摘抄自:Spark大数据分析实战
作者: 高彦杰;倪亚宇
一、日志分析概述
随着互联网的发展,在互联网上产生了大量的Web日志或移动应用日志,日志包含用户最重要的信息,通过日志分析,用户可以获取到网站或应用的访问量,哪个网页访问人数最多,哪个网页最有价值、用户的特征、用户的兴趣等。
一般中型的网站(10万的PV[注释]以上),每天会产生1GB以上Web日志文件。大型或超大型的网站,可能每小时就会产生500GB~1TB的数据量。
对于日志的这种规模的数据,通过Spark进行大规模日志分析与日志处理,能够达到很好的效果。
Web日志由Web服务器产生,现在互联网公司使用的主流的服务器可能是Nginx、Apache、Tomcat等。从Web日志中,我们可以获取网站每类页面的PV值(页面浏览)、UV(独立IP数)。更复杂一些的,可以计算得出用户所检索的关键词排行榜、用户停留时间最高的页面等。更为复杂的,构建广告点击模型、分析用户行为特征等。
键词排行榜、用户停留时间最高的页面等。更为复杂的,构建广告点击模型、分析用户行为特征等。
1.日志格式
目前常见的Web日志格式主要由两类:一种日志格式是Apache的NCSA日志格式,另一种日志格式是IIS的W3C日志格式。
下面以Nginx日志格式为例进行讲解。
Nginx日志示例格式:
222.68.172.111 - - [18/Sep/2013:06:49:57 +0000]
"GET /images/my.jpg HTTP/1.1" 200 19939
"http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
以下是本例中涉及的一些要素。
·remote_addr:记录客户端的IP地址。本例为222.68.172.111。
·remote_user:记录客户端用户名称,本例--表示为空。
·time_local:记录访问时间与时区,本例为[18/Sep/2013:06:49:57+0000]。
·request:记录请求的URL与HTTP协议,本例为GET/images/my.jpg HTTP/1.1。
·status:记录请求状态,成功是200。
·body_bytes_sent:记录发送给客户端文件主体内容大小,本例中为19939。
·http_referer:用来记录从哪个页面链接访问过来的,http://www.angularjs.cn/A00n。
·http_user_agent:记录客户浏览器的相关信息,本例中为Mozilla/5.0(Windows NT 6.1)AppleWebKit/537.36(KHTML,like Gecko)Chrome/29.0.1547.66 Safari/537.36。
注意 如果用户想要更多的信息,则要用其他手段去获取,通过JS代码单独发
送请求,并使用cookies记录用户的访问信息。
通过利用这些日志信息,我们可以深入分析用户行为或网站状况了。
2.传统单机日志数据分析示例
当数据量较小(10MB,100MB,10GB),单机处理能够解决,可以通过各种Unix/Linux命令或者工具,awk、grep、sort、join等都是日志分析的利器,再配合Perl、Python、正则表达式,基本就可以解决常见日志分析的问题。
(1)Linux Shell进行单机日志分析示例
例如,想从上面提到的nginx日志中得到访问量最高的前10个IP,通过以下Shell进行分析:
cat access.log.10 | awk '{a[$1]++} END {for(b in a) print b"\t"a[b]}'
| sort -k2 -r | head -n 10
163.177.71.12 972
101.226.68.137 972
183.195.232.138 971
50.116.27.194 97
14.17.29.86 96
61.135.216.104 94
61.135.216.105 91
61.186.190.41 9
59.39.192.108 9
220.181.51.212 9
(2)Python进行单机日志分析示例
检查Nginx的日志文件,统计基于每个独立IP地址的点击率,代码如下:
#!/usr/bin/env python#coding:utf8
import re
import sys
contents = sys.argv[1]def NginxIpHite(logfile_path):
#IP:4个字符串,每个字符串为1~3个数字,由点连接
ipadd = r'\.'.join([r'\d{1,3}']*4)
re_ip = re.compile(ipadd)
iphitlisting = {}
for line in open(contents):
match = re_ip.match(line)
if match:
ip = match.group( )
#如果IP存在增加1,否则设置点击率为1
iphitlisting[ip] = iphitlisting.get(ip, 0) + 1
print iphitlisting
NginxIpHite(contents)
运行并打印结果如下:
[root@chlinux 06]# ./nginx_ip.py access_20140610.log
