6.2 环境的影响
本书已经介绍过环境的一些影响,例如,并发线程、操作系统、硬件、并发运行软件以及MySQL服务器与客户端的选项。但是,一个查询,就算是单个客户运行在专用的MySQL服务器上,同样也可能被它所运行的环境所影响。你从存储过程、存储函数、触发器或事件中调用查询时,在这些场景中,就有可能会用它们自己默认的参数值覆盖当前会话选项。因此,如果你遇到你无法解释的问题,请尝试在该例程之外的环境中执行相同的查询。如果结果不相同,请核对程例的字符集与SQL模式。请检查例程中所有的必要对象是否存在,影响查询的变量是否设置。另外一个主要的环境变量是time_zone,它会影响如NOW()与CURDATE()等时间函数的结果。
如果你的查询无法正常工作,那么应检查它所运行的环境。
6.3 沙箱
沙箱(sandbox)是一个为运行应用程序而搭建的隔离环境,它不受环境外的其他任何东西影响。在本书中,我一直鼓励大家在数据库上“尝试”各种配置选项与调整。但是这样的一些“尝试”可能会使应用程序变慢,甚至使得应用程序或数据库崩溃。这不是大部分用户想要的。相反,你可以使用沙箱来隔离自己环境中正在测试的系统,这样,你做错什么都不要紧。在MySQL领域,Giuseppe Maxia通过创建一个名为MySQL Sandbox的工具引入了沙箱这个概念。稍后将介绍MySQL Sandbox以及将来它如何能帮助我们,但这里先简单地介绍沙箱的一些变体。在一个表上安全地测试查询的最简单方法就是创建一个副本,这样,原始表就是最安全的,当你对复制数据进行测试时,原始表还可以像往常那样被应用程序使用。你也不用担心如何恢复你无意中改变的数据。

这种解决方案的好处之一是,可以通过WHERE来限制行数,从而做到只复制其中的一部分数据。例如,假设你正在测试一个复杂的查询,并确定它正确地执行了某个WHERE子句。当创建表时,可以限制测试表,以满足该测试的条件,然后你就有一个比较小的表可以用来测试查询。

也可以通过去掉一些条件来简化查询。当原始表很大时,这将节约很多时间。当WHERE子句运行正常,而GROUP BY分组与ORDER BY排序运行错误时,这项技术也非常有用。如果一个查询访问一个以上的表或者只是想在不同表上测试查询,那么创建一个独立的数据库是有意义的。

在这种情况,你将有一个与生产环境完全一样的数据库副本。即使你损坏了副本里的某些行,你也不会有任何损失。对于查询重写以及类似问题,这两种方法都是非常好的。但是如果服务器崩溃或者占用大量资源,则最好不要测试该服务器上的任何东西。而应该出于测试目的专门搭建一个开发服务器并从生产服务器上复制数据。
当你正计划升级MySQL或者想确定更新版本的MySQL是否已经修复了某个特定的bug时,这么做同样有帮助。在应用程序创建之初,你可以在你的开发机器上升级MySQL服务器。但如果应用程序运行很长时间并且你需要测试某一特定MySQL版本如何影响实际数据,在沙箱中,像这种升级就很难手动创建。在这种情况下,MySQL Sandbox就是最佳选择。首先要创建安装,需要一个期望版本且没有安装程序(例如,在Linux中,以tar.gz结尾)的MySQL包,以及MySQL Sandbox的一个副本,MySQL Sandbox可以从https://launchpad.net/mysql-sandbox下载。通过如下命令从MySQL包中创建沙箱:
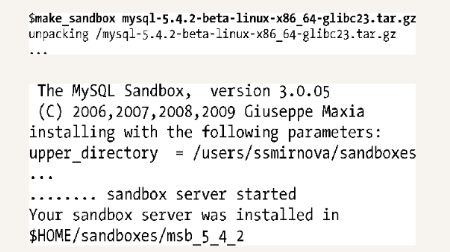
一旦安装,你就应该停止服务器,然后更改配置文件,以便能与生产环境的配置做出对比,然后重启它,导入生产数据库的备份。现在你已经可以安全地测试了。当你想在多个MySQL版本中快速测试你的应用程序时,例如,为了确定bug是否修复,这种方法非常有用。可以创建任意多的沙箱,并且可以在没有额外开销的情况下测试MySQL和数据库的不同方面。你甚至可以创建一个复制的沙箱,即一个包含一个主服务器和多个确定的从服务器的沙箱。
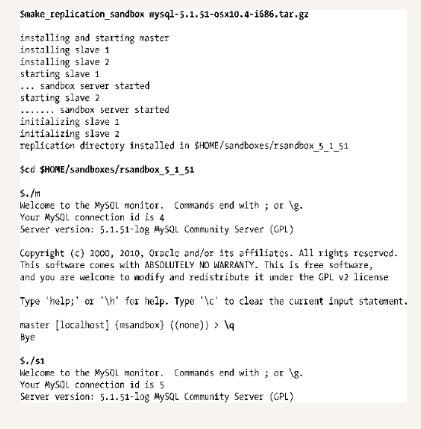

