一、前言
加强sql练习是快速获得数据最有效率的途径,此外我们使用SQL查询不能只使用很简单、最基础的SELECT语句查询。如果想从多个表查询比较复杂的信息,就会使用高级查询实现。常见的高级查询包括多表连接查询、内连接查询、外连接查询与组合查询。
注意:“ 链接查询是SQL查询的核心,链接查询的链接类型选择要依据实际需求。如果使用不当会严重降低查询效率降以及数据库性能。
比较容易入门的例子:http://blog.csdn.net/zhangliangzi/article/details/51395940
重点推荐两个小白自学编程入门网站(高手勿进):http://www.runoob.com/
http://www.yiibai.com/
对于入门灰常有帮助~,比传统的API文档友好太多了!
二、链接查询详解
联接查询是一种常见的数据库操作,即在两张表(或更多表)中进行行匹配的操作。一般称之为水平操作,这是因为对几张表进行联接操作所产生的结果集可以包含这几张表中所有的列。对应于联接的水平操作,一般将集合操作视为垂直操作。
MySQL数据库支持如下的联接查询:
CROSS JOIN(交叉联接)
INNER JOIN(内联接)
OUTER JOIN(外联接)
其他
在进行联接操作时,请牢记第Day1 -Mysql编程学习章描述的逻辑查询处理阶段,尤其是关于联接所涉及的阶段。每个联接都只发生在两个表之间,即使FROM子句中包含多个表也是如此。每次联接操作也只进行逻辑操作的前三个步骤,每次产生一个虚拟表,这个虚拟表再依次与FROM子句的下一个表进行联接,重复上述步骤,直到FROM子句中的表都被处理完为止。
需要注意的是,不同联接类型执行的步骤不同。对于CROSS JOIN,只应用第一个阶段的笛卡儿积。INNER JOIN应用第一和第二个步骤,OUTER JOIN应用所有的前三个步骤。
5.1.1 新旧查询语法
MySQL数据库支持两种不同的联接操作语法。在实际使用中,很少有DBA或开发人员可以观察到或区分出两者的不同。表5-1给出了两种不同的联接查询语法。

熟悉MySQL数据库的DBA和开发人员可能知道两条SQL语句产生的结果是一样的,在哪种场合使用完全取决于个人的习惯。那么两者有区别吗?这个问题就是本小节所要阐述的重点,总地来说本小节将介绍如下内容:产生两种新旧联接查询语法的历史背景。
什么时候使用哪种语法更好?
哪种语法执行得更好?
哪种语法是标准的?
旧语法会不会过时?
SQL(Structured Query Language,结构化查询语言)是用于数据库中的标准数据查询语言,IBM公司最早使用在其开发的数据库系统中。1986年10月,美国国家标准学会(ANSI)对SQL进行规范后,以此作为关系式数据库管理系统的标准语言(ANSI X3.135—1986),1987年在国际标准化组织的支持下成为国际标准。
1989年,ANSI采纳在ANSI X3.135—1989报告中定义的关系数据库管理系统的SQL标准语言,将其称为ANSI SQL 89,该标准替代ANSI X3.135—1986版本。这是最早的ANSI SQL标准,之后又定义了ANSI SQL92、ANSI SQL 99、ANSI SQL 2003。
对于表5-1左侧的SQL联接查询语句,其由ANSI SQL 89标准引入,与新语法的区别是FROM子句中的表名之间用逗号分隔,没有JOIN关键字,也没有ON子句,其语法格式如下:

ANSI SQL 92引入了对外部联接的支持,因此要严格区分ON过滤器和WHERE过滤器的作用,这在第3章已经介绍过,这章将在外部联接中展开更为详细的讨论。
虽然有新旧两种语法,但是MySQL数据库同时支持这两种语法,并保证对所有这两种ANSI SQL标准进行兼容,因此不必担心过时的问题。对于表5-1的两条SQL语句,两者的逻辑查询和物理查询也是相同的。
5.1.2 CROSS JOIN
CROSS JOIN对两个表执行笛卡儿积,返回两个表中所有列的组合。若左表有m行数据,右表有n行数据,则CROSS JOIN将返回m*n行的表。
下面的查询生成了employees数据库的dept_manager表的所有可能的组合。

因为dept_manager表共有24行记录,所以进行CROSS JOIN后共有576行记录。另外,因为是表dept_manager自己与自己进行联接操作,所以一定要指定别名,否则会出现如下的错误:

也可以使用下面的ANSI SQL 89语法来实现相同任务的查询。


对于交叉联接,笔者更喜欢使用ANSI SQL 89语法。这样代码会更短,语法更加易读。不必担心两者的性能,因为正如前面所说的,优化器将为两者生成相同的执行计划。
CROSS JOIN的一个用处是快速生成重复测试数据,因为通过它可以很快地构造m*n*o行的数据。假设要生成网络游戏中用户每天购买道具的订单表,表User代表用户表,表Item代表道具表,可以快速通过如下的CROSS JOIN来生成每个用户购买道具的测试数据。

这里使用了第2章介绍的数字辅助表,用来快速生成7月的所有天数,因此上述SQL语句生成了用户在7月的每天购买所有道具的一些测试数据。假设User表有1000行数据,Item表有100行数据,则一共可以生成310万行的数据(1000*100*31)。
CROSS JOIN的另一个用处是可以作为返回结果集的行号。如对于表dept_emp表,得到额外的行号的结果集,如表5-2所示。
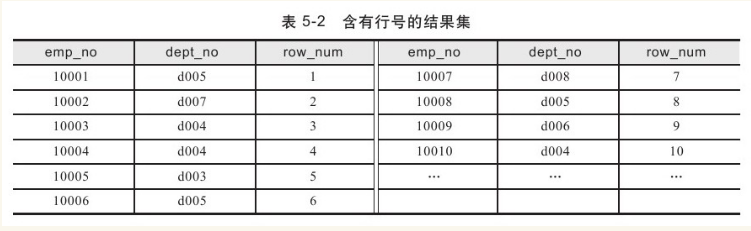
row_num是用户想要得到的行号,解决这个问题可以使用下面子查询的SQL语句:

尽管上述的SQL语句十分简单,也很好理解,执行之后能得到我们需要的行号,可是它运行得非常慢。要理解其中的原因我们可以看如图5-1所示的执行计划。

首先要扫描整个表t1,得到所有的行,大约30多万行。然后将返回的每一行数据与表t2进行联接操作。每次行号计算都会涉及一次子查询的扫描操作。
在如下的子查询中:首先要扫描整个表t1,得到所有的行,大约30多万行。然后将返回的每一行数据与表t2进行联接操作。每次行号计算都会涉及一次子查询的扫描操作。
在如下的子查询中:


第1次返回一行数据,第2次返回二行数据,第3次返回三行数据,……,第N次需返回N行数据,因此扫描的总行数是1+2+3+……+N。你可能还没有意识到将有多少行数据被扫描。对于dept_emp这张一共有30万行的表来说,一共需要扫描15 000 150 000行,150亿行!其实这几乎已经和笛卡儿积的扫描成本一样了(都是O(N2)),对30万行的表进行笛卡儿积也就需要扫描900亿行。
对于这个问题可以用CROSS JOIN来解决。虽然对两个N行表进行笛卡儿积会产生N2行的数据。但是如果是对一行表与N行表进行CROSS JOIN,笛卡尔儿积返回的还是N行数据。因此我们可以使用如下的SQL语句:

这里的SELECT@a:=0产生了只有一行的数据,因此虽然还需要扫描表dept_emp中所有的行,但是每行只和一行数据进行CROSS JOIN,产生一行的记录,这要远快于前面介绍的SQL查询语句。使用CROSS JOIN求解行号问题的执行计划如图5-2所示。

可以看到,表<derived2>只有一行数据,因此用CROSS JOIN查询就大大提高了速度。很明显,这条SQL语句扫描成本为O(N)。
5.1.3 INNER JOIN
通过INNER JOIN用户可以根据一些过滤条件来匹配表之间的数据。在逻辑查询的前三个处理阶段中,INNER JOIN应用前两个阶段,即首先产生笛卡儿积的虚拟表,再按照ON过滤条件来进行数据的匹配操作。INNER JOIN没有第三步操作,即不添加外部行,这是和OUTER JOIN最大的区别之一。也正因为不会添加外部行,指定过滤条件在ON子句和WHERE子句中是没有任何区别的。
如果使用的是ANSI 92语法,则选择在哪个子句中指定过滤条件,用户具有更多的灵活性。因为前面说了,从逻辑上讲,在哪里指定过滤条件都是一样的,通常不会有性能上的差异。唯一的准则就是可读性强。通过一种让DBA、开发人员感觉更自然的方式进行代码编写。例如,在表之间匹配记录的过滤器放在ON子句中,而只从一个表中过滤数据的条件放在WHERE子句中。下面语句实现的是找出部门为d001的经理的用户编号、姓名。