{'183.3.121.84': 1, '182.118.20.184': 2, '182.118.20.185': 1, '190.52.120.38': 1, '182.118.20.187': 1, '202.108.251.214': 2, '61.135.190.101': 2, '103.22.181.247': 1, '101.226.33.190': 3, '183.129.168.131': 1, '66.249.73.29': 26, '182.118.20.202': 1, '157.56.93.38': 2, '219.139.102.237': 4, '220.181.108.178': 1, '220.181.108.179': 1, '182.118.25.233': 4, '182.118.25.232': 1, '182.118.25.231': 2, '182.118.20.186': 1, '174.129.228.67': 20}
此脚本返回的是一个Key-Value映射,包含访问Nginx服务器的各个IP的点击数。用户可以通过这个示例再进行深入拓展,进行更丰富的日志信息和知识的获取。
(3)大规模分布式日志分析情况
当数据量每天以10GB、100GB增长的时候,单机处理能力已经不能满足需求。此时就需要增加系统的扩展性,用大数据分析和并行计算来解决。在Spark出现之前,海量数据存储和海量日志分析都是基于Hadoop、Hive等数据分析系统的。Spark的出现,使得全栈数据分析更加容易。并且,Spark非常适合构建多范式日志分析流水线。我们将介绍如何使用Spark构建日志分析流水线。
二、日志分析指标
下面将介绍常用网站的运营数据分析指标。在数据越来越重要的趋势下,数据化运营已经提上互联网公司的日程,如果监控网站或应用的状况时发现瓶颈问题,我们需要针对网站或应用相关指标进行统计和分析得出的。随着移动互联网的发展,越来越多的移动数据分析公司与工具也不断涌现,其中代表性的为友盟、Talking Data等,为公司提供数据化运营支持。
网站运行日志分析常用指标如下:
·PV(Page View):网站页面访问数,也称作网站流量。
·UV(Unique Visitor):页面IP的访问量统计,访问用户数,即独立IP。
·PVPU(Page View Per User):平均每位用户访问页面数。
·漏斗模型与转化率:漏斗模型指的是多个不同的事件按照一定依赖顺序依次触发的流程中的转化模型。用户通常会对应用中的一些关键路径进行分析。比如注册流程、购物流程、交易流程等。
以电商应用的购物流程为例:1浏览商品页→2放入购物车→3生成订单→4支付订单→5完成交易
·我们可以根据这些关键路径来计算每一步的转化率。转化率指的是完成当前事件的用户中触发下一个依赖事件的用户所占比例。
·留存率:用户在某段时间内开始使用应用,经过一段时间后,仍然继续使用
这个应用的用户被认作是留存。这部分用户占开始新增用户的比例即是留存率。
·用户属性:用户的基本属性和行为特征,将用户打标签,帮助产品进一步的营销与推荐。
最终希望通过一个仪表盘展示出整个网站的统计指标信息,如图4-1所示。
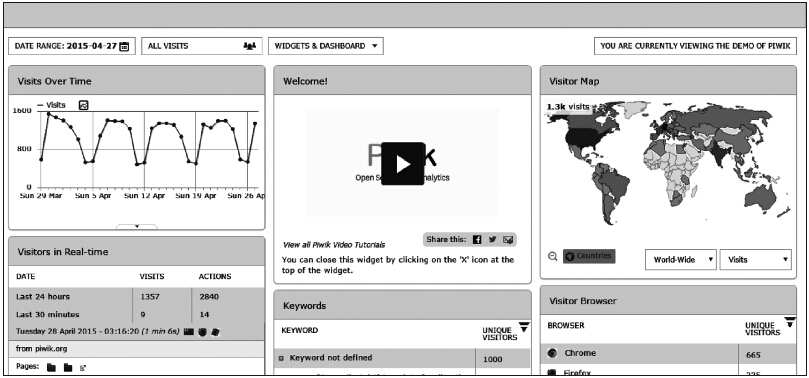
图4-1 日志统计效果图
三、Lamda架构
日志分析中既有离线大规模分析的需求,又有实时性的需求,这就可以通过采用Lamda架构构建日志分析流水线。
1.Lamda架构简介
Lambda架构的目的是为大数据分析应用程序提供一个低响应延迟的组合数据传输环境。
Lambda系统架构定义了一套明确的架构原则,它为建立一套强大的和可扩展的数据系统定义了架构范式。在Lamda架构中,被读取的数据是不可变的,在并行处理过程中数据会依次进入流处理系统和批处理系统,同时进行实时处理和离线数据分析。在查询时,当这两者都返回结果后,才算是完成一次完整的查询。从逻辑上看,传输过程发生了两次,一次是在批处理中,一次是在流处理中。
Lamda架构并不限定其中的具体系统,要根据实际情况进行调整优化。大数据的系统选型具体可以有很多的组合变化。例如可以将图4-2中的Kafka、Storm、Hadoop等换成其他类似的系统,例如Spark Streaming、Spark等,惯常的做法是使用两个数据库来存储数据输出表,一个存储实时表,响应实时查询需求,另外一个存储批处理表,返回离线计算结果。

Lamda数据分析架构
它是由三层组成:批处理层、服务层和速度层。
①批处理层:Hadoop、Spark、Tez等都可以作为批处理层的处理工具,HDFS、HBase等都可以作为数据持久化系统。
①批处理层:Hadoop、Spark、Tez等都可以作为批处理层的处理工具,HDFS、HBase等都可以作为数据持久化系统。
②服务层:用于加载和实现数据库中的批处理视图,以便用户能够查询,不一定需要随机写,但是支持批更新和随机读,例如采用ElephantDB、Voldemort。
③快速处理层:主要处理新数据和服务层更新造成的高延迟补偿,利用流处理系统(如Storm、S4、Spark Streaming)和随机读写数据存储库来计算实时视图(HBase)。批处理和服务层定期处理和转换实时视图为批处理视图。
为了获得一个完整结果,批处理和实时视图都必须被同时查询和融合(实时代表新数据)。
下面借鉴Lamda架构,设计整个数据分析流水线架构,如图4-3所示。
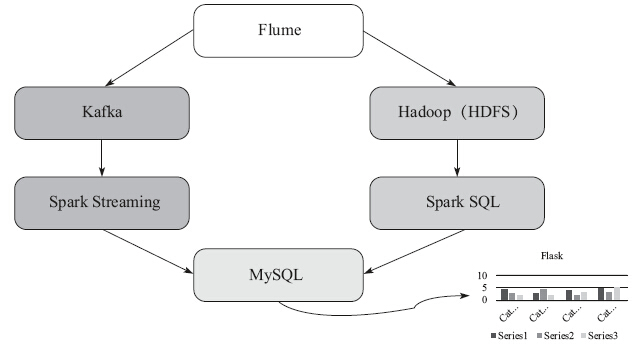
图4-3 日志分析流水线整体架构图
本例中实时日志分析流水线大致按以下步骤操作。
①数据采集:采用Flume NG进行数据采集。
②数据汇总与转发:通过Flume将数据转发汇总到实时消息系统Kafka。
③数据处理:采用Spark Streaming进行实时数据处理
④结果呈现:采用Flask作为可视化呈现工具进行结果呈现。
离线日志分析流水线大致按以下步骤操作。
①数据存储:通过Flume将数据转储到HDFS。
②数据处理:通过Spark SQL进行数据预处理。
③结果呈现:结果汇总存储到MySQL最后通过Flask进行结果呈现。
四、构建日志分析数据流水线
后续的章节将介绍日志数据采集、日志数据汇总、日志实时分析、日志离线分析及可视化,来构建数据分析流水线。