一旦沙箱运行正常,就可以根据其选项进行各种测试。对单个服务器使用MySQL Sandbox不可忽视的优点之一就体现在你需要对比多个环境时。如果你正在某类系统上使用某个版本的软件,那么你可以从MySQL的备份中只将生产数据加载到开发计算机上。使用复制,这是不行的,因为你将至少需要两个MySQL实例。并且,复制的沙箱能极大地节约时间,即使你不关注版本与自定义环境,因为根据你的需要,它仅仅只须花费几分钟的时间来安装和设置尽可能多的MySQL实例。 警告Workbench实用工具(Workbench Utilities)集中的一些工具可以帮助用户为自己的生产数据库创建一个沙箱副本。mysqldbcopy复制一个数据库,不管是在同一个服务器上创建一个不同名的数据库,还是在不同服务器上创建一个同名的或者不同名的数据库。mysqlreplicate在两个服务器间,配置与启动复制。
mysqlserverclone在一个正运行的服务器上启动一个新实例。
6.4 错误与日志
另一个重要的故障排除技术听起来特别简单:从服务器读取和分析信息。这是非常重要的一步。第1章介绍了一些工具以及一些示例,它们可以帮助你获取和分析信息,这里增加之前跳过的一些细节。6.4.1 再论错误信息错误消息是关键,不应该被忽视。可以在MySQL参考手册(http://dev.mysql.com/doc/refman/ 5.5/en/errorhandling.html页面)找到错误的相关信息。此网页列出了客户端与服务端的错误消息,却省略了特定予存储引擎的消息。它也无法解释来自操作系统的错误。通过实用程序perror(见1.4节),可以得出描述操作系统错误信息的字符串。另一个非常重要的工具是mysqld错误日志文件,其中包含关于表损坏、服务器崩溃、复制错误,以及更多的信息。它始终都是开启着,当你遇到问题时,可以对其进行分析。应用程序中的日志不能总是取代mysqld服务器的错误日志,因为后者能包含对应用程序不可见的一些问题与细节。
6.4.2 崩溃
1.7节介绍了崩溃与处理这些崩溃的合适顺序。首先使用上一节介绍的方法:查看错误日志文件,并分析其内容。这在大部分情况是可行的,但本节将介绍如果错误日志不包含足够的信息来帮助你解决崩溃,你该怎么办。最新版本的MySQL服务器,甚至是发布版,都会输出回溯信息(backtrace)。因此,如果错误日志文件没有输出回溯信息,则应该检查mysqld二进制文件是否被删除了[1](在类UNIX系统上,file命令能告知可执行文件是否被删除了)。如果它确实被删除了,就可以使用MySQL发布版的mysqld二进制文件替换原来的。如果是你自己编译MySQL,请编译一个带有符号表的版本供测试使用。确认mysqld二进制文件是否包含符号表,例如:没有被删除。