INNER关键字可省略。前面说过,INNER JOIN中WHERE的过滤条件可以写在ON子句中,因此下面的SQL查询语句得到的结果和上面是一样的。

如果使用ANSI 89语法,用户只能在WHERE条件中指定所有的过滤条件,其查询语句如下:

对于CROSS JOIN,笔者喜欢使用ANSI 89语法,而对于INNER JOIN正好相反,更倾向于使用ANSI 92语法。如果忘记指定联接条件,则使用ANSI 89语法可能有些危险,因为可能会得到很大的笛卡儿积返回集,如下面的代码所演示的那样。

特别需要注意的是,在MySQL数据库中,如果INNER JOIN后不跟ON子句也是可以通过语法解析器的,这时INNER JOIN等于CROSS JOIN,即产生笛卡儿积,示例如下:

这一点和很多其他关系数据库非常不同,例如,在Microsoft SQL Server中必须指定ON子句,否则语法解析器会抛出异常。而在MySQL数据库中,CROSS JOIN其实和INNER JOIN是同义词的关系,因此当没有ON子句时,SQL解析器会将INNER JOIN理解为CROSS JOIN。
此外,如果ON子句中的列具有相同的名称,可以使用USING子句来进行简化,得到的结果和上述两语法的语句结果是一样的:


5.1.4 OUTER JOIN
通过OUTER JOIN用户可以按照一些过滤条件来匹配表之间的数据。与INNER JOIN不同的是,在通过OUTER JOIN添加的保留表中存在未找到的匹配数据。MySQL数据库支持LEFT OUTER JOIN和RIGHT OUTER JOIN。与INNER关键字一样,可以省略OUTER关键字。
注意 目前MySQL数据库不支持FULL OUTER JOIN。
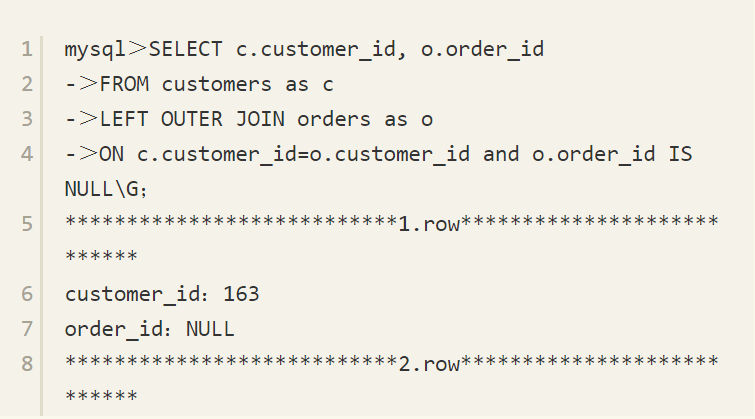
OUTER JOIN应用逻辑查询的前三个步骤,即产生笛卡儿积、应用ON过滤器和添加外部行。对于保留表中的行数据,如果是未找到匹配数据而被添加的记录,其值用NULL进行填充。在第3章的查询处理中我们已经接触过了LEFT JOIN,即返回客户信息、订单信息,同时返回没有订单的客户,因为指定了LEFT关键字,因此表customers是保留表。查询过程如下:


OUTER JOIN只在ANSI SQL 92中得到支持,在其他一些数据库中可以使用(+)=、*=来表示LEFT JOIN,用=(+)、=*来扩展ANSI SQL 89语法使其支持OUTER JOIN。但是对MySQL数据库来说,只有一种OUTER JOIN的联接语法。
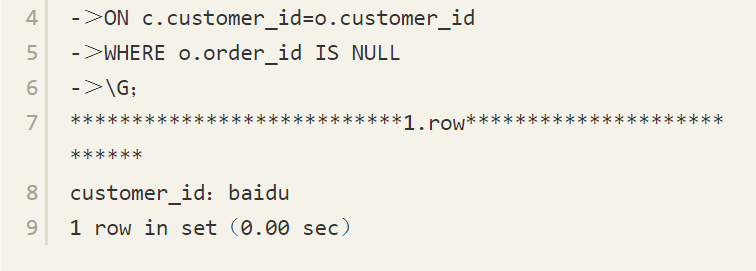
通过OUTER JOIN和IS NULL,可以返回没有用户订单的客户,例如:

可以得到下面一条记录:

需要注意的是,INNER JOIN中的过滤条件都可以写在ON子句中,而OUTER JOIN的过滤条件不可以这样处理,因为可能会得到不正确的结果,例如:
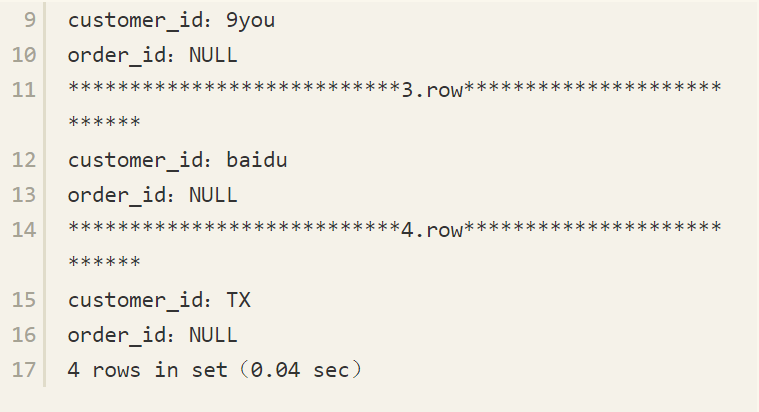
这次得到了4条记录,显然这不是我们想要的结果。
对于OUTER JOIN,同样可以使用USING来简化ON子句,因此上述的语句可以改写为:

与INNER JOIN不同的是,对于OUTER JOIN,必须制定ON子句,否则MySQL数据库会抛出异常,例如:

第4章介绍了用子查询来解决最小缺失值的问题,利用OUTER JOIN同样可以解决该问题。先运行如下代码:


最小缺失值的问题是找出记录中不连续的最小值,在这个例子中显然是4,我们可以通过OUTER JOIN来进行查询,具体的解决方案如下:

该解决方案的第一步是对t表应用LEFT OUTER JOIN,联接的条件是x.a+1=y.a。因为是LEFT OUTER JOIN,所以需要涉及逻辑查询的前三个步骤,笛卡儿积、ON过滤器和WHERE过滤器。首先,忽略WHERE过滤器,看看执行到逻辑查询第二步时虚拟表的情况。ON过滤器的条件是x表中每行a值比y表中每行a值大1,因为使用的是OUTER JOIN,所以未在保留表中存在的行将作为外部行被添加,产生的虚拟表如表5-3所示。

接着,应用WHERE条件,过滤条件为y.a IS NULL,产生虚拟表如表5-4所示。
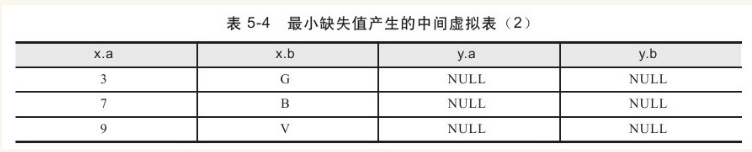
最后应用MIN函数,取出最小的不连续值4。
5.1.5 NATURAL JOIN
ANSI SQL还支持NATURAL JOIN,即自然联接。NATURAL JOIN等同于INNTER JOIN与USING的组合,它隐含的作用是将两个表中具有相同名称的列进行匹配。同样的,NATURAL LEFT(RIGHT)JOIN等同于LEFT(RIGHT)OUTER JOIN与USING的组合。对于下面这句INNER JOIN:

5.1.6 STRAIGHT_JOIN
STRAIGHT_JOIN其实不是新的联接类型,而是用户对SQL优化器的控制,其等同于JOIN。通过STRAIGHT_JOIN, MySQL数据库会强制先读取左边的表。先看一个未使用STRAIGHT_JOIN的SQL语句的执行计划,其SQL语句如下,得到的执行计划如图5-3所示。


可以看到,MySQL数据库先选择b表,也就是dept_manager表,然后进行匹配。这样做的好处是实际只进行了24次行匹配。如果使用STRAIGHT_JOIN,则会强制使用左表,也就是employees表,例如:


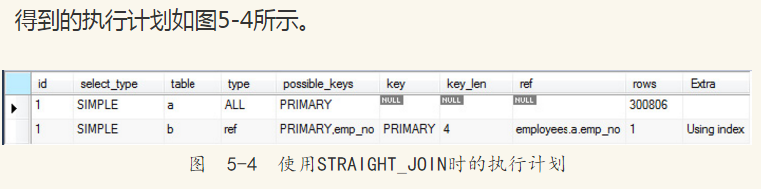
通过图5-4可以看到,MySQL优化器会强制使用左边的表进行匹配,因为左表employees表有大约30多万行的数据,因此一共要匹配30多万次,显然选择的这个联接并不是最有效率的。在笔者的笔记本电脑上,INNER JOIN语句的执行时间为0.3秒,而STRAIGHT_JOIN语句的执行时间为3.3秒。对两张表进行INNER JOIN,通常MySQL数据库的优化器都能工作得很好。但是对于有多张表参与联接的语句,MySQL数据库的优化器选择可能并不总是正确的。这时,对于有经验的DBA,要确定最优的路径,可以使用STRAIGHT_JOIN,强制优化器按照自己的联接顺序来进行联接操作。不过,随着MySQL数据库的不断完善,这种情况正变得越来越少。
5.2 其他联接分类
到目前为止所介绍的都是基本的联接类型。除此之外还有其他几种联接分类方式。这一节将介绍SELF JOIN、NONEQUI JOIN和SEMI JOIN。
5.2.1 SELF JOIN
SELF JOIN是同一个表的两个实例之间的JOIN操作。前面的最小缺失值问题使用的就是SELF JOIN,只是没有显式地进行归类。

显然是表t自己对自己进行JOIN操作。再次提醒,对同一个表进行联接操作必须指定表的别名。下面介绍另外一个常见的使用SELF JOIN的问题——员工—经理问题。先根据下列语句来创建表emp。

在表emp中,emp_no代表员工编号,mgr_no代表员工的上级经理的员工编号。员工—经理问题就是得到每位员工的经理信息。这个问题的解决方案如下:


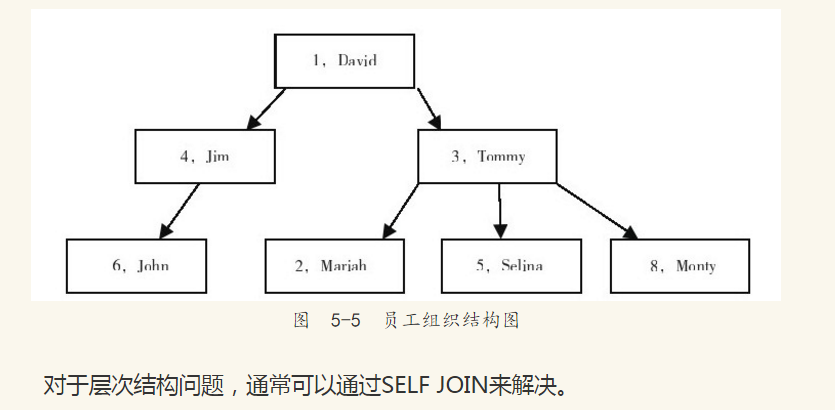
由于David是最高级别的员工,所以他没有经理信息,其manager为NULL。如果再深入地分析员工—经理问题,会发现它其实是一个层次结构问题,表emp表示的员工组织图如图5-5所示。

由于David是最高级别的员工,所以他没有经理信息,其manager为NULL。如果再深入地分析员工—经理问题,会发现它其实是一个层次结构问题,表emp表示的员工组织图如图5-5所示。
5.2.2 NONEQUI JOIN
前面介绍的都是EQUAL JOIN(等值联接),即联接条件是基于“等于”运算符的联接操作。NONEQUI JOIN的联接条件包含“等于”运算符之外的运算符。
要生成dept_manager表中所有两个不同经理的组合,这里先假设当前表中仅包含员工号A、B、C,执行CROSS JOIN后将生成下面九对:(A, A)、(A, B)、(A, C)、(B, A)、(B, B)、(B, C)、(C, A)、(C, B)、(C,C)。
显然,(A, A)、(B, B)和(C, C)包含相同的员工号,不是有效的员工组合。而(A, B)、(B, A)又表示同样的组合。要解决这个问题,可以指定一个左边值小于右边值的联接条件,这样可以移除上述两种情况。该问题的解决方案为:


读者可能对上面的SQL语句有些困惑,这里同样通过A、B、C来加深理解。首先通过与上个例子相反的方法来进行联接(大于等于联接),产生的结果是:(A, A)、(B, A)、(B, B)、(C, A)、(C, B)、(C, C)。然后对左表的列进行分组,就可以得到:(A,1)、(B,2)、(C,3)。这就是我们需要的行号。可以从图5-6中查看该SQL语句的执行计划。

