3.3 故障与处理
3.3.1 连接数过多导致程序连接报错的原因
连接数是直接反应数据库性能好坏的关键指标,连接数过多,很可能有多种原因,比如,被一条SQL查询给堵死了,造成了后面的DML操作等待,又比如,增、删、改、查操作很频繁,磁盘I/O遇到了瓶颈,导致无法处理繁忙的请求等。
也许有人会问,出现了too many connections,直接增大max_connections值就行了吧?其实,这得看情况,如果你没有设置这个参数,那么将其设置为500~1000,在大多数场合就可以了,但如果是想一直增大(比如增大到10000),那么这就是治标不治本了,因为连接数增大,会导致每个连接所占用的内存也增加,这样一来,机器就很容易因内存不足而死机,所以我们得找到引起连接数升高的本质原因。
在正常情况下,MySQL处理完一条请求后,会根据wait_timeout值来释放连接(参数含义:服务器关闭非交互连接之前等待活动的秒数),一般设置为100秒即可,如果你没有设置采用默认的28800秒,那么客户端在连接到MySQL Server处理完相应的操作后,要等到28800秒以后才会释放内存,如果你的MySQL Server有大量的闲置连接,不仅会白白消耗内存,而且如果连接一直在累加而不断开,最终肯定会达到MySQL Server的连接上限数,这会报’too many connections’的错误。
下面来看一个因重启服务器导致数据库连接数过多的经典案例。之前我们用的是共享表空间,版本是V5.1,由于运行时间很长,产生了很多的碎片,导致ibdata文件变得很大,所以我们就用导出数据和然后再导入,并且重建ibdata的方式来释放碎片。InnoDB分为共享和独立表空间。alter table TableName engine=innodb通过这条命令可以回收表空间整理碎片。但因是共享表空间,不是独立表空间,这样操作可以回收数据空间,而不是磁盘空间。
这里以书柜的例子来解释整理表空间碎片。书柜上的书摆放的很凌乱,此时你把书都整理好了,缩小了它们在书柜里的位置,但书柜还是那个尺寸,不会因为把书弄整齐了,书柜也就缩小了。而独立表空间是:有多少书就放多大尺寸的书柜里。它既可以回收数据空间,也可以回收磁盘空间。
整理完碎片重启服务器后,在早高峰期用户登录时,连接数满了,导致用户登录时一直等待,此时数据库已经处于无响应状态,如图3-4和图3-5所示。
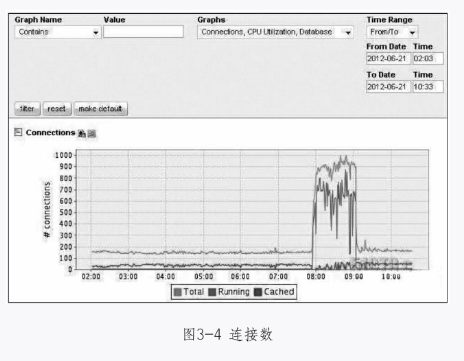
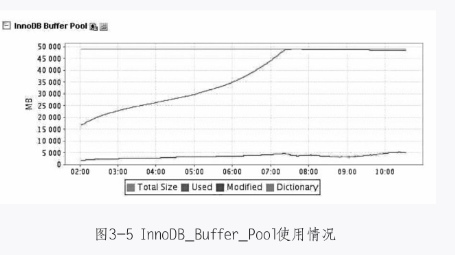
经过分析,发现早高峰连接数升高是这样引起的:由于业务很繁忙,数据库并发高(每秒读操作3000个,写操作500个),当数据库重启后,就会面临一个问题,如何将之前频繁访问的数据重新加载回buffer中,也就是说,如何对InnoDB Buffer Pool进行预热,以便于快速恢复到之前的性能状态。如果仅靠InnoDB本身去预热buffer,将会是一个不短的时间周期,在业务高峰时,数据库将面临相当大的考验,I/O的瓶颈会带来糟糕的性能。早上8点用户登录时,会连接数据库来验证密码,此时先在内存里找,没有找到就会再到磁盘里找,这样相当于走了两个环节,一个用户登录不上,连接就不会释放,后面的用户只能继续排队,导致连接数升高。
解决方法:
在数据库压力很大的情况下,重启完数据库,通过手工执行下列语句,把热数据加载到InnoDB_Buffer_Pool缓冲池里进行预热,从而避免了早高峰连接数升高,程序报错。
select count(*) from User; select count(*) from Buddy; select count(*) from Password;
而在MySQL5.6里,为了解决上述问题,提供了一个新特性来快速预热Buffer_Pool缓冲池。只需在my.cnf里,加入如下命令即可:
innodb buffer pool dump at shutdown=1
解释:在关闭时把热数据dump到本地磁盘innodb buffer pool dump now=1
解释:采用手工方式把热数据dump到本地磁盘。
innodb buffer pool load at startup=1
解释:在启动时把热数据加载到内存。
innodb buffer pool load now=1
解释:采用手工方式把热数据加载到内存。
在关闭MySQL时,会把内存中的热数据保存在磁盘的ib_buffer_pool文件中,该文件位于数据目录下。如图3-6所示。

图3-6 导出热数据到本地文件
在启动MySQL时,会自动加载热数据到Buffer_Pool缓冲池里,这样,机器重启后热数据会始终保存在内存中,如图3-7所示。

图3-7 加载热数据到InnoDB_Buffer_Pool
注意
只有在正常关闭MySQL服务,或者pkill mysql时,才会把热数据导出到内存。机器宕机或者pkill -9 mysql,是不会导出的。
下面再来看个“磁盘高负荷把MySQL拖垮”的案例,我们有块业务需要记录大量的LOG日志,插入操作很频繁,这就导致了磁盘高负荷运转,结果就是CPU Wait I/O升高,负载加大,来看看CPU的情况,如图3-8所示。
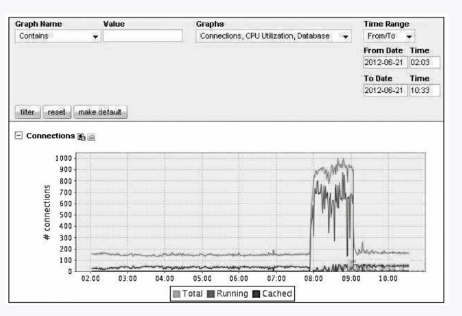
图3-8 CPU的情况
再来看看insert写操作,平均每秒为1000个,可见写操作很大,如图3-9所示。
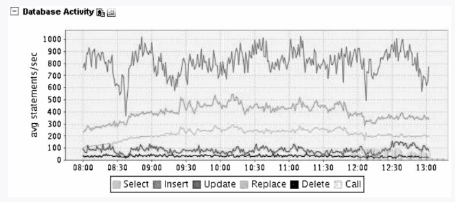
图3-9 数据库性能QPS
最后来看看磁盘情况,它处于饱和状态,处理一个I/O请求需要等待15毫秒,如图3-10所示。
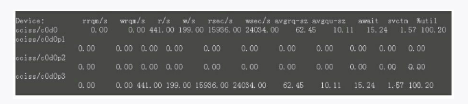
图3-10 磁盘I/O
此时出现了大量慢日志,而这并不是因为SQL自身存在问题,而是机器压力大造成的。
把情况反馈给了开发,经过程序Bug处理后,再看相应的指标数,如图3-11~图3-14所示。
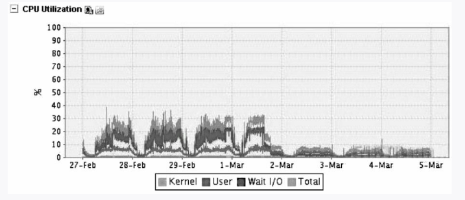
图3-11 CPU的情况
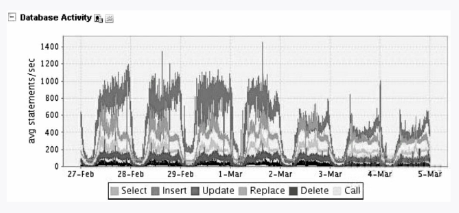
图3-12 数据库性能QPS
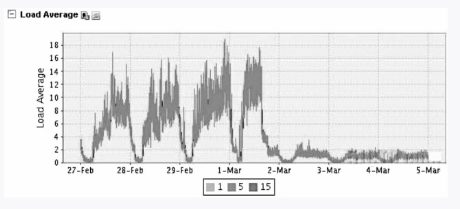
图3-13 CPU负载
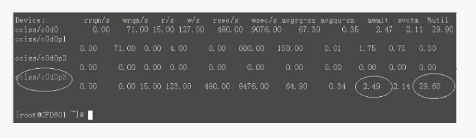
图3-14 磁盘I/O
可以看到,磁盘I/O已正常,不再处于繁忙状态,处理一个I/O请求只需要等待2.49毫秒。比起之前的15毫秒来,减少了12.51毫秒。
该案例的瓶颈是磁盘I/O繁忙导致CPU负载升高。如果你以后也遇到了这个问题,可以使用一个很简单的方法——加内存,现在内存的价格也很便宜,直接用硬件去解决,把InnoDB_Buffer_Pool调整成内存的70%,减少磁盘I/O的压力,当InnoDB_Buffer_Pool内存缓冲池大于你的数据量时,此时的性能是最好的,因为所有的数据增删查改操作都是在内存中进行的,内存的速度要比磁盘快得多。
3.3.2 记录子查询引起的宕机
这是2013年5月10日早上10:52分出现的一次故障,由于开发在主库上(生产环境上)运行了一条子查询的慢SQL,导致服务器死机。下面先看下报警信息,如图3-15所示。

图3-15 Nagios报警