在某些情况下,可能需要运行调试的二进制文件。这是一个名为mysqld-debug的文件,它位于MySQL安装根目录的bin目录下。带有调试功能的二进制文件包含断言,它有助于在早期阶段捕捉问题。在这种情况下,你可能会到一条比较好的错误消息,因为当服务器出现问题时,错误消息将被捕捉到,而不用拖到内存泄漏发生时。使用发布的二进制版本,你是得不到错误消息的,除非内存泄漏真正导致了崩溃。使用调试功能的二进制文件的代价就是性能下降。如果错误日志文件没有关于崩溃的足够信息来帮助你找到问题的根据,那么可以尝试使用以下介绍的两种方法。就像1.7节介绍的从错误日志文件获得回溯信息那样,在任何情况下,工作总是从证据开始。不要只是直观猜测,因为如果你试图用错误的猜测来解决问题,你可能会面临更多的问题。始终进行测试。任何猜测都可能是错误的。1.核心文件核心文件包含一个进程的内存映像,当进程意外终止时会创建它(如果操作系统配置成这样)。可以通过在MySQL服务器启动时设置core选项来获得一个核心文件,但是首先你必须确定操作系统允许创建核心文件。为了通过 核心 文件调试,你需要熟悉 MySQL 源代码。通过 MySQL Forge 上的“MySQL Internals”页面熟悉源代码是一个良好的开始。我同样推荐Charles A. Bell博士撰写的《Expert MySQL》(Apress出版社)一书。同样可以在Sasha Pachev撰写的《Understanding MySQL Internals》(O’Reilly出版社)中以及由AndrewHutchings与Sergei Golubchik联手编写的《MySQL 5.1 Plugin Development》(Packt出版社)中获得非常有用的信息。当然,从某种程度上来说,你有必要深入了解MySQL源代码本身。这里不会详细介绍如何处理核心文件,因为MySQL源代码博大精深,即使专门用一本书的篇幅来讨论这个主题也不一定能面面俱到,所以这里只展示一个小示例。为了创建核心文件,必须使用core选项来启动mysqld,并调整操作系统,以便能够创建大小不受限制的核心文件。不同的操作系统使用不同的工具来控制核心文件的创建。例如,Solaris使用coreadm,而在我的Mac OS X Tiger 系统上,我不得不编辑/etc/hostconfig。在Window中,你应该有mysqld与操作系统的调试符号表。在类UNIX系统中,最简单的方式是使用ulimit -c命令,这里它应该被设置为unlimited,不过,请参考你的OS用户手册来确定是否还有其他的配置需要更改。核心文件创建后,可以通过调试器来读取其内容。这里使用gdb,但这不是必需的,你可以使用自己喜欢的调试器。

