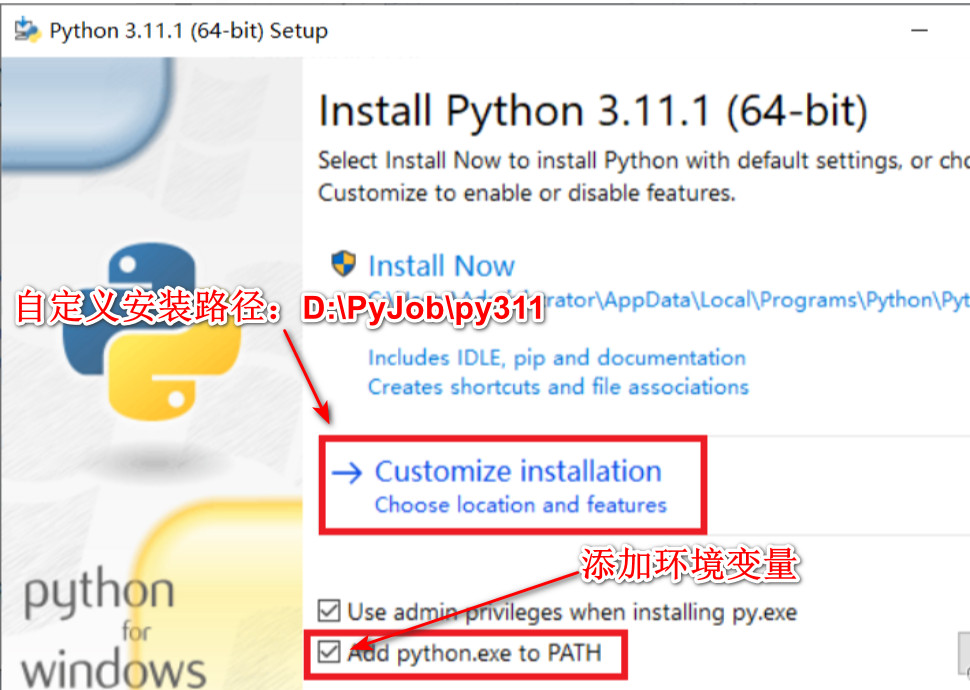
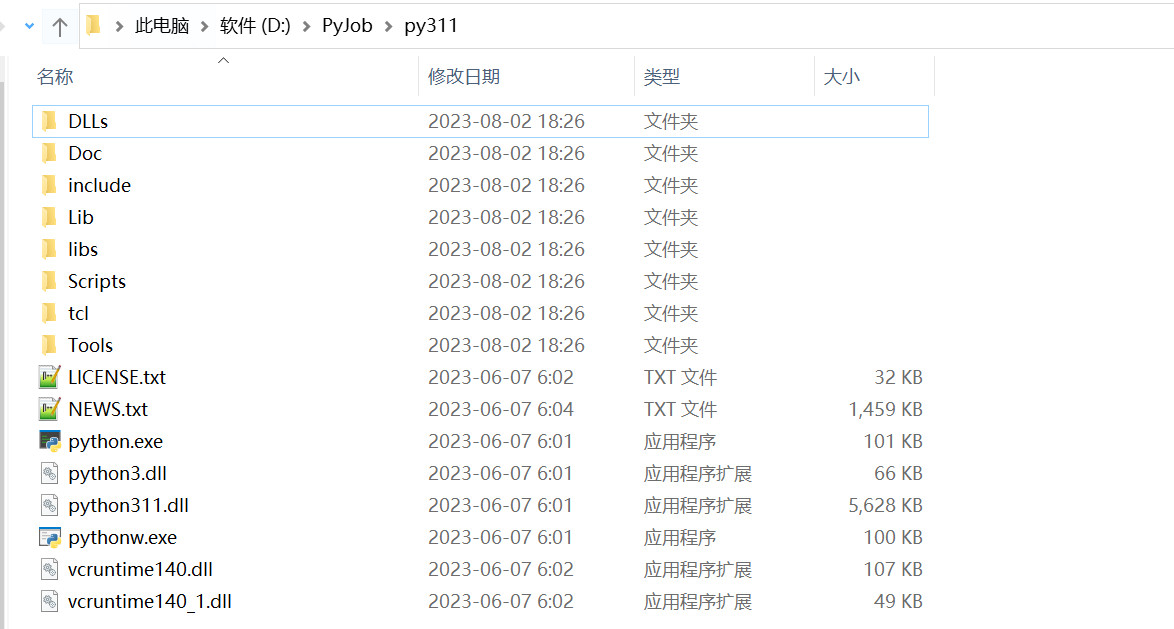
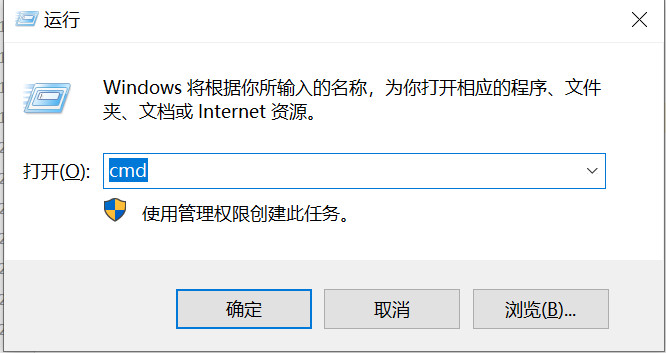
例子1:检查列表中的所有元素是否相等。
def all_equal(lst):
return lst[1:] == lst[:-1]
# 使用例子
all_equal([1, 2, 3, 4, 5, 6]) # False
all_equal([1, 1, 1, 1]) # True
例子2:检查列表中所有的值是否唯一
def all_unique(lst):
return len(lst) == len(set(lst))
# 参考案例
x = [1, 2, 3, 4, 5, 6]
y = [1, 2, 2, 3, 4, 5]
all_unique(x) # True
all_unique(y) # False
例子3:根据元素对应的布尔值,过滤为2组
def bifurcate(lst, filters): # lst:列表 filter:依据的过滤内容
return [
[x for i, x in enumerate(lst) if filters[i] == True],
[x for i, x in enumerate(lst) if filters[i] == False]
]
# 使用案例
bifurcate(['beep', 'boop', 'foo', 'bar'], [True, True, False, True])
# 输出结果: [ ['beep', 'boop', 'bar'], ['foo'] ]
例子4:根据函数将值拆分为两个组,该函数指定输入列表中的元素属于哪个组。
def bifurcate_by(lst, fn):
return [
[x for x in lst if fn(x)],
[x for x in lst if not fn(x)]
bifurcate_by(['beep', 'boop', 'foo', 'bar'], lambda x: x[0] == 'b')
# 输出结果: [ ['beep', 'boop', 'bar'], ['foo'] ]
例子5:将列表分成较小的指定大小的列表。
'''
使用list()和range()创建所需的列表size。
map()在列表上使用并用给定列表的拼接填充它。最后,返回使用创建列表。
'''
from math import ceil
def chunk(lst, size):
return list(
map(lambda x: lst[x * size:x * size + size],
list(range(0, ceil(len(lst) / size)))))
# 使用案例
chunk([1, 2, 3, 4, 5], 2)
# 输出结果:[[1,2],[3,4],5]
例子6:从列表中删除falsey值。
例如 使用filter()过滤掉falsey值(False,None,0和"")。
def compact(lst):
return list(filter(bool, lst))
# 使用案例
compact([0, 1, False, 2, '', 3, 'a', 's', 34])
# 输出结果
[ 1, 2, 3, 'a', 's', 34 ]
例子7:根据给定函数对列表元素进行分组,并返回每个组中元素的数量
def count_by(arr, fn=lambda x: x):
key = {}
for el in map(fn, arr):
key[el] = 0 if el not in key else key[el]
key[el] += 1
return key
# 使用
from math import floor
count_by([6.1, 4.2, 6.3], floor)
# 输出结果
{4: 1, 6: 2}
count_by(['one', 'two', 'three'], len)
# 输出结果
{3: 2, 5: 1}
例子7:计算列表中值的出现次数
def count_occurrences(lst, val):
return len([x for x in lst if x == val and type(x) == type(val)])
# 使用
count_occurrences([1, 1, 2, 1, 2, 3], 1)
# 输出结果
3
例子8:深度压扁列表
'''
使用递归。定义一个函数,spread它使用列表中的每个元素list.extend()或
其中的任何list.append()元素来展平它。
使用list.extend()空列表和spread函数来展平列表。递归地展平作为列表的每个元素。
'''