从10:41开始,服务器的swap分区报警,之后内存不足报警,再后来内存耗尽,导致机器死机。通过分析慢日志,我发现是一条统计的SQL语句直接把服务器弄死机了。这肯定是人为执行的,而且是从跳板机98.149上登录SQLYOG上执行的,如图3-16所示。

图3-16 慢日志
该SQL语句的执行耗时170秒(猜想是没执行完直接Ctrl+C终止了),而且还是在主库(有业务的机器)上运行的,这导致锁表和其他的进程一直等待,最后越积越多,直接让服务器死机了。
晚上,我在备库上又执行了一次这条SQL,花费了11分26秒(随着这个表的增大,时间还会变慢),如图3-17所示。
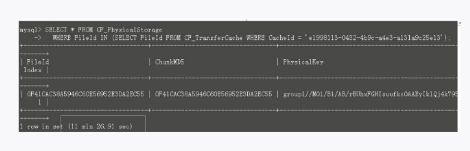
图3-17 执行时间
为什么这条SQL会执行很慢呢?在MySQL5.1和MySQL5.5的版本里,子查询的性能可谓是相当差,优化器处理不是很好,特别是在WHERE从句中的IN()子查询。对于该查询,MySQL需要先为内层查询语句的查询结果建立一个临时表,然后外层查询语句才能在临时表中查询记录。查询完毕后,MySQL还需要撤销这些临时表。
不过,可以使用连接查询来代替子查询,连接查询不需要建立临时表,其速度比子查询要快。
基于此,上面那条SQL可以这样优化:改用表连接方式(MySQL5.6版本除外),如图3-18所示。
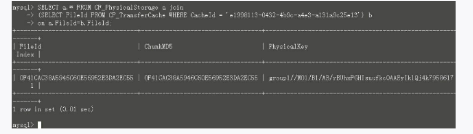
优化后,只需要0.01秒就出结果。
所以,这里要提醒大家一下,凡是这种统计的SQL,千万不要在主库上运行,子查询目前的性能还很差。
一般情况下,开发人员写的SQL里,很多查询都需要使用子查询,子查询可以使查询语句更灵活、易懂,但子查询的执行效率不高,解决的方案是上面所说的用表连接代替子查询。在MySQL5.6以前的版本里,子查询仅仅被看成是一个功能,生产环境下很少使用到。而在MySQL5.6版本里,针对这个问题进行了强劲的优化,这意味着,你可以在生产环境下使用子查询。
下面将分别在MySQL5.5和MySQL5.6里对该功能进行演示,帮助大家了解其特性,如图3-19和图3-20所示。
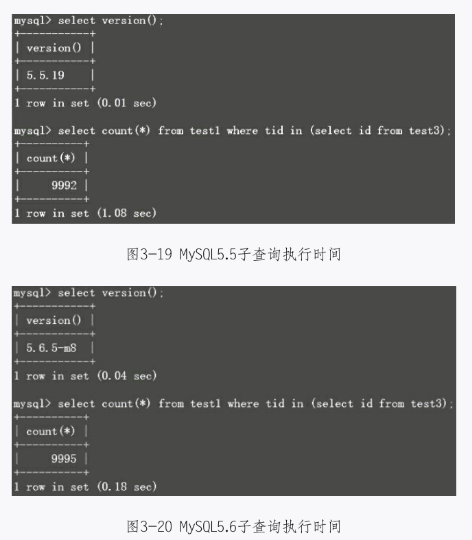
可以看到,在MySQL5.6里,子查询的速度比MySQL5.5快了10倍。之后,再用优化器对其进行优化,效果如图3-21和图3-22所示。
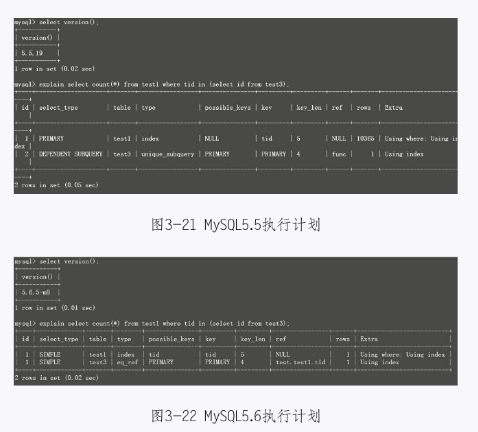
可以看出,实际上是把子查询改写成了join方式。现在可以放心大胆地去用子查询了
3.3.3 诊断事务量突高的原因
在介绍本节案例之前,先来看看二进制日志相关知识。二进制日志由配置文件的log-bin选项负责启用,MySQL服务器将在数据根目录创建两个新文件XXX-bin.001和xxx-bin.index,若配置选项没有给出文件名,MySQL将使用主机名称命名这两个文件,其中.index文件包含一份全体日志文件的清单。MySQL会把用户对所有数据库的内容和结构的修改情况记入XXX-bin.n文件中,而不会记录SELECT和没有实际更新的UPDATE语句。
二进制日志有两个作用,一是恢复数据,比如,早上9点误删除了一张表,那么可以通过凌晨的全量备份,加上凌晨到9点之前的二进制日志文件做增量恢复。二是实现MySQL的主从复制。
下面进入正题,快下班时收到Nagiso报警短信,说更新和插入阀值报警,于是登录到MySQL Monitor上查看,确实如此,如图3-23所示。
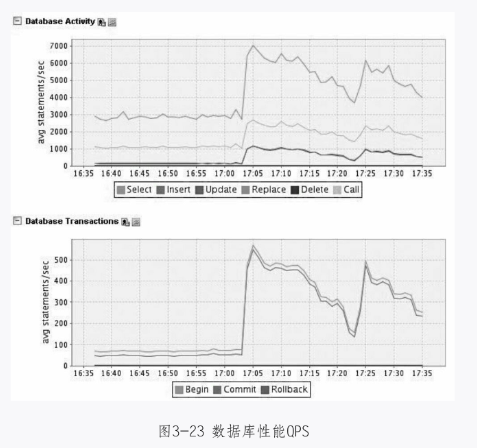
看到这个现象,于是登录MySQL服务器上,通过binlog来分析17:05数据库发生抖动之前和之后的表,看看哪个更新较大。
下面是17:05之前的binlog日志:


这样就比较直观地显示出了哪些表的更新较多,之后再找开发人员确认问题,了解是否是业务增长导致的。
这次故障是演示了如何通过binlog日志来分析业务增长量,哪个表写操作频繁,如果以后你也遇到了此类问题,同样可以采用此方法来分析。
注意
此命令只支持MySQL5.1以上版本,innodb引擎、READ-COMMITTED隔离级别、或者binlog_format的格式为ROW。如果读者没有看明白什么是隔离级别或者binlog的格式,在下一节会有介绍。
3.3.4 谨慎设置binlog_format=MIXED
binlog_format有三种格式,STATEMENT、ROW和MIXED。STATEMENT在二进制日志里,记录的是实际的SQL语句,如图3-24所示。
图3-24 STATEMENT格式
ROW在二进制日志里记录的不是简单的SQL语句,而是实际行的变更,如图3-25所示。
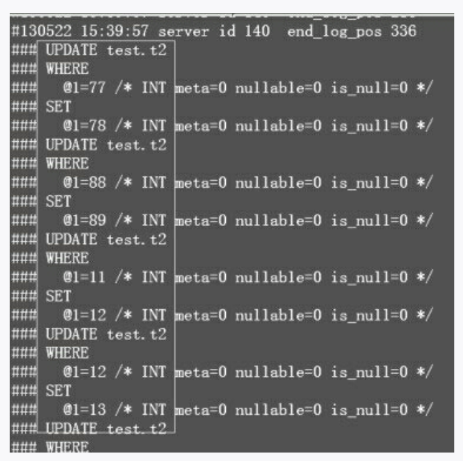
在二进制日志里,MIXED默认还是采用STATEMENT格式记录的,但在下面这6种情况下会转化为ROW格式,见手册:

第一种情况:NDB引擎,表的DML操作增、删、改会以ROW格式记录。
第二种情况:SQL语句里包含了UUID()函数。
第三种情况:自增长字段被更新了。
第四种情况:包含了INSERT DELAYED语句。
第五种情况:使用了用户定义函数(UDF)。
第六种情况:使用了临时表。
下面我们来看一个实例,在该实例中,主从都是MySQL5.5, binlog_format被设置为了MIXED格式,而且使用的默认隔离级别为REPEATABLE-READ,我们来看看这样设置会有什么问题。
首先来看看master上的数据,如下所示:
1. mysql>select*from t2; 2. +----+ 3. | id| 4. +----+ 5. | 1| 6. | 2| 7. | 3| 8. | 4| 9. | 5| 10. | 6| 11. | 7| 12. | 8| 13. | 9| 14. |10| 15. +----+ 16. 10 rows in set(0.00 sec) 接着看看slave上的数据,如下所示: 1. mysql>select*from t2; 2. +-----+ 3. |id | 4. +-----+ 5. | 1| 6. | 2| 7. | 3| 8. | 4| 9. | 5| 10. +-----+ 11. 5 rows in set(0.00 sec)
那么我在master上执行如下命令:
1. mysql>update t2 set id=99 where id=9; 2. Query OK,1 row affected(0.01 sec) 3. Rows matched:1 Changed:1 Warnings:0
你说slave上会报错吗?答案是:NO,不会报错,没有任何提示。不信吗?各位可按照上面的内容测试一下。那为啥不会报错呢?因为在二进制日志里虽然采用的是MIXED格式,但默认还是采用的STATEMENT格式记录的,只有几种特殊情况才会以ROW格式记录,所以我们查看binlog会发现记录的是一条update t2 set id=99 where id=9的SQL语句,这条SQL在slave机器上执行后,由于没有发现id=7的这条记录,影响的行数为空,因此主从复制进程并不会中断。但是在这种情况下,主从数据是很不安全的,很容易出现数据不一致的情况,而且MySQL并不会发出任何报警信息。在MySQL5.1以后的版本中,通过采用ROW格式解决了这个问题。