5.2.3 SEMI JOIN和ANTI SEMI JOIN
SEMI JOIN是根据一个表中存在的相关记录找到另一个表中相关数据的联接。如果从左表返回记录,该联接被称为左半联接;如果从右表返回记录,该联接被称为右半联接。实现SEMI JOIN的方法有多种,如内部联接、子查询、集合操作等。在使用内部联接方式时,只从一个表中选择记录,然后应用DISTINCT。下面的SQL查询返回的是来自杭州且发生过订单的客户信息。

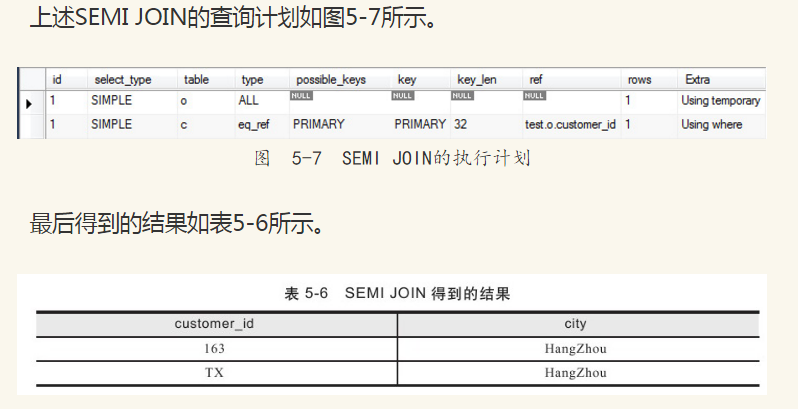
与SEMI JOIN相反的是ANTI SEMI JOIN,它根据一个表中不存在的记录而从另一个表中返回记录。使用OUTER JOIN并过滤外部行,可以实现ANTI SEMI JOIN。例如,下面的SQL查询返回的是来自杭州但没有订单的客户信息。

上述ANTI SEMI JOIN查询的执行计划如图5-8所示。

可以看到所有来自杭州的订单都被访问到。如果来自杭州的客户数量为a,每个消费者的平均订单数为b,则需要访问的订单数是a*b。然后过滤外部行。最后得到的结果如表5-7所示。

5.3 多表联接
前面给出的例子都是关于两表之间的关联。多表联接是查询涉及三张或者更多张表之间的联接查询操作。
对于INNER JOIN的多表联接查询,可以随意安排表的顺序,而不会影响查询的结果。这是因为优化器会自动根据成本评估出访问表的顺序。在该查询的执行计划中,可能会发现优化器访问表的顺序不同于在查询中指定的顺序。
例如,下面的查询返回经理级别员工的编号、姓名、职称,以及所在部门的信息。


这句SQL查询的执行计划如图5-9所示,从图中可以发现SQL优化器并未按照表在查询中的逻辑顺序进行联接。
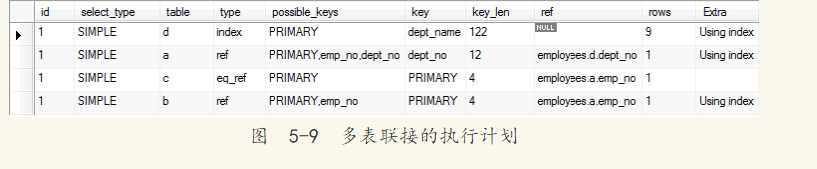
可以看到优化器是按照表d、a、c、b的顺序来对表进行联接的。如果认为不按优化器所选择的顺序联接表会更加高效,可以通过前面介绍的STRAIGHT_JOIN来强制联接处理的顺序,例如:


强制使用STRAIGHT_JOIN进行多表联接的执行计划如图5-10所示,这时就会发现SQL优化器按照指定的顺序进行联接操作:
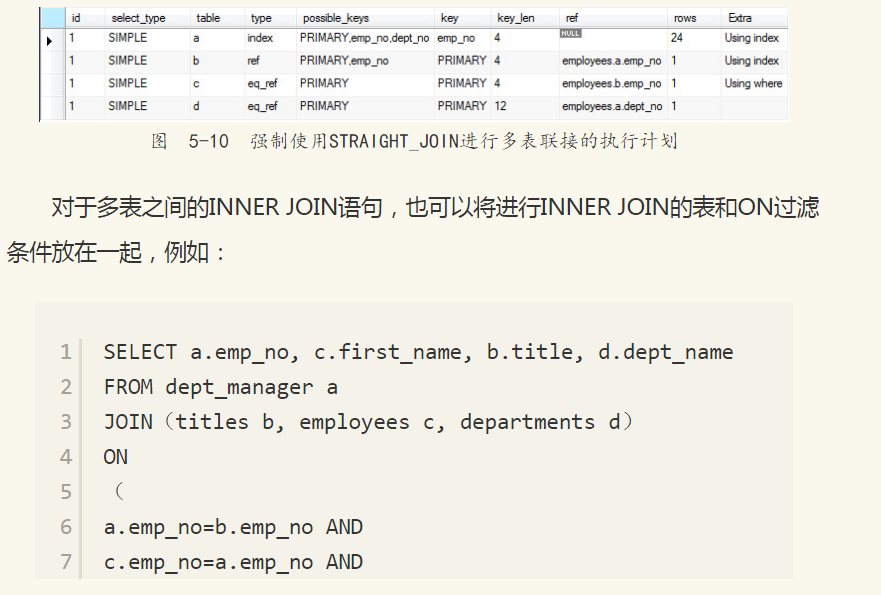

对括号中的表(b、c和d)进行的是CROSS JOIN,然后根据后面的ON过滤条件将联接转换为INNER JOIN,因此上述SQL又等同于:

从语法上来看,多表之间的OUTER JOIN和INNER JOIN操作并没有什么不同。然而,和INNER JOIN不同的是,利用OUTER JOIN进行多表联接的表之间的顺序关系可能会影响最后产生的结果。
5.4 滑动订单问题
在介绍了各种联接类型,以及相应的联接查询后,我们来看一个经典的问题——滑动订单问题,这个问题要涉及上述提及的各个联接问题。先根据以下代码来创建表MonthlyOrders并导入一定的数据。
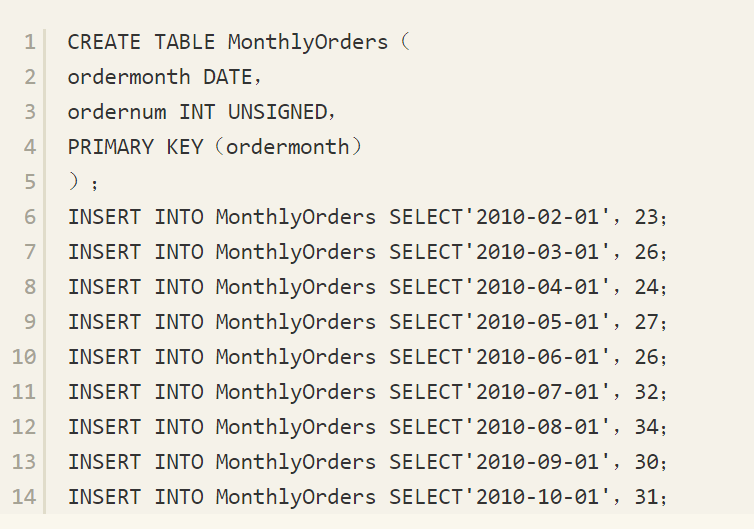
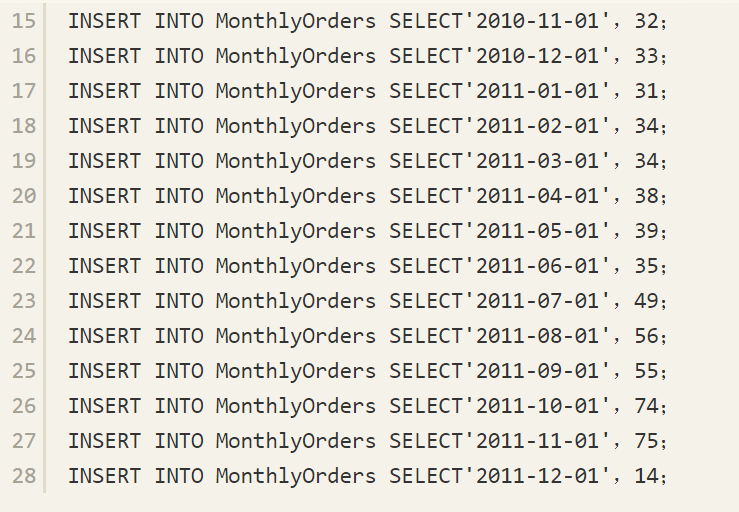
滑动订单问题是指为每个月返回上一年度(季度或月度等)的滑动订单数,即为每个月份N,返回从月份N-11到月份N的订单总数。这里,假设月份序列中不存在间断。
执行下面的SQL查询实现每个月返回上一年度的滑动订单总数,生成的结果如表5-8所示。