def spread(arg):
ret = []
for i in arg:
if isinstance(i, list):
ret.extend(i)
else:
ret.append(i)
return ret
def deep_flatten(lst):
result = []
result.extend(
spread(list(map(lambda x: deep_flatten(x) if type(x) == list else x, lst))))
return result
deep_flatten([1, [2], [[3], 4], 5]) # [1,2,3,4,5]
例子9:返回两个iterables之间的差异。
def difference(a, b):
_b = set(b)
return [item for item in a if item not in _b]
difference([1, 2, 3], [1, 2, 4]) # [3]
例子10、将提供的函数应用于两个列表元素后,返回两个列表之间的差异。
def difference_by(a, b, fn):
_b = set(map(fn, b))
return [item for item in a if fn(item) not in _b]
from math import floor
difference_by([2.1, 1.2], [2.3, 3.4], floor)
# [1.2]
difference_by([{'x': 2}, {'x': 1}], [{'x': 1}], lambda v: v['x'])
# [ { x: 2 } ]
例子11、通过函数判断,列表是否满足 lambda表达式,满足的true,不满足的False。
def every(lst, fn=lambda x: not not x):
for el in lst:
if not fn(el):
return False
return True
every([4, 2, 3], lambda x: x > 1) # True
every([2, 2, 3]) # True
例子12、返回列表中的每个第n个元素
def every_nth(lst, nth):
return lst[1::nth]
every_nth([1, 2, 3, 4, 5, 6], 2) # [ 2, 4, 6 ]
例子13、过滤掉列表中的非唯一值。
def filter_non_unique(lst):
return [item for item in lst if lst.count(item) == 1]
filter_non_unique([1, 2, 2, 3, 4, 4, 5]) # [1, 3, 5]
例子14、根据给定的函数对列表的元素进行分组。
def group_by(lst, fn):
groups = {}
for key in list(map(fn, lst)):
groups[key] = [item for item in lst if fn(item) == key]
return groups
import math
group_by([6.1, 4.2, 6.3], math.floor)
# {4: [4.2], 6: [6.1, 6.3]}
例子15、列表中是否存在重复值,
def has_duplicates(lst):
return len(lst) != len(set(lst))
x = [1, 2, 3, 4, 5, 5]
y = [1, 2, 3, 4, 5]
has_duplicates(x) # True
has_duplicates(y) # False
例子16:返回列表的头部。
def head(lst):
return lst[0]
head([1, 2, 3]) # 1
例子17:返回列表中除最后一个元素之外的所有元素。
def initial(lst):
return lst[0:-1]
initial([1, 2, 3])
# [1,2]
例子18:初始化给定宽度和高度以及值的2D列表。
def initialize_2d_list(w, h, val=None):
return [[val for x in range(w)] for y in range(h)]
initialize_2d_list(2, 2, 0) # [[0,0], [0,0]]
例子19: 初始化包含指定范围内的号码,其中的列表start和end已包括其共同差step。
def initialize_list_with_range(end, start=0, step=1):
return list(range(start, end + 1, step))
initialize_list_with_range(5) # [0, 1, 2, 3, 4, 5]