在改为binlog_format=ROW格式后,再次执行刚才的语句,就会报错,如下所示:
1. mysql>update t2 set id=99 where id=9; 2. Query OK,1 row affected(0.00 sec) 3. Rows matched:1 Changed:1 Warnings:0
执行结果如图3-26所示。

图3-26 同步报错
如果你采用的是默认隔离级别REPEATABLE-READ,那么建议设置binlog_format=ROW。如果是READ-COMMITTED隔离级别,binlog_format=MIXED和binlog_format=ROW的效果是一样的,binlog记录的格式都是ROW,很神奇吧?你去试试就知道了。ROW格式对主从复制来说是很安全的参数。
之前有个网友问我,如果binlog_format为row格式,那么数据量很大的时候,日志量就会很大了,再一个就是写日志所带来的I/O问题是否也要考虑进来呢?
这个问题问得相当好,没错,如果设置为row格式,binlog文件会比STATEMENT格式大很多,而且主从复制是通过binlog来传输的,binlog的增大也增加了网络开销,这就是一把双刃剑,看你如何取舍了,你是要安全稳定性,还是要性能?就我管理的机器上来看,若以15000转希捷硬盘做RAID10,每秒写操作在200个/秒还是没有问题的。
不过,在MySQL5.6里,针对这位网友提出的这个问题进行了优化,可以通过设置binlog_row_image=minimal加以解决,如图3-27所示。
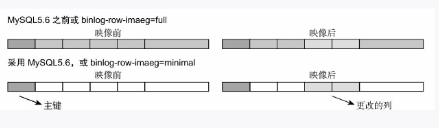
图3-27 binlog_row_image
也就是说,binlog里只记录影响后的行,从而减少了binlog的增长量大小。下面来演示一下,表里的数据如图3-28所示。
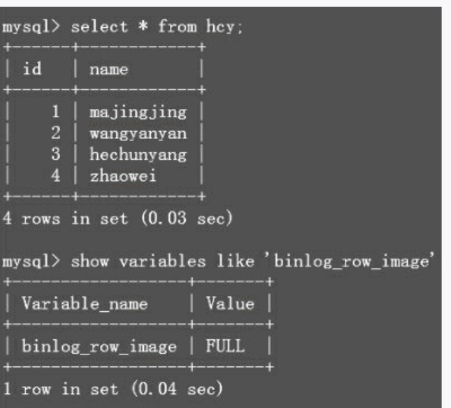
图3-28 binlog_row_image设置为FULL
注意,我的binlog_row_image是默认的FULL,下面执行一条更新语句,如图3-29所示。

图3-29 更新
然后再到binlog里去查看,如图3-30所示。
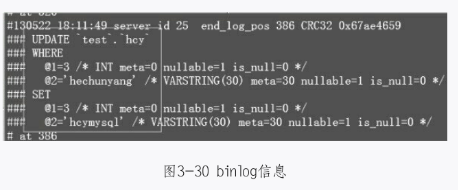
可以看到,在binlog里会把所有影响的行都给记录下来。下面把binlog_row_image设置为minimal,再执行一条更新语句,如图3-31所示。
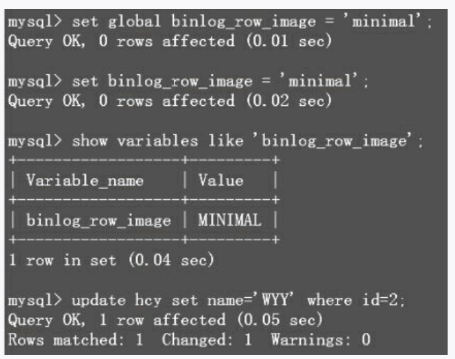
图3-31 binlog_row_image设置为MINIMAL
然后再到binlog里去查看,如图3-32所示。
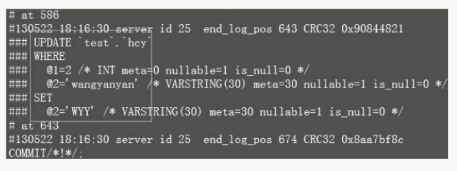
图3-32 binlog信息
如果你仔细和上面的图3-30和图3-32进行对比,就会发现区别,没错,这里只记录了影响的那一行记录。
至于REPEATABLE-READ和READ-COMMITTED有什么区别,将在优化那一章加以介绍。
3.3.5 未设置swap分区导致内存耗尽,主机死机
这是一个真实的案例,在2009年和2010年的时候,我负责管理的一个主机多次被Hang死,当时的情况是主机可以ping通,但ssh却连接不上,导致cluster无法切换,只有人工去重启那台被Hang死的机器,才能正常切换。
该主机内存是72 GB,其中MySQL(Innodb_Buffer_Pool)内存缓冲池所用的内存为48 GB,但在机器正常的情况下,使用free -m命令查看,会发现InnoDB_Buffer_Pool内存已经超过了48 GB,为什么会出现这种情况?这是因为其他程序或者系统模块需要额外的内存,比如,cp一个大文件,或者在主库上mysqldump数据库等,当物理内存不够用的时候,操作系统就会把MySQL所拥有的一部分地址空间映射到swap上去。在这种情况下,我们设置echo 0 > /proc/sys/vm/swappiness来禁止使用swap,并且没有建立swap分区,这样做是考虑到将分配给MySQL的地址空间映射到swap上,会导致性能有突起波动。但是如此设置后似乎并没有解决问题,还是存在主机被Hang死的情况。
在百思不得其解的情况下,后来参考了淘宝《MySQL如何避免使用swap》这篇文章[插图],才知道将swappiness设置为0,只能减少使用swap的概率,并不能避免Linux使用swap,所以内存被耗尽后,主机仍旧会被Hang死了。
找到原因后,解决起来也简单,我们后来的解决方案是:
1)增加2 GB的swap分区,避免内存耗尽时机器死机,可以给予些缓冲,重启前端程序释放MySQL压力。
2)增加内存监控,当内存使用率达到90%,通过重启MySQL来释放内存,避免机器死机(内存Nagios监控脚本会在监控章节介绍)。
3.3.6 MySQL故障切换之事件调度器注意事项
先来普及下基础知识:事件调度器(event)是在MySQL5.1中新增的另一个特色功能,可以作为定时任务调度器,取代部分原先只能用操作系统任务调度器才能完成的定时功能。而且MySQL的事件调度器可以实现每秒钟执行一个任务,这在一些对实时性要求较高的环境下非常实用。不过,在使用这个功能之前必须确保event_scheduler已开启,可执行如图3-33所示的命令。

图3-33 事件调度器开启
下面针对事件调度器在主从切换时具体会有什么影响,做了一个测试:
在主从架构中,在master创建一个event,如下所示:


也就是说,事件只能在master上触发,在slave上不能触发,如果slave上触发了,同步复制就会坏掉。当主从故障切换之后,VIP漂移到了以前的slave上,此时slave就成了新的master。但这时,事件的状态还是维持着slaveSIDE_DISABLED,并不是也改成了ENABLED,这样就会造成切换以后,事件无法执行。所以,需要人工重新开启事件状态。命令如下所示:
mysql> alter event 'insert' enable; Query OK, 0 rows affected (0.07 sec)
3.3.7 人工误删除InnoDB ibdata数据文件,如何恢复
常在群里看到,有人因为不熟悉InnoDB引擎,而误删了InnoDB ibdata(数据文件)和ib_logfile(redo log重做事务日志文件),结果导致了悲剧的发生。如果有做主从复制同步,那还好,如果是单机呢?如何恢复?
下面就来模拟生产环境下,人为误删除数据文件和重做日志文件,是如何恢复的。
1)用Sysbench模拟数据的写入,如下所示:
sysbench --test=oltp --mysql-table-engine=innodb --oltp-table-size=10000000 --max-requests=10000 --num-threads=90 --mysql-host=192.168.110.140 --mysql-port=3306 --mysql-user=admin --mysql-password=123456 --mysql-db=test --oltp-table-name=uncompressed --mysql-socket=/tmp/mysql.sock run
2)使用rm -f ib*删除数据文件和重做日志文件。