4.4.1 用Flume进行日志采集
Web日志由Web服务器产生,生产环境的服务器可能是Nginx、Apache、To
mcat、IIS等。
例如,可以将Tomcat的日志收集到指定的目录,Tomcat安装在/opt/tomcat,日志存放在var/log/data。其他服务器(如Apache、Nginx、IIS等),用户可以根据相应服务器的默认目录进行相关配置。
1.Flume简介
Flume是Cloudera开发的日志收集系统,具有分布式、高可用等特点,为大数据日志采集、汇总聚合和转储传输提供了支持。为了保证Flume的扩展性和灵活性,在日志系统中定制各类数据发送方及数据接收方。同时Flume提供对数据进行简单处理,并写各种数据到接受方的能力。
Flume的核心是把数据从数据源收集过来,再送到数据接收方。为了保证送达成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume传输的数据的基本单位是事件(Event),如果是文本文件,通常是一行记录,这也是事务的基本单位。事件(Event)从源(Source)传输到通道(Ch
annel),再到数据输出槽(Sink),本身为一个比特(byte)数组,并可携带消息头(headers)信息。
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是Source、Channel、Sink。通过这些组件,Event可以从一个地方流向另一个地方,如图4-4所示。
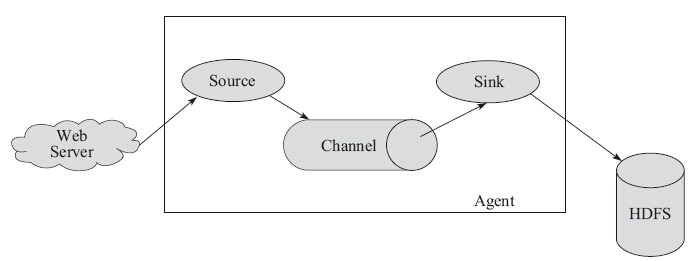
图4-4 Flume架构
Flume核心组件如下。
·Source可以接收外部源发送过来的数据。不同的Source,可以接受不同的数据格式。比如有目录池(Spooling Directory)数据源,可以监控指定文件夹中
的新文件变化,如果目录中有文件产生,就会立刻读取其内容。
·Channel是一个存储地,接收Source的输出,直到有Sink消费掉Channel中的数据。Channel中的数据直到进入到下一个Channel中或者进入终端才会被删除。当Sink写入失败后,可以自动重启,不会造成数据丢失,因此很可靠。
·Sink会消费Channel中的数据,然后送给外部源或者其他Source。如数据可以写入到HDFS或者HBase中。
Flume允许多个Agent连在一起,形成前后相连的多级数据传输通道。
2.Flume安装与配置
(1)安装Flume
1)安装JDK。
2)安装Flume。
http:// mirrors.cnnic.cn/apache/flume/1.5.0/apache-flume-1.5.0-bin.tar.gz
。
# tar xvzf apache-flume-1.5.0-bin.tar.gz
# mv apache-flume-1.5.0-bin apache-flume-1.5.0
# ln -s apache-flume-1.5.0 flume
3)环境变量设置。
# vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export FLUME_HOME=/usr/local/flume
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=.:$PATH::$FLUME_HOME/bin
# source /etc/profile
(2)创建Agent配置文件将数据输出到HDFS
这需要修改flume.conf中的配置,具体如下:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述和配置
source
#第1步:配置数据源
a1.sources.r1.type = exec
a1.sources.r1.channels = c1
#配置需要监控的日志输出目录
a1.sources.r1.command = tail -F /var/log/data
# Describe the sink
#第2步:配置数据输出
a1.sinks.k1.type=hdfs
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.path=hdfs://192.168.11.177:9000/flume/events/%Y/%m/%d/%H/%M
a1.sinks.k1.hdfs.filePrefix=cmcc
a1.sinks.k1.hdfs.minBlockReplicas=1
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.rollInterval=60
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=0
# Use a channel which buffers events in memory
#第3步:配置数据通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
#第4步:将三者级联
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(3)启动Flume Agent
# cd /usr/local/flume
# nohup bin/flume-ng agent -n agent1 -c conf -f conf/flume-conf.properties &
通过上面介绍的一系列步骤,已经可以将Flume收集的数据输出到HDFS。
3.整合Flume与Kafka、HDFS