initialize_list_with_range(7, 3) # [3, 4, 5, 6, 7]
initialize_list_with_range(9, 0, 2) # [0, 2, 4, 6, 8]
例子20、使用指定的值初始化并填充列表。
def initialize_list_with_values(n, val=0):
return [val for x in range(n)]
initialize_list_with_values(5, 2) # [2, 2, 2, 2, 2]
例子21、返回两个列表中存在的元素列表。
def intersection(a, b):
_b = set(b)
return [item for item in a if item in _b]
intersection([1, 2, 3], [4, 3, 2]) # [2, 3]
例子22、 将提供的函数应用于两个列表元素后,返回两个列表中存在的元素列表。
def intersection_by(a, b, fn):
_b = set(map(fn, b))
return [item for item in a if fn(item) in _b]
from math import floor
intersection_by([2.1, 1.2], [2.3, 3.4], floor)
# [2.1]
例子23、返回列表中的最后一个元素
def last(lst):
return lst[-1]
last([1, 2, 3]) # 3
24、获取具有length属性的任意数量的可迭代对象或对象,并返回最长的属性
def longest_item(*args):
return max(args, key=len)
longest_item('this', 'is', 'a', 'testcase') # 'testcase'
longest_item([1, 2, 3], [1, 2], [1, 2, 3, 4, 5]) # [1, 2, 3, 4, 5]
longest_item([1, 2, 3], 'foobar') # 'foobar'
25、返回n提供列表中的最大元素
def max_n(lst, n=1):
return sorted(lst, reverse=True)[:n]
max_n([1, 2, 3]) # [3]
max_n([1, 2, 3], 2) # [3,2]
26、返回n提供列表中的最小元素
def min_n(lst, n=1):
return sorted(lst, reverse=False)[:n]
min_n([1, 2, 3]) # [1]
min_n([1, 2, 3], 2) # [1,2]
27、如果提供的函数返回True列表中的至少一个元素,True否则。
def none(lst, fn=lambda x: not not x):
for el in lst:
if fn(el):
return False
return True
none([0, 1, 2, 0], lambda x: x >= 2) # False
none([0, 0, 0]) # True
28、将指定数量的元素移动到列表的末尾。
def offset(lst, offset):
return lst[offset:] + lst[:offset]
offset([1, 2, 3, 4, 5], 2) # [3, 4, 5, 1, 2]
offset([1, 2, 3, 4, 5], -2) # [4, 5, 1, 2, 3]
29、从数组中返回一个随机元素。
from random import randint
def sample(lst):
return lst[randint(0, len(lst) - 1)]
sample([3, 7, 9, 11]) # 9
30、随机化列表值的顺序,返回一个新列表。
from copy import deepcopy
from random import randint
def shuffle(lst):
temp_lst = deepcopy(lst)
m = len(temp_lst)
while (m):
m -= 1
i = randint(0, m)
temp_lst[m], temp_lst[i] = temp_lst[i], temp_lst[m]
return temp_lst
foo = [1, 2, 3]
shuffle(foo) # [2,3,1] , foo = [1,2,3]
31 、返回两个列表中存在的元素列表。
def similarity(a, b):
return [item for item in a if item in b]
similarity([1, 2, 3], [1, 2, 4]) # [1, 2]