下面就来具体看看如何恢复。
若此时你发现数据库还可以正常工作,数据照样可以写入,切记,这时千万别把mysqld进程杀死,否则没法挽救。
接下来,先找到mysqld的进程pid,如下所示:
# netstat -ntlp | grep mysqld tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 30426/mysqld
这里是30426。
之后要执行很关键的一步,输入如下命令,并查看结果:
#ll /proc/30426/fd|egrep'ib |ibdata' lrwx------1 root root 64 9月24 16:51 10->/u2/mysql/data/ib logfile1 lrwx------1 root root 64 9月24 16:51 11->/u2/mysql/data/ib logfile2 lrwx------1 root root 64 9月24 16:51 4->/u2/mysql/data/ibdata1 lrwx------1 root root 64 9月24 16:51 9->/u2/mysql/data/ib logfile0
其中,10、11、4、9就是我们要恢复的文件。
这时,你可以把前端业务关闭,或者执行:
FLUSH TABLES WITH READ LOCK;
这一步的作用是让数据库没有写入操作,以便完成后面的恢复工作。
如何验证没有写入操作呢?分以下几步,记住要结合在一起观察。
先输入以下命令,让脏页尽快刷入到磁盘里。
set global innodb max dirty pages pct=0;
然后查看binlog日志写入情况,确保File和Position的值没有在变化。
mysql> show master status; +-------------------------+------------+--------------------+-------------------------+ |File |Position|Binlog Do DB|Binlog Ignore DB| +-------------------------+------------+--------------------+-------------------------+ |mysql-bin.000002| 107 | | | +-------------------------+------------+--------------------+-------------------------+ 1 row in set (0.00 sec)
最后再查看InnoDB状态信息,确保脏页已经刷入磁盘。
show engine innodb status\G; ------------ TRANSACTIONS ------------ Trx id counter A21837 Purge done for trx's n:o < A21837 undo n:o < 0
##确保后台Purge进程把undo log全部清除掉,事务ID要一致。
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1, free list len 65, seg size 67, 0 merges ## insert buffer合并插入缓存等于1 --- LOG -- Log sequence number 18158813743 Log flushed up to 18158813743 Last checkpoint at 18158813743 ## 确保这3个值不在变化 ---------------------- BUFFER POOL AND MEMORY ---------------------- Total memory allocated 643891200; in additional pool allocated 0 Dictionary memory allocated 39812 Buffer pool size 38400 Free buffers 37304 Database pages 1095 Old database pages 424 Modified db pages 0 ## 确保脏页数量为0 -------------- ROW OPERATIONS -------------- 0 queries inside InnoDB, 0 queries in queue 1 read views open inside InnoDB Main thread process no. 30426, id 140111500936976, state: waiting for server activity Number of rows inserted 0, updated 0, deleted 0, read 0 0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s ## 确保插入、更新、删除为0
上面一系列确认工作完成之后,就可以进行恢复操作了。还记得刚才我们记录的删除文件吗?如下所示:
#ll/proc/30426/fd|egrep'ib |ibdata' lrwx------1 root root 64 9月24 16:51 10->/u2/mysql/data/iblogfile1 lrwx------1 root root 64 9月24 16:51 11->/u2/mysql/data/ib logfile2 lrwx------1 root root 64 9月24 16:51 4->/u2/mysql/data/ibdata1 lrwx------1 root root 64 9月24 16:51 9->/u2/mysql/data/ib logfile0
把这些文件复制到原来的目录下:
#cd /proc/10755/fd #cp 10/u2/mysql/data/ib logfile1 #cp 11/u2/mysql/data/ib logfile2 #cp 4 /u2/mysql/data/ibdata1 #cp 9/u2/mysql/data/ib logfile0
然后修改用户属性:
#cd /u2/mysql/data/ #chown mysql:mysql ib*
现在,只需要重启MySQL即可。重启命令如下:
/etc/init.d/mysql restart
友情提醒:千万不要在生产环境下测试。
3.3.8 update忘加where条件误操作恢复(模拟Oracle闪回功能)
我相信很多人都遇到过忘带where条件,结果执行了update后把整张表的数据都给改了的情况。传统的解决方法是:利用最近的全量备份+增量binlog备份,恢复到误操作之前的状态,但是此方法有一个弊端,那就是随着表的记录增大,binlog的增多,恢复起来会很费时费力。
现在有一个简单的方法,可以恢复到误操作之前的状态。听起来这方法似乎利用的是Oracle的闪回功能,但MySQL目前(包括最新的V5.6版本)还不具有这样的功能,不过,我们完全可以模拟出这一功能来。使用该方法前,记得要将binlog日志设置为binlog_format = ROW,如果是STATEMENT,这个方法是无效的。切记!