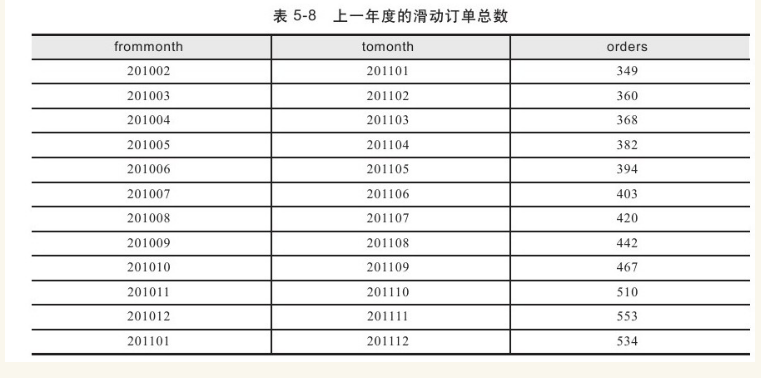
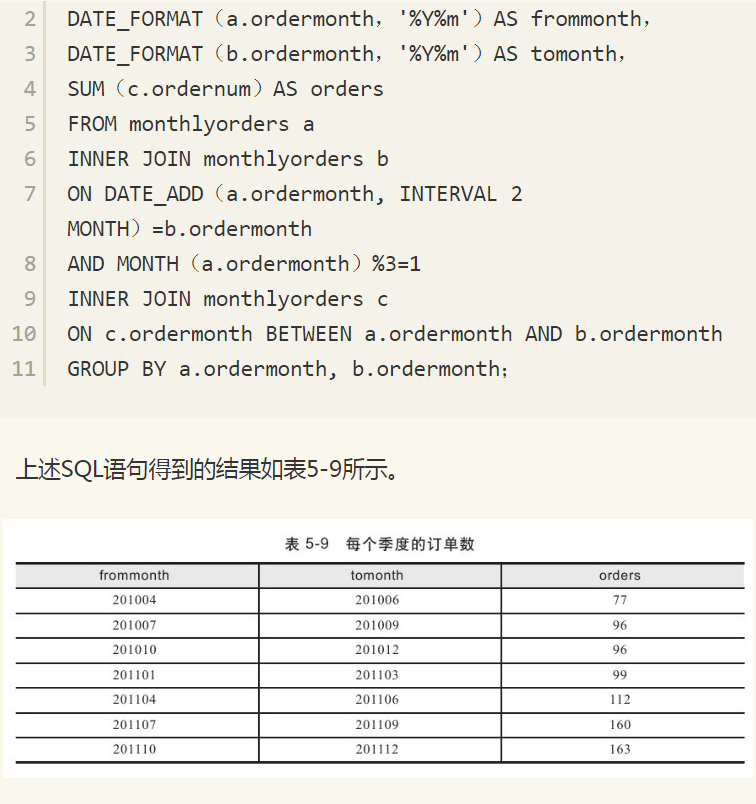
该查询先对MonthlyOrders表进行自联接。a表用做下边界(frommonth),b表用做上边界(tomonth)。联接的条件为:DATE_ADD(a.ordermonth, INTERVAL 11 MONTH)=b.ordermonth。例如,a表中的2010年2月将匹配2011年1月。完成自联接之后,需要对订单进行统计。这时需要再进行一次自联接,得到范围内每个月的订单数量。因此联接的条件为:c.ordermonth BETWEEN a.ordermonth AND b.ordermonth。基于上述方法,我们还可以统计每个季度订单的情况,以此作为环比和同比增长的比较依据。

5.5 联接算法
联接算法是MySQL数据库用于处理联接的物理策略。目前MySQL数据库仅支持Nested-Loops Join算法。而MySQL的分支版本MariaDB除了支持Nested-Loops Join算法外,还支持Classic Hash Join算法。相信不久的将来,MySQL数据库很快也会支持Hash Join、

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