下面通过Sink设置的修改将Flume的日志输出到HDFS和Kafka。下面的IP地址只是示例,用户根据具体需求改为生产环境中的IP地址。
##############################define [sink] begin###################
#define the sink k1,定义HDFS输出端
a1.sinks.k1.type=hdfs
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.path=hdfs:// 192.168.11.174:9000/flume/events/%Y/%m/%d
a1.sinks.k1.hdfs.filePrefix=cmcc-%H
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.minBlockReplicas=1
a1.sinks.k1.hdfs.rollInterval=3600
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=0
#define the sink k2,定义Kafka输出端
a1.sinks.k2.channel=c2
a1.sinks.k2.type=com.cmcc.chiwei.Kafka.CmccKafkaSink
a1.sinks.k2.metadata.broker.list=192.168.11.174:9092,192.168.11.175:9092,192.168.11.176:9092
a1.sinks.k2.partition.key=0
a1.sinks.k2.partitioner.class=com.cmcc.chiwei.Kafka.CmccPartition
a1.sinks.k2.serializer.class=Kafka.serializer.StringEncoder
a1.sinks.k2.request.required.acks=0
a1.sinks.k2.cmcc.encoding=UTF-8
a1.sinks.k2.cmcc.topic.name=cmcc
a1.sinks.k2.producer.type=async
a1.sinks.k2.batchSize=100
##############################define [sink] end###################
以上配置将同样的数据无差异输出传递到多个输出端。
a1.sources.r1.selector.type=replicating
本例配置了两个输出端:一个是输出到Kafka,为了提高性能,用内存通道。另一个是输出到HDFS,离线分析。
在配置文件中设置两个sink:一个是Kafka的输出通道K2。一个是HDFS的输出通道K1。
a1.sources = r1
a1.sinks = k1 k2
a1.channels=c1 c2
##############################define [channel] begin#################
#define the channel c1,
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/home/flume/flumeCheckpoint
a1.channels.c1.dataDirs=/home/flume/flumeData , /home/flume/flumeDataExt
a1.channels.c1.capacity=2000000
a1.channels.c1.transactionCapacity=100
#define the channel c2
a1.channels.c2.type=memory
a1.channels.c2.capacity=2000000
a1.channels.c2.transactionCapacity=100
##############################define [channel] end##################
大家在配置文件中添加如上信息,即可配置好,同时输出到Kafka和HDFS。
4. 用Kafka将日志汇总
由于Flume收集的数据和后端处理的下游系统之间可能存在多对多的关系,为了解耦合保证数据传输延迟,选用Kafka作为消息中间层进行日志中转。
Apache Kafka是由Apache软件基金会开发的一个开源消息系统项目,由Scala写成。Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apach
a写成。Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator“毕业”。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台[注释]。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。Kafka进行消息保存时会根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外Kafka集群有多个Kafka实例组成,每个实例(Server)成为Broker。无论是Kafka集群,还是Producer和Consumer都依赖Zookeeper来保证系统可用性集群保存一些元(Meta)信息,如图4-5所示。
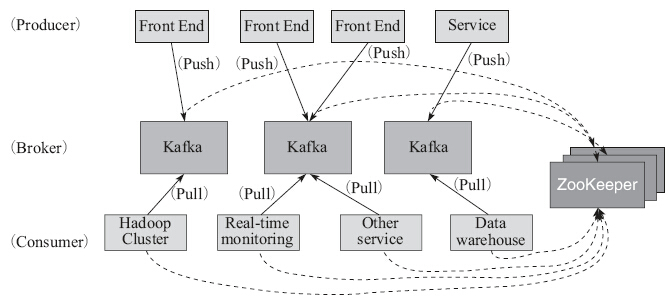
图4-5 Kafka架构图
1).概念和术语