下面来演示一下:
现在有一张学生表,要把小于60分的成绩更新成不及格。命令如下:
mysql> select * from student; +----+--------+--------+--------+ | id | name | class | score | +----+--------+--------+--------+ | 1| a | 1 | 56 | | 2| b | 1 | 61 | | 3| c | 2 | 78 | | 4| d | 2 | 45 | | 5| e | 3 | 76 | | 6| f | 3 | 89 | | 7| g | 4 | 43 | | 8| h | 4 | 90 | +----+--------+--------+--------+ 8 rows in set (0.02 sec)
结果,在执行操作时忘带where条件了,如下所示:
mysql> update student set score='failure'; Query OK, 8 rows affected (0.11 sec) Rows matched:8 Changed:8 Warnings:0 mysql> select * from student; +----+---------+--------+---------+ |id|name|class|score | +----+---------+--------+---------+ | 1|a |1 |failure| | 2|b |1 |failure| | 3|c |2 |failure| | 4|d |2 |failure| | 5|e |3 |failure| | 6|f |3 |failure| | 7|g |4 |failure| | 8|h |4 |failure| +----+---------+--------+---------+ 8 rows in set (0.01 sec)
这致使整张表的记录都更新成不及格了。
下面开始恢复:
首先,创建一个普通权限的账号(切记不能是SUPER权限),例如:
GRANT ALL PRIVILEGES ON yourDB.*TO'admin read only'@'%'IDENTIFIED BY'123456'; flush privileges;
把read_only打开,设置数据库只读,命令如下:
mysql>set global read only=1; Query OK, 0 rows affected (0.01 sec)
把刚才创建的admin_read_only账号给运维人员,让运维人员把前端程序(PHP/JSP/. NET等)的用户名改一下,然后重启前端程序(PHP/JSP/.NET等),这样再连接进来的用户对数据库进行访问时就只能读不能写了,这是为了保证恢复的一致性。
下面,通过binlog先找到那条语句:
[root@M1 data]# /usr/local/mysql/bin/mysqlbinlog --no-defaults -v -v --base64-output=DECODE-ROWS mysql-bin.000001 | grep -B 15 'failure'| more /*! */; # at 192 #121124 23:55:15 server id 25 end log pos 249 CRC32 0x83a12fbc Table map: 'test'. 'student'mapped to number 76 # at 249 #121124 23:55:15 server id 25 end log pos 549 CRC32 0xcf7d2635 Update rows: table id 76 flags: STMT END F ### UPDATE test.student ### WHERE ### @11=1/*INT meta=0 nullable=0 is null=0*/ ### @2='a'/*VARSTRING(18)meta=18 nullable=1 is null=0*/ ### @3=1/*INT meta=0 nullable=1 is null=0*/ ### @4='56'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### SET ### @11=1/*INT meta=0 nullable=0 is null=0*/ ### @2='a'/*VARSTRING(18)meta=18 nullable=1 is null=0*/ ### @3=1/*INT meta=0 nullable=1 is null=0*/ ### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### UPDATE test.student ### WHERE ### @1=2/*INT meta=0 nullable=0 is null=0*/ ### @2='b'/*VARSTRING(18)meta=18 nullable=1 is null=0*/ ### @3=1/*INT meta=0 nullable=1 is null=0*/ ### @4='61'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### SET ### @1=2/*INT meta=0 nullable=0 is null=0*/ ### @2='b'/*VARSTRING(18)meta=18 nullable=1 is null=0*/ ### @3=1/*INT meta=0 nullable=1 is null=0*/ ### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ --More--
然后把那条binlog给导出来:
[root@M1 data]# /usr/local/mysql/bin/mysqlbinlog
--no-defaults -v -v --base64-output=DECODE-ROWS
mysql-bin.000001 | sed -n '/# at 249/, /COMMIT/p' > /opt/1.txt
[root@M1 data]#
[root@M1 data]# more /opt/1.txt
# at 249
#121124 23:55:15 server id 25 end log pos 549 CRC32 0xcf7d2635 Update rows: table id 76 flags: STMT END F
### UPDATE test.student
### WHERE
### @11=1/*INT meta=0 nullable=0 is null=0*/
### @2='a'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=1/*INT meta=0 nullable=1 is null=0*/
### @4='56'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### SET
### @11=1/*INT meta=0 nullable=0 is null=0*/
### @2='a'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=1/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### UPDATE test.student
### WHERE
### @1=2/*INT meta=0 nullable=0 is null=0*/
### @2='b'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=1/*INT meta=0 nullable=1 is null=0*/
### @4='61'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### SET
### @1=2/*INT meta=0 nullable=0 is null=0*/
### @2='b'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=1/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### UPDATE test.student
### WHERE
### @1=3/*INT meta=0 nullable=0 is null=0*/
### @2='c'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=2/*INT meta=0 nullable=1 is null=0*/
### @4='78'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### SET
### @1=3/*INT meta=0 nullable=0 is null=0*/
### @2='c'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=2/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### UPDATE test.student
### WHERE
### @1=4/*INT meta=0 nullable=0 is null=0*/
### @2='d'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=2/*INT meta=0 nullable=1 is null=0*/
### @4='45'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### SET
### @1=4/*INT meta=0 nullable=0 is null=0*/
### @2='d'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=2/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### UPDATE test.student
### WHERE
### @1=5/*INT meta=0 nullable=0 is null=0*/
### @2='e'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @33=3/*INT meta=0 nullable=1 is null=0*/
### @4='76'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### SET
### @1=5/*INT meta=0 nullable=0 is null=0*/
### @2='e'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @33=3/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### UPDATE test.student
### WHERE
### @1=6/*INT meta=0 nullable=0 is null=0*/
### @2='f'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @33=3/*INT meta=0 nullable=1 is null=0*/
### @4='89'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### SET
### @1=6/*INT meta=0 