一、分区
分区是一种表的设计模式。正确的分区可以极大地提升数据库的查询效率,完成更高质量的SQL编程。但是如果错误地使用分区,或者过于迷信分区,那么分区可能带来毁灭性的结果。
本章介绍MySQL数据库中的分区功能,使用户了解何时使用分区及如何正确地使用分区功能。
MySQL支持RANGE,LIST,HASH和KEY四种分区。其中,每个分区又都有一种特殊的类型。对于RANGE分区,有RANGE COLUMNS分区。对于LIST分区,有LIST COLUMNS分区。对于HASH分区,有LINEAR HASH分区。对于KEY分区,有LINEAR KEY分区。具体如下:
RANGE分区
RANGE即范围分区,根据区间来判断位于哪个分区,譬如,在下例中,如果store_id小于6,则新增或修改的记录会被分配到p0分区,如果大于6小于11,则记录会被分配到p1分区,依次类推。类似于编程语言中的if ... elseif ...语句。
格式如下:

CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT NOT NULL, store_id INT NOT NULL ) PARTITION BY RANGE (store_id) ( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION p2 VALUES LESS THAN (16), PARTITION p3 VALUES LESS THAN MAXVALUE );
注意:
1. RANGE分区的返回值必须为整数。
2. PARTITION p3 VALUES LESS THAN MAXVALUE 是非必需的。
RANGE COLUMNS分区
RANGE COLUMNS是RANGE分区的一种特殊类型,它与RANGE分区的区别如下:
1. RANGE COLUMNS不接受表达式,只能是列名。而RANGE分区则要求分区的对象是整数。
2. RANGE COLUMNS允许多个列,在底层实现上,它比较的是元祖(多个列值组成的列表),而RANGE比较的是标量,即数值的大小。
3. RANGE COLUMNS不限于整数对象,date,datetime,string都可作为分区列。
格式如下:
CREATE TABLE rcx ( a INT, b INT, c CHAR(3), d INT ) PARTITION BY RANGE COLUMNS(a,d,c) ( PARTITION p0 VALUES LESS THAN (5,10,'ggg'), PARTITION p1 VALUES LESS THAN (10,20,'mmmm'), PARTITION p2 VALUES LESS THAN (15,30,'sss'), PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE) );