·消息:全称为Message,是指在生产者、服务端和消费者之间传输数据。
·消息代理:全称为Message Broker,通俗来讲就是指该MQ的服务端或者服务器。
·消息生产者:全称为Message Producer,负责产生消息并发送消息到meta服务器。
·消息消费者:全称为Message Consumer,负责消息的消费。
·消息的主题:全称为Message Topic,由用户定义并在Broker上配置。Producer发送消息到某个Topic下,Consumer从某个Topic下消费消息。
·主题的分区:也称为Partition,可以把一个Topic分为多个分区。每个分区是一个有序、不可变的、顺序递增的Commit Log
·消费者分组:全称为Consumer Group,由多个消费者组成,共同消费一个Topic下的消息,每个消费者消费部分消息。这些消费者就组成一个分组,拥有同一个分组名称,通常也称为消费者集群
·偏移量:全称为Offset。分区中的消息都有一个递增的id,称之为Offset。它唯一标识了分区中的消息。
2).部署Kafka
Kafka安装中可以使用自带的Zookeeper,也可以使用外接的Zookeeper,本例以使用自带的Zookeeper为例进行Kafka的部署和安装。
(1)下载Kafka
Kafka官网下载安装包:http://Kafka.apache.org/。
解压:
tar -zxvf Kafka_2.10-0.8.1.1.tgz
(2)配置Kafka与Zookeeper文件
1)配置zookeeper.properties文件。
dataDir=/tmp/zookeeper
clientPort=2181
maxClientCnxns=0
initLimit=5
syncLimit=2
#以下以三台为例,用户可以配置更多的服务器:
server.43=10.190.172.43:2888:3888
server.38=10.190.172.38:2888:3888
server.33=10.190.172.33:2888:3888
2)配置Zookeeper myid。
在每个服务器dataDir中创建myid文件,写入本机ID。
例如:在server.43创建myid文件,并输入主机编号43。
echo "43" > /tmp/zookeeper/myid
3)配置Kafka文件。配置config/server.properties,在每个节点根据不同的主机名进行以下配置。
broker.id:43
#Unique, Write number, Config this node's ID
host.name:10.190.172.43
#Unique,Server IP, Config this node IP
zookeeper.connect= 10.190.172.43:2181,10.190.172.33:2181,10.190.172.38:2181
(3)启动Zookeeper
由于Kafka需要通过Zookeeper存储元数据信息,则预先启动Zookeeper,并
提供给Kafka相应连接地址。
在每台服务器都执行命令:
bin/zookeeper-server-start.sh config/zookeeper.properties
(4)启动Kafka
启动命令:bin/Kafka-server-start.sh。
(5)创建和查看Topic
为了测试部署的Kafka可用性,可以在Kafka中创建和查看Topic并进行可用性的验证。
注意,这里的Topic和Flume中配置的要一致,同时后续Spark Streaming也是消费这个Topic中的数据。
bin/Kafka-topics.sh --create --zookeeper 10.190.172.43:2181--replication-factor 1 --partitions 1 --topic KafkaTopic
查看Topic,验证是否已经创建Topic,如果能够查到,则证明安装正确:bin/Kafka-topics.sh --describe --zookeeper 10.190.172.43:2181
3).整合Kafka与Spark Streaming
在用户的SBT项目中,在build.sbt中添加如下依赖。当应用进行项目编译,便会下载相应驱动进行整合。
libraryDependencies ++= Seq("org.scalatest" %% "scalatest" % "1.9.1" % "test","org.apache.spark" %% "spark-core" % "1.2.0",
"org.apache.spark" %% "spark-streaming" % "1.2.0",
"org.apache.spark" %% "spark-streaming-Kafka" % "1.2.0",
"org.apache.Kafka" %% "Kafka" % "0.8.1.1")
[1]Kafka维基简介:http://zh.wikipedia.org/wiki/Kafka。
4).用Spark Streaming进行实时日志分析
通过之前的整合,已经打通数据收集和中转的通道,数据通过Flume分别流向Kafka和HDFS,在Kafka中的数据,由Spark Streaming消费并进行实时数据分析。对于进入HDFS的数据,后续使用Spark SQL和MLlib进行离线数据分析。
下面介绍Spark Streaming的实时日志分析。
1.Spark Streaming读取Kafka日志
用户可以通过以下几个步骤和代码示例构建读取日志的实时程序,然后启动Spark Streaming的程序并运行。
代码示例通过Spark Streaming接收Kafka的输入数据,构建Kafka流式数据输入。