nullable=0 is null=0*/
### @2='f'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @33=3/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### UPDATE test.student
### WHERE
### @1=7/*INT meta=0 nullable=0 is null=0*/
### @2='g'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=4/*INT meta=0 nullable=1 is null=0*/
### @4='43'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### SET
### @1=7/*INT meta=0 nullable=0 is null=0*/
### @2='g'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=4/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### UPDATE test.student
### WHERE
### @1=8/*INT meta=0 nullable=0 is null=0*/
### @2='h'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=4/*INT meta=0 nullable=1 is null=0*/
### @4='90'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
### SET
### @1=8/*INT meta=0 nullable=0 is null=0*/
### @2='h'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=4/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
# at 549
#121124 23:55:15 server id 25 end log pos 580 CRC32 0x378c91b0 Xid=531
COMMIT/*! */;
[root@M1 data]#
其中,这些是误操作之前的数据:
### @1=8/*INT meta=0 nullable=0 is null=0*/
### @2='h'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=4/*INT meta=0 nullable=1 is null=0*/
### @4='90'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
这些是误操作之后的数据:
### @1=8/*INT meta=0 nullable=0 is null=0*/
### @2='h'/*VARSTRING(18)meta=18 nullable=1 is null=0*/
### @3=4/*INT meta=0 nullable=1 is null=0*/
### @4='failure'/*VARSTRING(30)meta=30 nullable=1 is null=0*/
这里,@1、@2、@3、@4对应的表字段分别是id、name、class、score。
现在,就要进行最后一步的恢复操作了,把这些binlog转换成SQL语句,然后将其导入进去。
[root@M1 opt]# sed '/WHERE/{:a; N; /SET/! ba; s/\([^\n]*\)\n\(.*\)\n\(.*\)/\3\n\2\n\1/}' 1.txt
|sed-r'/WHERE/{:a; N; /@4/! ba; s/### @2.*//g}'
| sed 's/### //g; s/\/\*.*/, /g'
| sed '/WHERE/{:a; N; /@1/! ba; s/, /; /g}; s/#.*//g; s/COMMIT, //g'
| sed '/^$/d' > ./recover.sql
[root@M1 opt]#
[root@M1 opt]# cat recover.sql
UPDATE test.student
SET
@11=1 ,
@2='a' ,
@3=1 ,
@4='56' ,
WHERE
@11=1 ;
UPDATE test.student
SET
@1=2 ,
@2='b' ,
@3=1 ,
@4='61' ,
WHERE
@1=2 ;
UPDATE test.student
SET
@1=3 ,
@2='c' ,
@3=2 ,
@4='78' ,
WHERE
@1=3 ;
UPDATE test.student
SET
@1=4 ,
@2='d' ,
@3=2 ,
@4='45' ,
WHERE
@1=4 ;
UPDATE test.student
SET
@1=5 ,
@2='e' ,
@33=3 ,
@4='76' ,
WHERE
@1=5 ;
UPDATE test.student
SET
@1=6 ,
@2='f' ,
@33=3 ,
@4='89' ,
WHERE
@1=6 ;
UPDATE test.student
SET
@1=7 ,
@2='g' ,
@3=4 ,
@4='43' ,
WHERE
@1=7 ;
UPDATE test.student
SET
@1=8 ,
@2='h' ,
@3=4 ,
@4='90' ,
WHERE
@1=8 ;
[root@M1 opt]#
再把@1、@2、@3、@4对应的表字段(id、name、class、score)替换掉,如下所示:
[root@M1 opt]# sed -i 's/@1/id/g; s/@2/name/g; s/@3/class/g; s/@4/score/g' recover.sql
[root@M1 opt]# sed -i -r 's/(score=.*), /\1/g' recover.sql
[root@M1 opt]#
[root@M1 opt]# cat recover.sql
UPDATE test.student
SET
id=1 ,
name='a' ,
class=1 ,
score='56'
WHERE
id=1 ;
UPDATE test.student
SET
id=2 ,
name='b' ,
class=1 ,
score='61'
WHERE
id=2 ;
UPDATE test.student
SET
id=3 ,
name='c' ,
class=2 ,
score='78'
WHERE
id=3 ;
UPDATE test.student
SET
id=4 ,
name='d' ,
class=2 ,
score='45'
WHERE
id=4 ;
UPDATE test.student
SET
id=5 ,
name='e' ,
class=3 ,
score='76'
WHERE
id=5 ;
UPDATE test.student
SET
id=6 ,
name='f' ,
class=3 ,
score='89'
WHERE
id=6 ;
UPDATE test.student
SET
id=7 ,
name='g' ,
class=4 ,
score='43'
WHERE
id=7 ;
UPDATE test.student
SET
id=8 ,
name='h' ,
class=4 ,
score='90'
WHERE
id=8 ;
[root@M1 opt]#
下面进行恢复操作:
mysql> select * from student;
+----+---------+--------+----------+
|id|name |class |score |
+----+---------+--------+----------+
| 1|a |1 |failure|
| 2|b |1 |failure|
| 3|c |2 |failure|
| 4|d |2 |failure|
| 5|e |3 |failure|
| 6|f |3 |failure|
| 7|g |4 |failure|
| 8|h |4 |failure|
+----+---------+--------+----------+
8 rows in set (0.02 sec)
mysql> source /opt/recover.sql
Query OK, 1 row affected (0.11 sec)
Rows matched:1 Changed:1 Warnings:0
Query OK, 1 row affected (0.95 sec)
Rows matched:1 Changed:1 Warnings:0
Query OK, 1 row affected (0.16 sec)
Rows matched:1 Changed:1 Warnings:0
Query OK, 1 row affected (0.03 sec)
Rows matched:1 Changed:1 Warnings:0
Query OK, 1 row affected (0.80 sec)
Rows matched:1 Changed:1 Warnings:0
Query OK, 1 row affected (0.08 sec)
Rows matched:1 Changed:1 Warnings:0
Query OK, 1 row affected (0.09 sec)
Rows matched:1 Changed:1 Warnings:0
Query OK, 1 row affected (0.07 sec)
Rows matched:1 Changed:1 Warnings:0
mysql> select * from student;
+----+------+-------+-------+
|id|name |class |score |
+----+---------+--------+---------+
| 1|a |1 |56 |
| 2|b |1 |61 |
| 3|c |2 |78 |
| 4|d |2 |45 |
| 5|e |3 |76 |
| 6|f |3 |89 |
| 7|g |4 |43 |
| 8|h |4 |90 |
+----+------+-------+-------+
8 rows in set(0.02 sec)
mysql>
友情提醒:千万不要在生产环境下测
3.3.9 delete忘加where条件误操作恢复(模拟Oracle闪回功能)
如果在delete时忘加where条件了怎么办?可按照上面的方法依葫芦画瓢,下面来演示一下delete操作时忘加where条件的误操作恢复。
表数据为:
mysql> select * from qq1; +----+------------+--------------+---------------+ |id|class id|fist name|last name| +----+------------+--------------+---------------+ | 1| 101 |lo |1gang | | 2| 101 |zhou |2gang | | 3| 102 |wong |3gang | | 4| 101 |huo |4gang | | 5| 102 |son |5gang | | 6| 102 |dong |6gang | | 7| 103 |qo |7gang | | 8| 103 |dao |8gang | +----+------------+--------------+---------------+ 8 rows in set (0.03 sec) 现在要删除id大于5的记录: mysql> delete from qq1 where id > 5; Query OK, 3 rows affected (0.00 sec) mysql> select * from qq1; +----+------------+---------------+---------------+ |id|class id |fist name |last name| | 1| 101|lo |1gang | | 2| 101|zhou |2gang | | 3| 102|wong |3gang | | 4| 101|huo |4gang | | 5| 102|son |5gang | +----+------------+---------------+---------------+ 5 rows in set (0.00 sec) 现在要分析binlog,以便把误操作delete的语句保存到文本里: [root@hadoop-datanode5 data]# mysqlbinlog --no-defaults--base64-output=decode-rows-v-v mysql-bin.000001 | sed -n '/### DELETE FROM test.qq1/, /COMMIT/p' > /root/delete.txt [root@hadoop-datanode5 ~]# cat /root/delete.txt ### DELETE FROM test.qq1 ### WHERE ### @1=6/*INT meta=0 nullable=0 is null=0*/ ### @2=102/*INT meta=0 nullable=1 is null=0*/ ### @3='dong'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### @4='6gang'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### DELETE FROM test.qq1 ### WHERE ### @1=7/*INT meta=0 nullable=0 is null=0*/ ### @2=103/*INT meta=0 nullable=1 is null=0*/ ### @3='qo'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### @4='7gang'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### DELETE FROM test.qq1 ### WHERE ### @1=8/*INT meta=0 nullable=0 is null=0*/ ### @2=103/*INT meta=0 nullable=1 is null=0*/ ### @3='dao'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### @4='8gang'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ # at 310 #130526 9:00:02 server id 140 end log pos 337 Xid=88 COMMIT/*! */; ### DELETE FROM test.qq1 ### WHERE ### @1=6/*INT meta=0 nullable=0 is null=0*/ ### @2=103/*INT meta=0 nullable=1 is null=0*/ ### @3='aa'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ ### @4='aa1'/*VARSTRING(30)meta=30 nullable=1 is null=0*/ # at 688 #130526 9:21:42 server id 140 end log pos 715 Xid=92 COMMIT/*! */; 接下来要把它转换为标准的SQL语句: [root@hadoop-datanode5 ~]#cat delete.txt | sed -n '/###/p' | sed 's/### //g; s/\/\*.*/, /g; s/DELETE FROM/INSERT INTO/g; s/WHERE/SELECT/g; ' | sed -r 's/(@4.*), /\1; /g' | sed 's/@[1-9]=//g' > insert.sql [root@hadoop-datanode5 ~]# [root@hadoop-datanode5 ~]# cat insert.sql INSERT INTO test.qq1 SELECT 6, 102 , 'dong' , '6gang' ; INSERT INTO test.qq1 SELECT 7, 103 , 'qo' , '7gang' ; INSERT INTO test.qq1 SELECT 8, 103 , 'dao' , '8gang' ; INSERT INTO test.qq1 SELECT 6, 103 , 'aa' , 'aa1' ; [root@hadoop-datanode5 ~]# 之后将其导入数据库里即可,如下所示: mysql> select * from qq1; +----+------------+---------------+---------------+ |id|class id |fist name |last name| +----+------------+---------------+---------------+ | 1| 101|lo |1gang | | 2| 101|zhou |2gang | | 3| 102|wong |3gang | | 4| 101|huo |4gang | | 5| 102|son |5gang | +----+------------+---------------+---------------+ 5 rows in set (0.00 sec) mysql> source /root/insert.sql Query OK, 1 row affected (0.01 sec) Records:1 Duplicates:0 Warnings:0 Query OK, 1 row affected (0.00 sec) Records:1 Duplicates:0 Warnings:0 Query OK, 1 row affected (0.00 sec) Records:1 Duplicates:0 Warnings:0 mysql> select * from qq1; +----+------------+---------------+---------------+ |id|class id |fist name |last name| +----+------------+---------------+---------------+ | 1| 101|lo |1gang | | 2| 101|zhou |2gang | | 3| 102|wong |3gang | | 4| 101|huo |4gang | | 5| 102|son |5gang | | 6| 102|dong |6gang | | 7| 103|qo |7gang | | 8| 103|dao |8gang | +----+------------+---------------+---------------+ 8 rows in set (0.00 sec) 友情提醒:千万不要在生产环境下测试。
第四章、复制故障处理
在发生故障进行切换后,经常遇到的问题就是同步报错,我见过很多DBA都是执行命令“set global sql_slave_skip_counter=1; ”跳过并忽略错误,这种方法虽然可以达到让同步复制继续运行的目的,但其实就是掩耳盗铃,因为此时slave数据已经不一致了。
另一种方法就是在主库上MySQLdump导出数据,然后在slave上恢复,当数据很小(比如几个GB)的时候,这样做可以,没有任何问题。但如果你的公司数据量很庞大,大到150~200 GB,此时单纯地用导出和导入方法,太耗费时间,不可取。经过一段时间的摸索,我总结了几种处理方法。本章将针对这些方法进行讲解。
4.1 最常见的3种故障
在说明最常见的3种故障之前,先来看一下异步复制和半同步复制的区别:
❑ 异步复制:简单地说就是master把binlog发送过去,不管slave是否接收完,也不管是否执行完,这一动作就结束了。
❑ 半同步复制:简单地说就是master把binlog发送过去,slave确认接收完,但不管它是否执行完,给master一个信号我这边收到了,这一动作就结束了。(半同步复制patch谷歌写的代码,MySQL5.5上正式应用。)
异步的劣势是:当master上写操作繁忙时,当前POS点,例如,是10,而slave上IO_THREAD线程接收过来的是3,此时master宕机,会造成相差7个点未传送到slave上而数据丢失。
接下来要介绍的这3种故障是在HA集群切换时产生的,由于是异步复制,且sync_binlog=0,会造成一小部分binlog没接收完,从而导致同步报错。
4.1.1 在master上删除一条记录时出现的故障
笔者曾碰到过这种问题,在master上删除一条记录后,slave上因找不到该记录而报错,报错信息如下:
Last SQL Error: Could not execute Delete rows event on table hcy.t1; Can't find record in 't1', Error code: 1032; handler error HA ERR KEY NOT FOUND; the event's master log MySQL-bin.000006, end log pos 254
出现这种情况是因为主机上已将其删除了,对此,可采取从机直接跳过的方式解决,命令如下:
stop slave; set global sql slave skip counter=1; start slave;
对于这种情况,我写了一个脚本skip_error_replication.sh来帮助处理,该脚本默认跳过10个错误(只会针对这种情况跳,其他情况还是会输出错误结果,等待处理),这个脚本是参考maakit工具包的mk-slave-restart原理用shell写的,由于mk-slave-restart脚本是不管什么错误一律跳过,这样会造成主从数据不一致,因此我在该脚本的功能方面定义了一些自己的东西,使其不是无论什么错误都一律跳过),脚本如下:
#! /bin/bash
## 此脚本是用来自动处理同步报错的,默认跳过10次。
##
##只有Last SQL Error: Could not execute Delete rows event on table hcy.t1; Can't find record##in't1', Error code:
1032; handler error HA ERR KEY NOT FOUND; the event's master log##MySQL-bin.000003, end log pos 253
## 这种情况才跳过,其他情况,需要自行处理,以免丢失数据。
##
## by hechunyang
###############################################################################
export LANG=zh CN
./root/.bash profile
v dir=/usr/local/MySQL/bin/
v user=root
v passwd=123456
v log=/home/logs
v times=10
if[-d"${v log}"]; then
echo"${v log}has existed before."