同RANGE分区类似,它的区间范围必须是递增的,有时候,列涉及的太多,不好判断区间的大小,可采用下面的方式进行判断:
mysql> SELECT (5,10) < (5,12), (5,11) < (5,12), (5,12) < (5,12); +-----------------+-----------------+-----------------+| (5,10) < (5,12) | (5,11) < (5,12) | (5,12) < (5,12) |+-----------------+-----------------+-----------------+| 1 | 1 | 0 |+-----------------+-----------------+-----------------+1 row in set (0.07 sec)
关于RANGE COLUMNS的更多说明,可参考MySQL官方文档:
http://dev.mysql.com/doc/refman/5.6/en/partitioning-columns-range.html
LIST分区
LIST即列表分区。
格式如下:
CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY LIST(store_id) ( PARTITION pNorth VALUES IN (3,5,6,9,17), PARTITION pEast VALUES IN (1,2,10,11,19,20), PARTITION pWest VALUES IN (4,12,13,14,18), PARTITION pCentral VALUES IN (7,8,15,16) );
LIST COLUMNS分区
LIST COLUMNS分区同样是LIST分区的一种特殊类型,它和RANGE COLUMNS分区较为相似,同样不接受表达式,同样支持多个列支持string,date和datetime类型。
格式如下:
CREATE TABLE customers_1 ( first_name VARCHAR(25), last_name VARCHAR(25), street_1 VARCHAR(30), street_2 VARCHAR(30), city VARCHAR(15), renewal DATE ) PARTITION BY LIST COLUMNS(renewal) ( PARTITION pWeek_1 VALUES