·进行输入参数的配置。
·初始化Spark Streaming的程序。
·进行日志分析,并启动Spark Streaming程序的运行。
2.实时点击流分析
下面给出一些示例进行点击流(Click Stream)分析,用户可以根据相应示例进行复杂示例拓展。
(1)预定义
定义PageView类,记录站点ID、访客ID、网页的URL。
class PView(val site:String,val visitor:String, val pageurl:String) extends Serializable {}
将每条数据格式化后转换为PageViews对象,便于后续的分析。
val pageviews = logs.map(PView.parseData(_))
(2)统计分析
1)统计每批次指定时间段数据PV。
时间长度根据StreamingContext(sc,Seconds(TimeDuration))中的TimeDuartion进行设置。
val pagecounts = pageviews.map(view => view.pageurl).countByValue()
2)统计过去15s的访客数量,每隔2s计算一次。
val window = Seconds(15)
val interval = Seconds(2)
val visitorcounts = pageviews.window(window,interval).map(view =>
(view.visitor, 1)).groupByKey().map(v => (v._1,v._2.size))
3.实时百分位(Percentile)统计每个用户中段访问量的页面
网站的日常日志分析中,常用的日志分析场景需要观察页面的加载时间:如果页面加载时间过长可能是因为网络的问题,或者服务器的问题;如果页面时间很短则不需要进行优化。往往需要统计加载时间处于中游的页面并进行分析,这样对指定页面进行JS或者后台的优化。
这个分析应用的思路是,统计每个页面和浏览器组的加载延迟,最后统计每个页面和浏览器的加载延迟中排在25%,50%,75%的时间是多长。之后再根据这些信息进行页面的优化和更深入的统计。
4.结果输出到MySQL
应用可以将结果结构化存储到数据库中,便于前端可视化界面进行查询和呈现。
·如果结果较小,将之前的结果收集到Driver,然后JDBC写入到MySQL。
·如果结果较大,可以对每个数据块分别调用JDBC写入结果,然后写入到数据库。
下面将每个分区的数据写入到数据库。
在程序的运行中,可能参数配置并不一定最优,也会使得程序不能达到想要的效果。通过一定参数配置可以缓解和解决相应的问题。Spark Streaming吞吐量不高,可以设置spark.streaming.concurrentJobs进行调整,如果Spark Streaming运行速度突然下降了,经常会有任务延迟和阻塞,可能是设置job启动interval时间间隔太短了,创建的时间窗口间隔太密集了,导致每次job在指定时间无法正常执行完成。
总之在使用Spark Streaming过程中,通过监测、诊断问题,最终达到最好的吞吐和响应延迟。
5 Spark SQL离线日志分析
1.用SQL进行数据ETL[注释]
由于不同格式的日志需要解析出的字段不同,用户可以写自定义的日志解析代码。
本例中解析出的日志模式如下。
日志表模式:
会话ID
用户ID
时间戳
页面URL
访问时间
引用
时间跨度
打分
sessionid | userid | timestamp | pageurl | visittime | referrer | timespent | rating
日志数据:
DJ4XNH6EMMW5CCC5,3GQ426510U4H,1335478060000,/product/N19C4MX1,00:07:40,http://www.healthyshopping.com/product/T0YJZ1QH,44,6
DJ4XNH6EMMW5CCC5,3GQ426510U4H,1335478060000,/product/NL0ZJO2L,00:08:24,http://www.healthyshopping.com/product/T0YJZ1QH,67,6
ZJO2L,00:08:24,http://www.healthyshopping.com/product/T0YJZ1QH,67,6
DJ4XNH6EMMW5CCC5,3GQ426510U4H,1335478060000,/addToCart/NL0ZJO2L,00:09:31,http://www.healthyshopping.com/product/T0YJZ1QH,0,0
X6DUSPR2R53VZ53G,2XXW0J4N117Q,1335478101000,/product/FPR477BM,00:08:21,http://www.google.com,74,6
X6DUSPR2R53VZ53G,2XXW0J4N117Q,1335478101000,/addToCart/FPR477BM,00:09:35,http://www.google.com,0,0
C142FL33KKCV603E,UJAQ1TQWAGVL,1335478185000,/product/7Y4FP655,00:09:45,http://www.twitter.com,0,0
用户可以通过如下Spark SQL代码进行初步的数据清理与处理:
本例查询过滤评分>1的有效用户数据:
select * from pages where rating > 1
通过本例用户可以通过Spark SQL查询分析,或进行数据清洗供后续程序使用。
2.离线会话日志统计