该命令行包括gdb命令的名称,紧随其后是可执行文件mysqld的路径与核心文件本身的路径。


首先我们需要回溯信息:
通过以上输出,你已经了解了一些信息。如果你想要详细了解如何使用核心文件,可以转向man core、调试器文档、MySQL Internals Manual、我推荐的图书以及代源码。2.通用日志文件另外一种捕捉发生了什么的方法就是使用6.1.2节提到的:通用日志文件与代理解决方案。这里概念都非常相似,我将展示如何通过通用查询日志来获取错误,并且如果你决定使用代理解决方案,让你自己推断出代理解决方案。我将再次使用1.7节介绍的例子,但是在这个案例中,它运行在我自己的MacBook上。错误日志包含如下内容。

此版本不输出回溯信息。如果我处于不能使用调试版本的MySQL服务器的情况,我怎么能知道这是怎么回事?这是通用日志能再次帮助我们的地方。MySQL在执行每个查询之前会把它写入这个日志。因此,我们能从这个日志中找到关于崩溃的信息。首先,开启日志。

等待,值得崩溃再次发生,然后,查看通用日志的内容。
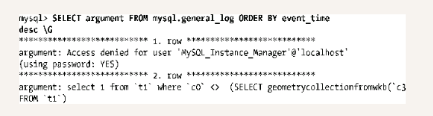
这里输出的第二行就是导致服务器崩溃的语句。如果错误日志不包括关于服务器崩溃的足够信息,请使用通用查询日志。这种技术唯一一种不能帮助我们的情况是当崩溃发生在MySQL服务器写入通用日志时,或者在此之前。当这发生时,你可以尝试记录日志到文件中,而不是记录到表中。代理与应用端解决方案不会受此影响。
6.5 收集信息的工具
信息能指导故障排查。知道服务器进程中发生了什么是非常重要的。本书已经介绍了获取这些信息的方法,但是这里将添加一些关于被讨论工具的详细信息。
6.5.1 Information Schema
INFORMATION_SCHEMA是提供关于数据库元数据信息的数据库,所有SHOW查询现在都映射到INFORMATION_SCHEMA表中的SELECT语句上。你能像任何其他表那样查询INFORMATION_SCHEMA表;这是它能超过其他工具的最大优势。INFORMATION_ SCHEMA表唯一的缺点就是经过优化后也不能很快执行,所以在它上面的查询都很慢,特别是在包含很多对象信息的表上。
这里不介绍每张表,因为MySQL参考手册包含大量关于它们结构的细节(详见:http://dev.mysql.com/doc/refman/5.6/en/information-schema.html)。相反,我将介绍一些查询以证明你可以从INFORMATION_SCHEMA得到的那种有用信息。你仍然需要从手册中找到一些细节。这里把链接指向5.6 MySQL参表手册,是因为我提到的几个表都在这个版本中有介绍。为了得到INFORMATION_SCHEMA可以做些什么的思路,让我们从当前的使用中提取每个存储引擎有多少个表开始。我从列表中排除了mysql数据库。因为其所有表始终都使用MyISAM存储引擎。
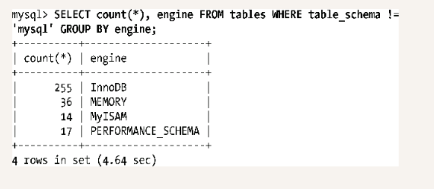
这信息非常有用,例如:你想选择一个用于日常备份的策略[2]。另外一个示例是得到引用特定表的外键列表。当你访问父表并且完全不知道它连接的子表是哪一个时,如果你得到150错误,Foreign key constraint is incorrectly formed,这就非常有用:

在此输出中,你可以看到,有5个表与父表items相关联。所以如果在items表上执行的一个查询失败并报150错误,你就能快速地找出它所有的子表,并修复造成执行语句报那个错误的数据。既然你对INFORMATION_SCHEMA表是什么已经有一定概念了,我们就可以切换到特定表了。
6.5.2 InnoDB信息概要表
2.8.3节的并发故障排查场景中,我已经介绍了INNODB_TRX、INNODB_LOCKS和INNODB_LOCK_WAITS表。这里我还会给出其他表的快速概览。INNODB_TRX提供了大量有关当前运行事务的详细信息。甚至当锁跟并发并不是同样问题的时候,也可以使用它,但是在锁定问题的上下文里,可以做像找到执行很长时间的事务那样的一些事情(用与你的实际情况相关的时间替换“00:30:00”):

可以找到哪些线程正在等待锁。

或者等待某一锁的时间超过指定时间。 为了了解事务有多大,请检索行锁定的数目(TRX_ROWS_LOCKED),内存里锁结构的大小(TRX_LOCK_MEMORY_BYTES),或者更新的行数(TRX_ROWS_ MODIFIED):