IN('2010-02-01', '2010-02-02', '2010-02-03', '2010-02-04', '2010-02-05', '2010-02-06', '2010-02-07'), PARTITION pWeek_2 VALUES IN('2010-02-08', '2010-02-09', '2010-02-10', '2010-02-11', '2010-02-12', '2010-02-13', '2010-02-14'), PARTITION pWeek_3 VALUES IN('2010-02-15', '2010-02-16', '2010-02-17', '2010-02-18', '2010-02-19', '2010-02-20', '2010-02-21'), PARTITION pWeek_4 VALUES IN('2010-02-22', '2010-02-23', '2010-02-24', '2010-02-25', '2010-02-26', '2010-02-27', '2010-02-28') );
多列格式如下:
CREATE TABLE customers_2 ( first_name VARCHAR(25), last_name VARCHAR(25), street_1 VARCHAR(30), street_2 VARCHAR(30), city VARCHAR(15), renewal DATE ) PARTITION BY LIST COLUMNS(city,last_name,first_name) ( PARTITION pRegion_1 VALUES IN (('Oskarshamn', 'Högsby', 'Mönsterås'),('Nässjö', 'Eksjö', 'Vetlanda')), PARTITION pRegion_2 VALUES IN(('Vimmerby', 'Hultsfred', 'Västervik'),('Uppvidinge', 'Alvesta', 'Växjo')) );
HASH分区
和RANGE,LIST分区不同的是,HASH分区无需定义分区的条件。只需要指明分区数即可。
格式如下:
CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY HASH(store_id) PARTITIONS 4;
注意:
1. HASH分区可以不用指定PARTITIONS子句,如上文中的PARTITIONS 4,则默认分区数为1。
2. 不允许只写PARTITIONS,而不指定分区数。
3. 同RANGE分区和LIST分区一样,PARTITION BY HASH (expr)子句中的expr返回的必须是整数值。
4. HASH分区的底层实现其实是基于MOD函数。譬如,对于下表
CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE) PARTITION BY HASH( YEAR(col3) ) PARTITIONS 4;
如果你要插入一个col3为“2005-09-15”的记录,则分区的选择是根据以下值决定的:
MOD(YEAR('2005-09-01'),4) = MOD(2005,4) = 1
LINEAR HASH分区
LINEAR HASH分区是HASH分区的一种特殊类型,与HASH分区是基于MOD函数不同的是,它基于的是另外一种算法。
格式如下:
CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY LINEAR HASH( YEAR(hired) ) PARTITIONS 4;
说明:
1. 它的优点是在数据量大的场景,譬如TB级,增加、删除、合并和拆分分区会更快,缺点是,相对于HASH分区,它数据分布不均匀的概率更大。
2. 具体算法,可参考MySQL的官方文档
http://dev.mysql.com/doc/refman/5.6/en/partitioning-linear-hash.html
KEY分区
KEY分区其实跟HASH分区差不多,不同点如下:
1. KEY分区允许多列,而HASH分区只允许一列。
2. 如果在有主键或者唯一键的情况下,key中分区列可不指定,默认为主键或者唯一键,如果没有,则必须显性指定列。
3. KEY分区对象必须为列,而不能是基于列的表达式。
4. KEY分区和HASH分区的算法不一样,PARTITION BY HASH (expr),MOD取值的对象是expr返回的值,而PARTITION BY KEY (column_list),基于的是列的MD5值。
格式如下:
CREATE TABLE k1 ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20) ) PARTITION BY KEY() PARTITIONS 2;
在没有主键或者唯一键的情况下,格式如下:
CREATE TABLE tm1 ( s1 CHAR(32) ) PARTITION BY KEY(s1) PARTITIONS 10;
LINEAR KEY分区
同LINEAR HASH分区类似。
格式如下:
CREATE TABLE tk ( col1 INT NOT NULL, col2 CHAR(5), col3 DATE ) PARTITION BY LINEAR KEY (col1) PARTITIONS 3;
总结:
1. MySQL分区中如果存在主键或唯一键,则分区列必须包含在其中。
2. 对于原生的RANGE分区,LIST分区,HASH分区,分区对象返回的只能是整数值。