整体代码可以进行一些日志统计分析。其中,会用到LogFlow实现对每个用户会话(Session)的统计,包含开始截止时间、总共访问页面数、最后访问页面等信息,为后续使用贝叶斯模型准备数据。同时这些统计信息也能够实时呈现给用户。
统计常见报表指标:
/*
通过sessionid分组
*/
val dataset = ETL(...).groupBy(group => group._1)
dataset.map(valu => {
/*
根据时间戳对日志记录进行排序
*/
val data = valu._2.toList.sortBy(_._2)
val pages = data.map(_._4)
/*
每个Session的页面点击统计
*/
val total = pages.size
/*
获取开始时间和结束时间等信息
*/
val (sessid,starttime,userid,pageurl,visittime,referrer) = data.head
val endtime = data.last._2
/*
每个Session的时长统计
*/
val timespent = (if (total > 1) (endtime - starttime) / 1000 else 0)
val exitpage = pages(total - 1)
val category = categorize(pages)
new LogFlow(sessid,userid,total,starttime,timespent,referrer,exitpage,
category)
})
//模型类LogFlow,存储相应信息
case class LogFlow(
sessid:String,
userid:String,
total:Int,
starttime:Long,
timespent:Long,
referrer:String,
exitpage:String,
flowstatus:Int
)
代码中的val category=categorize(pages)可根据会话中的统计信息将会话分类。不同的应用场景可以有不同的分类方式,本例进行特定页面点击顺序的预测。可以定义预定义的点击顺序是最终用户点击了重要页面,例如广告、商品购买页面等。表4-1是相关的分类描述。
[图片]表4-1 分类描述

表4-1 分类描述
3.贝叶斯分类预测
在进行实时日志分析的过程中,存在很多的分类问题。通常要进行实时判断,
以区分新来的用户属于哪个类别,进而对其进行实时的推荐,或者进行相应更深入的数据分析。贝叶斯分类是一种常用的分类算法,参见下面相应介绍。
知识拓展:贝叶斯分类简介
在介绍贝叶斯分类之前,先来看看何为分类算法?简单来说,就是将具有某些特性的物体归类对应到一个已知的类别集合中的某个类别上。从数学角度来说,可以做如下定义:
已知集合:C={y1,y2,..,yn}和I={x1,x2,..,xm,..},确定映射规则y=f(x),使得任意xi∈I有且仅有一个yj∈C使得yj=f(xi)成立。
其中,C为类别集合,I为待分类的物体,f则为分类器,分类算法的主要任务就是构造分类器f。
分类算法的构造通常需要一个已知类别的集合来进行训练,通常来说训练出来的分类算法不可能达到100%的准确率。分类器的质量往往与训练数据、验证数据、训练数据样本大小等因素相关。
下面介绍如何基于MLlib中的贝叶斯分类库进行模型训练,并使用模型进行预测。
(1)模型训练
//数据预处理
val parsedData = data.map { line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ')
.map(_.toDouble)))
}
//将数据分为训练集(60%)和测试集(40%)
val splits = parsedData.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0)
val test = splits(1)
//调用MLlib中的贝叶斯分类库,进行模型训练
val model = NaiveBayes.train(training, lambda = 1.0)
val predictionAndLabel = test.map(p => (model.predict(p.features), p.label))
val accuracy = 1.0 * predictionAndLabel.filter(x => x._1 == x._2).count() / test.count()
//保存并加载模型
model.save(sc, "myModelPath")
val sameModel = NaiveBayesModel.load(sc, "myModelPath")
(2)实时分类预测
后续将数据模型应用于实时日志数据分析中,进行用户转化预测。对潜在用户进行更好的服务。
val filteredSessions = sessionLogs.filter(t =>
model.predict(Utils.featurize(t)) == 2)
filteredSessions.print()
通过以上示例,读者可以了解通过构建贝叶斯模型进行分类预测。用户可以根据自身的应用场景进行相应模型的选择。
4.用Flask将日志KPI可视化
最终的统计分析结果,通过可视化工具才能让用户更加直观地进行状况的了解和结果的理解,下面讲解如何通过Flask将日志的KPI可视化。
1.部署安装Flask
①安装Python的MySQL驱动。
可以使用一条简单的指令:
sudo apt-get install python-mysqldb
②编写一个测试语句进行测试。