还可以校验事务的隔离级别,外键检测是否打开与其他相关信息。 提示注意,只有打开InnoDB表后,才会在INNODB_TRX表有事务显示。除了以START TRANSACTION WITH CONSISTENT SNAPSHOT开始的事务之外,这与START TRANSACTION查询,后面跟着InnoDB表的SELECT的效果一样。命名以INNODB_CMP开头的表,显示了InnoDB使用压缩的好坏程度。因此,INNODB_CMP与INNODB_CMP_RESET包含关于压缩表的状态信息,而 INNODB_CMPMEM与INNODB_CMPMEM_RESET包含在InnoDB缓冲池里关于压缩页的状态信息。在这些调用中增加_RESET版本的唯一额外功能是,在查询后,它们重置所有INNODB_CMP表中统计信息为零。因此,如果你想重复统计,就查询_RESET表,如果你想知道从启动以后的统计信息,仅仅需要查询INNODB_CMP和INNODB_CMPMEM。自从5.6.2版本后,也存在以INNODB_SYS和INNODB_METRICS 开头的表。INNODB_ SYS表包含关于在内部词典中如何存储InnoDB表以及替换InnoDB表监控器信息。在InnoDB团队博客可以找到一些非常好的说明与它们使用方法的范例。在一个地方,INNODB_METRICS表包含关于性能与资源使用计数的所有数据。为了得到这些统计信息,需要启用一个模块。这些计数器是值得学习的,因为它能帮助你分析InnoDB存储引擎里面究竟发生了什么。同样,在InnoDB团队博客中提供了说明与范例。
6.5.3 InnoDB监控
2.8.2节介绍了InnoDB监控。以下对这一节进行了总结,并补充另外一些有用的细节。为了启用InnoDB监控器,需要创建名为innodb_monitor、innodb_lock_monitor、innodb_ table_monitor与innodb_tablespace_monitor的InnoDB表。启用这些InnoDB监控器就会分别地从标准、锁、表以及表空间监控器定期写入到标准错误(STDERR)输出中。为这些表定义什么样的表结构或者添加到哪个数据库里,都没有关系,只要它们使用InnoDB存储引擎即可[3]。在数据库停止时会关闭监控器。为了在启动后重新开启它,需要重新创建这些表。如果你希望它们能自动创建,就需要把DROP与CREATE语句添加到init-file选项中。标准的监控器包含的输出信息类似于以下输出,以下输出来自于MySQL 5.5版本。
下面将会对输出代码进行分段解释。
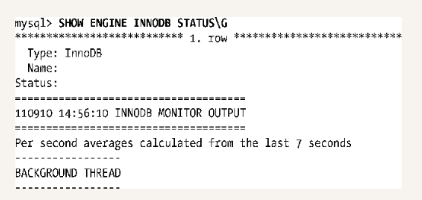
前面输出中的最后一段文字显示,这个输出主要关注主要后台线程所处理的事。

该字据统计从InnoDB启动以后的活动。上面输出的5个数字分别表示,“每秒一次”循环的迭代次数,“每秒一次”循环调用sleep的次数,“每10秒一次”循坏的迭代次数,称为“background_loop”的循环迭代,其运行在当前没有活跃用户时的后台操作,以及“flush_loop”标签代反弹的循环迭。所有这些循环都被主线程运行,这里主线程主要做清理与其他后台操作。

这里表示写入与刷新日志的次数。

从这里开始介绍内部信号量。关于这方面,第2章已经涉及了一些。高数字在这里表示慢的磁盘I/O或高的InnoDB争用。在后一种情况中,可以尝试降低innodb_thread_concurrency,看是否有所改善。需要注意的是,这些数字采集自最近的InnoDB启动,因此这里的信息显示有等待不代表真正有等待。你需要查询Performance Schema库或者检查互斥锁的状态,来确定当前是否有等待发生。

这部分开始显示全局的等待数组信息。第一个数字表示当数组创建后,单元格预留的一个计数,第二个数字表示对象收到通知的次数。 上一行显示,在互斥调用上等待的个数,自旋循环迭代个数,以及操作系统调用的等待个数。