3. RANGE COLUMNS,LIST COLUMNS,KEY,LINEAR KEY分区对象只能是列,不能是基于列的表达式。
二、分区和性能
有开发人员常说“对表做个分区,这样数据库的查询就会快了”。这是真的吗?实际上根本感觉不到查询速度的提升,甚至会觉得查询速度急剧下降。因此,在合理使用分区之前,必须了解分区的使用环境。 数据库的应用分为两类:一类是OLTP(联机事务处理),如Blog、电子商务、网络游戏等;另一类是OLAP(联机分析处理),如数据仓库、数据集市等。在一个实际的应用环境中,可能既有OLTP的应用,也有OLAP的应用。例如,在网络游戏中,玩家操作的游戏数据库应用就是OLTP的,但是游戏厂商可能需要对游戏产生的日志进行分析,通过分析得到的结果更好地服务于游戏、预测玩家的行为等,而这是OLAP的应用。 对于OLAP的应用,分区的确可以很好地提高查询的性能,因为OLAP应用的大多数查询需要频繁地扫描一张很大的表。假设有一张1亿行的表,其中有一个时间戳属性列,需要从这张表中获取一年的数据。如果按时间戳进行分区,则只需要扫描相应的分区即可。这就是前面介绍的Partition Pruning技术。 然而对于OLTP的应用,在分区时应该非常小心。在这种应用下,通常不可能会获取一张大表中10%的数据,大部分都是通过索引返回几条记录即可。而根据B+树索引的原理可知,对于一张大表,一般的B+树需要2~3次的磁盘IO操作,因此B+树可以很好地完成对大表的查询操作,不需要分区的帮助,更何况设计不好的分区会带来严重的性能问题。 很多开发团队会认为含有一千万行的表是一张非常大的表,所以他们往往会选择分区,例如对主键做10个HASH分区,这样每个分区就只有一百万的数据了,认为这时查询应该变得更快了,比如执行SELECT*FROM TABLE WHERE PK=@pk。但是考虑这样一个问题:如果一百万行和一千万行的数据本身构成的B+树的层次是一样的,可能都是两层,那么上述主键分区的索引并不会带来性能的提高。假设一千万行数据的B+树的高度是3,一百万行数据的B+树的高度是2,这样上述主键分区的索引可以避免一次IO,从而提高查询的效率。这没问题,但是这张表只有主键索引,没有任何其他列需要查询吗?如果还有这样的语句:SELECT*FROM TABLE WHERE KEY=@key,这时对于KEY的查询需要扫描所有的10个分区,即使每个分区的查询开销为2次IO操作,那么一共需要20次IO。而对于原来单表的设计,对KEY的查询只需要2~3次IO操作。
接着来根据主键ID对Profile表进行HASH分区,HASH分区的数量为10,Profile表有接近一千万行的数据。
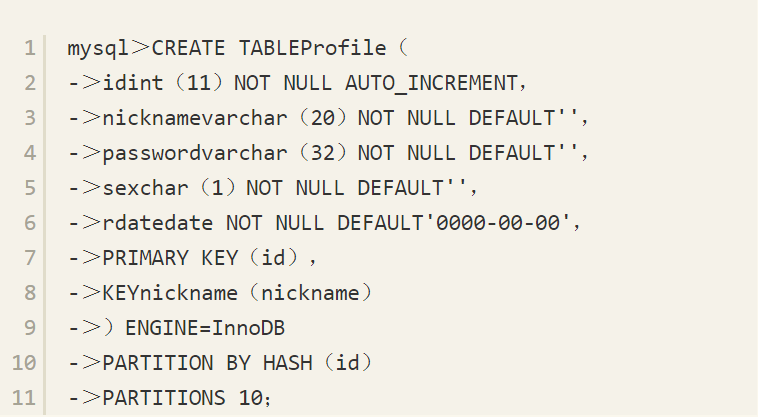