import MySQLdb
conn = MySQLdb.connect(host='MysqlIP', user='USER',passwd='PASSWD')
conn.select_db('python');
cursor = conn.cursor()
cursor.execute("select * from result")
data = cursor.fetchone()
cursor.close()
conn.close()
print data[1]
③安装Flask。
sudo apt-get install openssh-server
sudo apt-get install python-setuptools
sudo easy_install virtualenv
sudo apt-get install python-virtualenv
sudo easy_install Flask
④写一个Python的测试程序。
hello.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return "Hello World!"
if __name__ == '__main__':
app.run(host='0.0.0.0')
⑤运行python hello.py。
在浏览器中输入http://localhost:5000即可查询程序是否运行良好。
2.Flask结合Highcharts呈现结果
Higcharts是一个优秀的图表可视化库,本例通过Flask调用Highcharts进行图表呈现。Flask程序要定义result_template.html,通过这个HTML可以呈现相关分析结果,调用Highcharts的例子如下:
@app.route('/make/a/chart')def make_chart():
#读取MySQL中的结果数据
data = get_data()
c = Counter
for each in data:
c['AGE'] += 1
highchart_json = {
'chart': {
'type': 'column'
}
'title': {
'text': 'arranged by age'
}
'x-axis': {
'categories': [x for x in c]
}
'series': {
'name': 'Groups By Age',
'data': [c[x] for x in c]
}
}
return render_template('result_template.html', json=highchart_json)
在result_template.html界面中嵌入如下JS代码,使用Flask中传入的数据绘制图表,将结果可视化。
<script type="text/javascript">
var chart_data = {{ highchart_json|tojson|safe }};</script>
<!--下面通过Highcharts示例呈现折线图,代码如下所示-->
<!doctype html>
<html lang="en">
<head>
<script type="text/javascript"
src="http:// cdn.hcharts.cn/jquery/jquery-1.8.3.min.js"></script>
<script type="text/javascript"
src="http:// cdn.hcharts.cn/highcharts/highcharts.js">
</script>
<script type="text/javascript"
src="http:// cdn.hcharts.cn/highcharts/exporting.js">
</script>
<script>
var chart_data = {{ highchart_json|tojson|safe }};
$(function () {
$('#container').highcharts({
Char_data }
)
}
</script>
</head>
<body>
<div id="container"></div> </body>
</html>
结果呈现如图4-6所示。
图4-6 Flask结果呈现
通过本章的介绍,已经可以构建整个基于Spark,Kafka,HDFS的一套日志分析流水线。
4.5 本章小结
本章首先介绍了Web日志分析,对常用的日志格式进行了简介。之后又介绍了Lamda架构,为了组合离线分析和实时分析的优点,可以将日志分析架构设计为Lamda架构。后续对整个日志分析流水线的架构进行介绍,读者可以根据流水线中的各个环节进行其他系统的拓展或者替换,构建自身生产环境的日志分析应用。在本章的后半部分,更加详细地介绍了日志分析的各个环节以及抽象出的处理逻辑,对现实场景进行适当简化,抽取出共性,不同的生产环境产生不同格式的日志以及需要不同的运营分析指标,所以需要定制化的日志处理。
读者通过本章可以初步认识和理解日志分析,其他基于Spark的应用将在后续的章节进行介绍。随着云计算如火如荼的发展,越来越多的公司选择将应用构建于云平台之上,接下来的章节将在云平台上如何进行Spark数据分析进行介绍。S

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


![spark streaming知识总结[优化]-同乐学堂](https://www.ztloo.com/wp-content/uploads/2017/04/63ba4d80dfb07ad447c0682ef688098b-220x76.jpg)