这一行显示在共享(读)锁期间,在读写锁存器(rw-latches)上自旋等待个数,自旋循环迭代个数,以及操作系统调用等待个数。

这一行显示在排他(写)锁期间,在读写锁存器(rw-latches)上自旋等待个数,自旋循环迭代个数,以及操作系统调用等待个数。

这表示,对于每一个互斥锁,操作系统调用等待的每一个自旋循环迭代个数。在这一节里,以下是在UPDATE查询执行期间,值如何更改的一个范例:
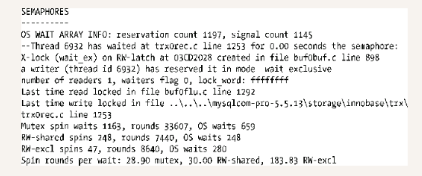
当查询开始执行时,前面的输出可能出现并尝试预留互斥锁。

在文件buf0buf.c的事2766行定义创建互斥锁时,这个会出现得晚一点。在信号量部分,你应该检查是否有值变得很大与是否有很多操作等待互斥锁很长时间。

2.3节已经深入介绍过事务。所以这里仅仅只会涉及几个要点。

这表示所有编号小于4249的事务都已经从历史记录列表中清除了,其中在事务列表中,为了访问相同表中正运行的事务,历史记录列表包含了提供一致性读的记录,但在提交时在修改它们之前。第二个数字表示,有多少撤销编号小于4249的记录从历史记录列表被清除。

这是历史列表的长度(未被清理的已提交事务的撤消日志)。如果这个值变得很大,你可以认为性能下降。这没有线性关系,因为清理性能同样依赖于该列表保留的事务数据总大小,所以很难给出较大值导致性能降低的一个确切例子。这个列表里的大值同样也意味着你有运行很长时间且没有关闭的事务,因为仅当没有事务指向该条目时,这些条目才会被清除。
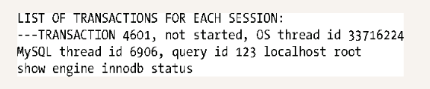
前面的行当前运行的事务列表开始。2.3节介绍了详细内容,所以这里不会重复介绍。








2.8.2节详细介绍了InnoDB锁监控器,所以这里就不再介绍它。还剩两个监控器需要介绍:InnoDB表空间监控器与InnoDB表监控器。InnoDB表监控器输出InnoDB内部字典的内容。可以使用该监控器查看InnoDB是如何存储表的,例如,如果你怀疑它已经损坏。示例输出如下所示。
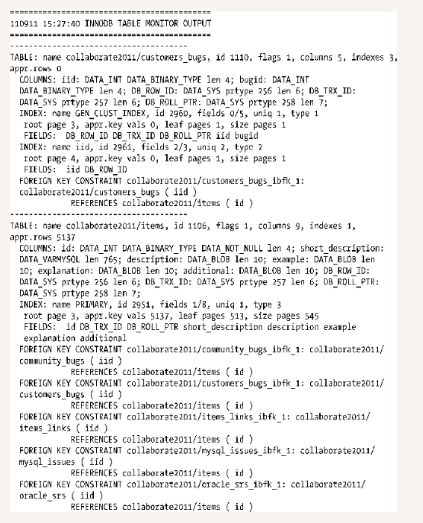
这个输出显示示例1-1中表的信息与同一个数据库里其他表的信息。这个输出不言自明,并且在MySQL参考手册里,有关于输出的详细说明,所以这里不介绍这些字段。我只想把它放在这里确保你能熟悉它是什么样。InnoDB表空间监控器显示在共享表空间中关于文件段的信息。这些信息能帮助你找到关于表空间的问题,例如:碎片或者损坏。请注意,如果你使用innodb_file_per_table选项,该监控器不能显示个别表空间信息。示例输出如下所示。

这个输出的意思在MySQL参考手册的“InnoDBTablespaceMonitorOutput”一节已经清晰地解释。所以这里同样不会重复一遍。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