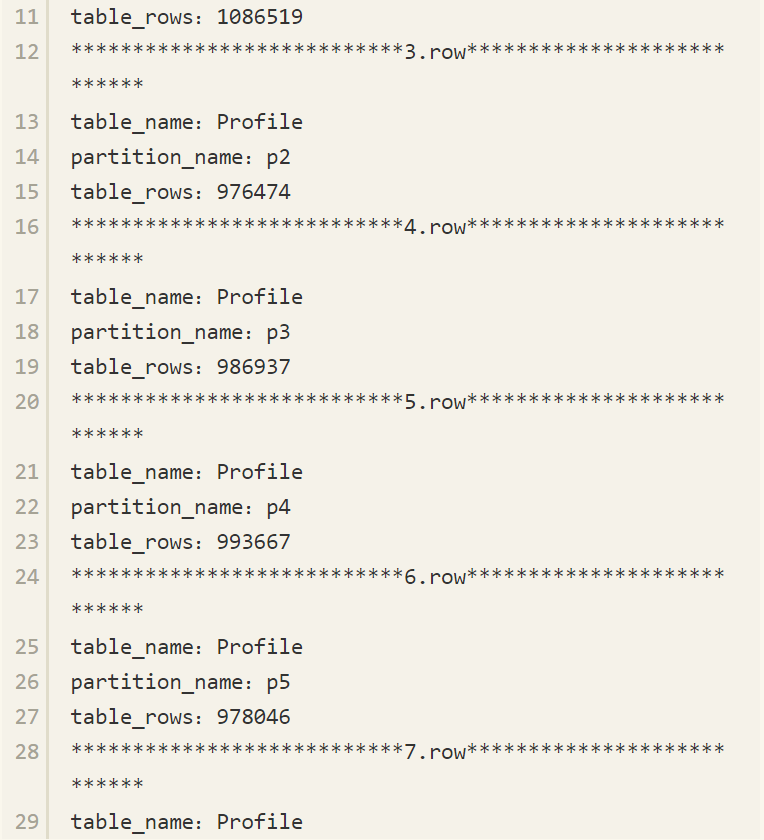
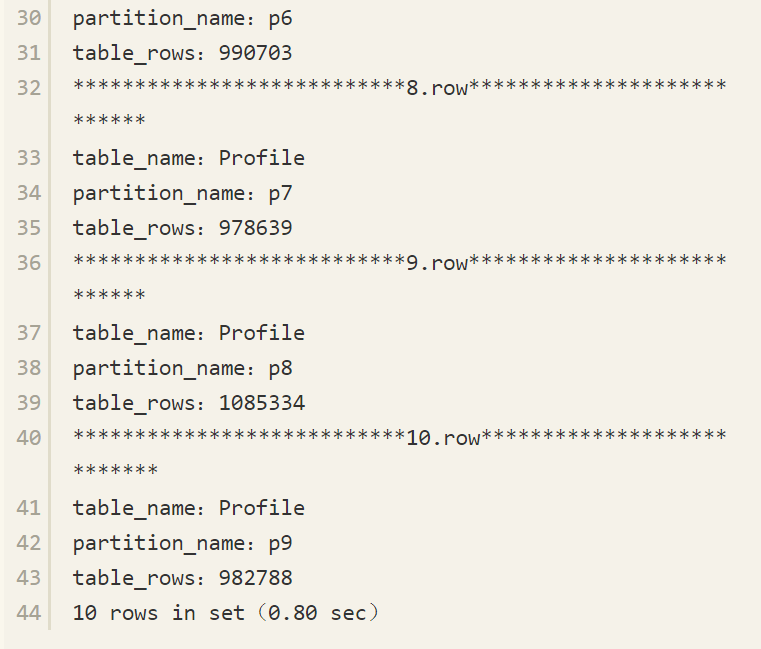
注意 即使是根据自增长主键进行的HASH分区也不能保证分区数据是均匀的,因为插入的自增长ID并非总是连续的,如果该主键值因为某种原因被回滚了,则该值不会再次被自动使用。
如果进行主键的查询,那么可以发现分区的确是有意义的,例如:
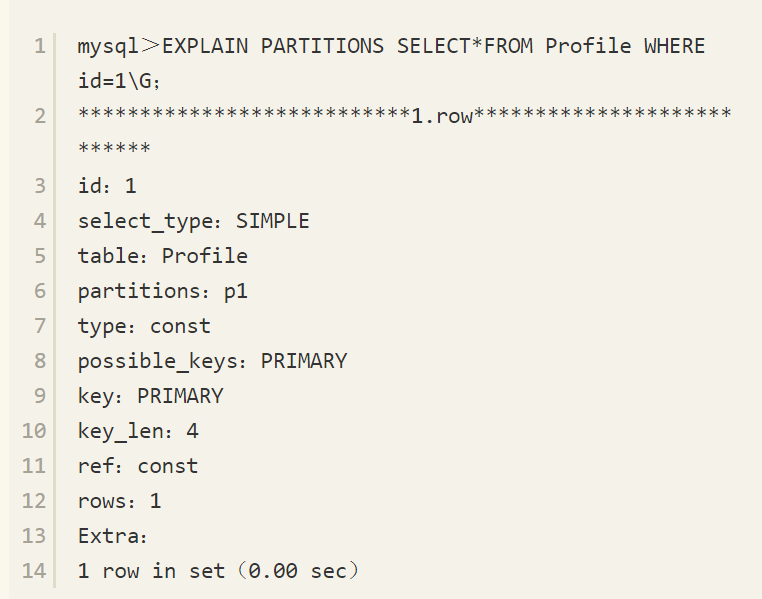
可以发现只寻找了p1分区,但是对于Profile表中nickname列索引的查询,执行分区后会得到如下的结果:
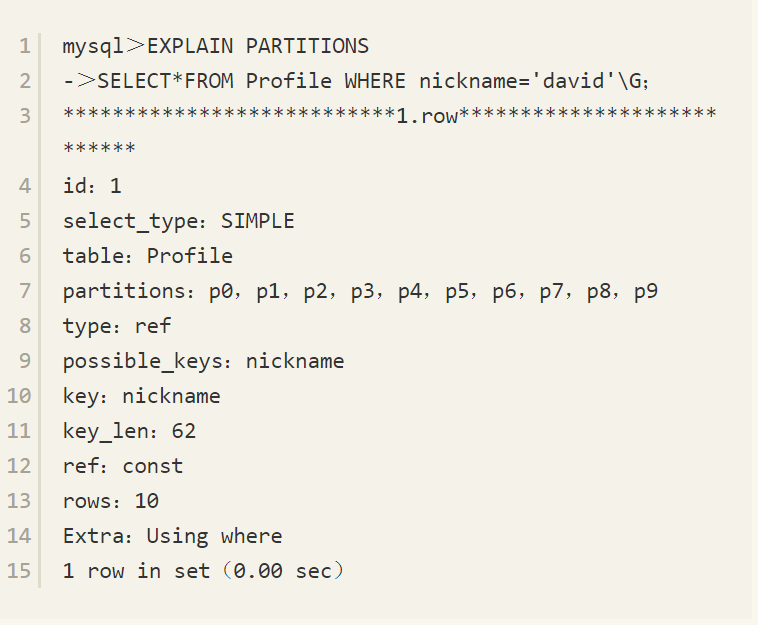
可以看到,MySQL数据库会搜索所有分区,因此查询速度上会慢很多,将如下语句与上述语句进行比较:
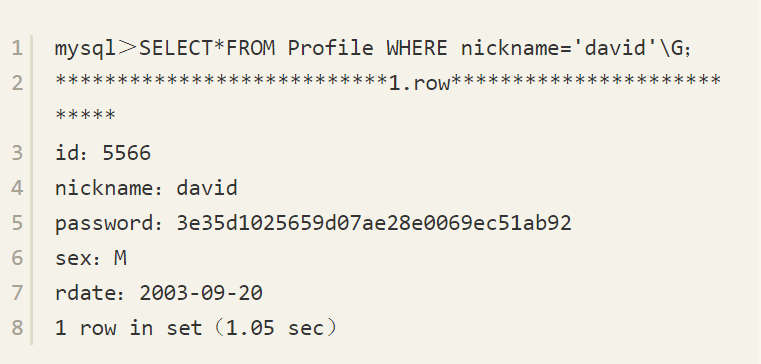
上述简单的索引查找语句竟然需要1.05秒,这显然是因为查询需要遍历所有分区,且实际的IO操作执行了约20~30次。而在未分区的同样结构和大小的表上,执行上述SQL语句只需要0.26秒。
因此对于使用InnoDB存储引擎作为OLTP应用的表在使用分区时应该十分小心,在设计时要确认数据的访问模式,否则在OLTP应用下分区不仅不会提高查询速度,反而可能会使应用执行得更慢。
三、 在表和分区间交换数据
MySQL 5. 6开始支持ALTER TABLE……EXCHANGE PARTITION语法。该语句允许分区或子分区中的数据与另一个非分区的表中数据进行交换。如果非分区表的数据为空,那么相当于将分区中的数据移动到非分区表中。若分区表的数据为空,则相当于将外部表中的数据导入分区中。
要使用ALTER TABLE……EXCHANGE PARTITION语句,必须满足下面的条件:
要交换的表须与分区表有相同的表结构,但是表不能含有分区。
非分区表中的数据必须在交换的分区内定义。
被交换的表中不能含有外键,或者其他表中不能含有对该表的外键引用。
用户除了需要ALTER、INSERT和CREATE权限外,还需要DROP的权限。
此外,有两个小的细节需要注意:
使用该语句时,不会触发交换表和被交换表上的触发器。
AUTO_INCREMENT列将被重置。
接着来看一个例子,先创建含有RANGE分区的表e,并填充相应的数据。

然后创建交换表e2,表e2的结构和表e一样,但需要注意的是表e2不能含有分区。

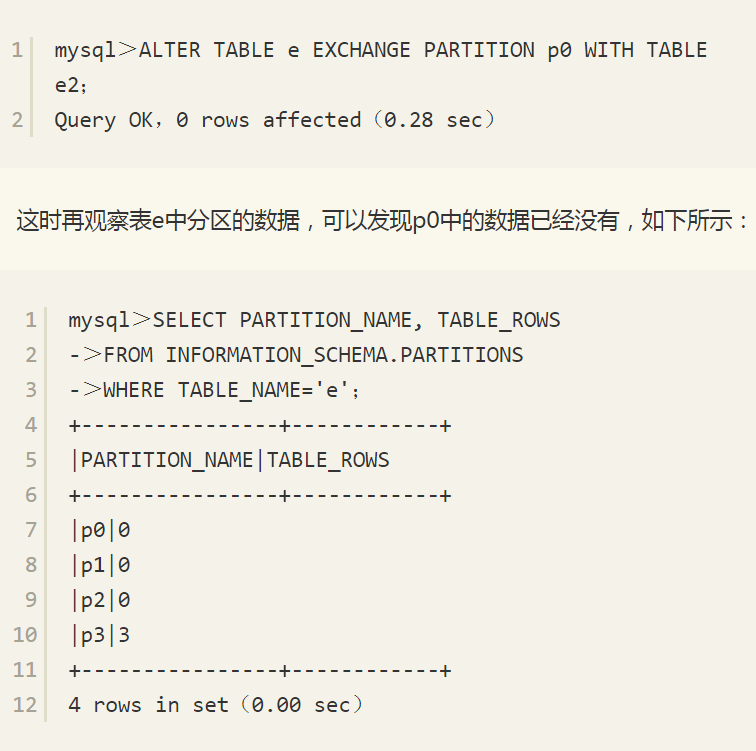
因为表e2中没有数据,使用如下语句将e表的分区p0中的数据移动到表e2中。


 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