else
mkdir${v log}
fi
echo"">${v log}/slave status.log
echo"">${v log}/slave status error.log
count=1
while true
do
Seconds Behind master=$(${v dir}MySQL-u${v user}-p${v passwd}-e"show slave status\G; "|awk-F':''/
Seconds Behind master/{print$2}')
if[${Seconds Behind master}! ="NULL"]; then
echo "slave is ok! "
${v dir}MySQL-u${v user}-p${v passwd}-e"show slave status\G; ">>${v log}/slave status.log
break
else
echo"">>${v log}/slave status error.log
date>>${v log}/slave status error.log
echo"">>${v log}/slave status error.log
${v dir}MySQL-u${v user}-p${v passwd}-e"show slave status\G">>${v log}/slave status error.log
${v dir}MySQL-u${v user}-p${v passwd}-e"show slave status\G"|egrep'Delete rows'>/dev/null 2>&1
if [ $? = 0 ]; then
${v dir}MySQL-u${v user}-p${v passwd}-e"stop slave; SET GLOBAL sql slave skip counter=1; start slave; "
else
${v dir}MySQL-u${v user}-p${v passwd}-e"show slave status\G" |grep'Last SQL Error'
break
fi
let count++
if[$count-gt${v times}]; then
break
else
${v dir}MySQL-u${v user}-p${v passwd}-e"show slave status\G">>${v log}/slave status error.log
sleep 2
continue
fi
fi
done
4.1.2 主键重复
主从数据不一致时,slave上已经有该条记录,但我们又在master上插入了同一条记录,此时就会报错,报错信息如下:
Last SQL Error: Could not execute Write rows event on table hcy.t1; Duplicate entry '2' for key 'PRIMARY', Error code:1062; handler error HA ERR FOUND DUPP KEY; the event's master log MySQL-bin.000006, end log pos 924
解决方法:在slave上使用命令“desc hcy.t1; ”先查看一下表结构,如下所示:
MySQL> desc hcy.t1; +---------+-----------+-------+------+-----------+--------+ |Field |Type |Null|Key|Default|Extra| +---------+-----------+-------+------+-----------+--------+ |id |int(11) |NO |PRI |0 | | |name|char(4)|YES | |NULL | | +---------+-----------+-------+------+-----------+--------+ 2 rows in set (0.03 sec)
查看该表字段信息,得到主键的字段名。
接着删除重复的主键,命令如下:
MySQL> delete from t1 where id=2; Query OK, 1 row affected (0.00 sec)
然后开启同步复制功能,命令如下:
MySQL> start slave; Query OK, 0 rows affected (0.00 sec) MySQL> show slave status\G; ... slave IO Running: Yes slave SQL Running: Yes ... MySQL> select * from t1 where id=2;
完成上述操作后,还要在master上和slave上再分别确认一下,确保执行成功。
4.1.3 在master上更新一条记录,而slave上却找不到
主从数据不一致时,master上已经有该条记录,但slave上没有这条记录,之后若在master上又更新了这条记录,此时就会报错,报错信息如下:
Last SQL Error: Could not execute Update rows event on table hcy.t1; Can't find record in't1', Error code:1032; handler error HA ERR KEY NOT FOUND; the event's master log MySQL-bin.000010, end log pos 794
解决方法:在master上,用MySQLbinlog分析一下出错的binlog日志在干什么,如下所示:
[root@vm01 data]# /usr/local/MySQL/bin/MySQLbinlog --no-defaults -v -v --base64-output=DECODE-ROWS MySQL-bin.000010 | grep -A '10' 794 #120302 12:08:36 server id 22 end log pos 794 Update rows: table id 33 flags: STMT END F ###UPDATE hcy.t1###WHERE### @1=2/*INT meta=0 nullable=0 is null=0*/ ### @2='bbc'/*STRING(4)meta=65028 nullable=1 is null=0*/ ###SET### @1=2/*INT meta=0 nullable=0 is null=0*/ ### @2='BTV'/*STRING(4)meta=65028 nullable=1 is null=0*/ # at 794 #120302 12:08:36 server id 22 end log pos 821 Xid=60 COMMIT/*! */; DELIMITER ; # End of log file ROLLBACK /* added by MySQLbinlog */; /*!50003 SET COMPLETION TYPE=@OLD COMPLETION TYPE*/; [root@vm01 data]#
从上面的信息来看,是在更新一条记录。
接着,在slave上查找一下更新后的那条记录,应该是不存在的。命令如下:
MySQL> select * from t1 where id=2; Empty set (0.00 sec
然后再到master查看,命令如下:
MySQL> select * from t1 where id=2; +----+--------+ | id | name | +----+--------+ | 2|BTV | +----+--------+ 1 row in set (0.00 sec)
可以看到,这里已经找到了这条记录。
最后把丢失的数据填补到在slave上,命令如下:
MySQL> insert into t1 values (2, 'BTV'); Query OK, 1 row affected (0.00 sec) MySQL> select * from t1 where id=2; +----+--------+ | id | name | +----+--------+ 2|BTV | +----+--------+ 1 row in set (0.00 sec)
完成上述操作后,跳过报错即可,命令如下:
MySQL>stop slave; set global sql slave skip counter=1; start slave; Query OK, 0 rows affected (0.01 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) MySQL> show slave status\G; ... slave IO Running: Yes slave SQL Running: Yes ...
4.2 特殊情况:slave的中继日志relay-log损坏
当slave意外宕机时,有可能会损坏中继日志relay-log,再次开启同步复制时,报错信息如下:
Last SQL Error: Error initializing relay log position: I/O error reading the header from the binary log Last SQL Error: Error initializing relay log position: Binlog has bad magic number; It's not a binary log file that can be used by this version of MySQL
解决方法:找到同步的binlog日志和POS点,然后重新进行同步,这样就可以有新的中继日志了。
下面来看个例子,这里模拟了中继日志损坏的情况,查看到的信息如下:
MySQL> show slave status\G; *************************** 1. row *************************** master Log File: MySQL-bin.000010 Read master Log Pos:1191 Relay Log File: vm02-relay-bin.000005 Relay Log Pos:253 Relay_master_Log_File: MySQL-bin.000010 slave IO Running: Yes slave SQL Running: No Replicate Do DB: Replicate Ignore DB: Replicate Do Table: Replicate Ignore Table: Replicate Wild Do Table: Replicate Wild Ignore Table: Last Errno:1593 Last Error: Error initializing relay log position: I/O error reading the header from the binary log Skip Counter:1 Exec_master_Log_Pos: 821 其中,涉及几个重要参数: ❑ slave_IO_Running :接收master的binlog信息 ○ master_Log_File:正在读取master上binlog日志名。 ○ Read_master_Log_Pos:正在读取master上当前binlog日志POS点。 ❑ slave_SQL_Running:执行写操作。 ○ Relay_master_Log_File:正在同步master上的binlog日志名。 ○ Exec_master_Log_Pos:正在同步当前binlog日志的POS点。 以Relay_master_Log_File参数值和Exec_master_Log_Pos参数值为基准。 Relay_master_Log_File: MySQL-bin.000010 Exec_master_Log_Pos: 821 接下来可以重置主从复制了,操作如下: MySQL> stop slave; Query OK, 0 rows affected (0.01 sec) MySQL>CHANGE master TO master LOG FILE='MySQL-bin.000010', master LOG POS=821; Query OK, 0 rows affected (0.01 sec) MySQL> start slave; Query OK, 0 rows affected (0.00 sec)
重新建立完主从复制以后,就可以查看一下状态信息了,如下所示:
MySQL> show slave status\G; *************************** 1. row *************************** slave IO State: Waiting for master to send event master Host:192.168.8.22 master User: repl master Port:3306 Connect Retry:10 master Log File: MySQL-bin.000010 Read master Log Pos:1191 Relay Log File: vm02-relay-bin.000002 Relay Log Pos:623 Relay master Log File: MySQL-bin.000010 slave_IO_Running: Yes slave_SQL_Running: Yes Replicate Do DB: Replicate Ignore DB: Replicate Do Table: Replicate Ignore Table: Replicate Wild Do Table: Replicate Wild Ignore Table: Last Errno:0 Last Error: Skip Counter:0 Exec master Log Pos:1191 Relay Log Space:778 Until Condition: None Until Log File: Until Log Pos:0 master SSL Allowed: No master SSL CA File: master SSL CA Path: master SSL Cert: master SSL Cipher: master SSL Key: Seconds Behind master:0 master SSL Verify Server Cert: No Last IO Errno:0 Last IO Error: Last SQL Errno:0 Last SQL Error:
通过这种方法我们已经修复了中继日志。是不是有些麻烦?其实如果你有仔细看完第1章的新特性,会发现MySQL5.5已经考虑到slave宕机中继日志损坏这一问题了,即在slave的配置文件my.cnf里要增加一个参数relay_log_recovery =1就可以了,前面已经介绍了,这里不再阐述。
4.3 人为失误
这种情况在生产环境中并不常见,下面记录了一次server-id重复导致的主从同步复制报错。
多台slave存在server-id重复
这个错误一般是初级DBA经常遇到的,他们在进行主从配置时,直接把master的my、cnf复制到slave上,却忘记了修改slave上的server-id,报错信息如下:
slave: received end packet from server, apparent master shutdown: slave I/O thread: Failed reading log event, reconnecting to retry, log 'MySQL-bin.000012' at position 106
在这种情况下,同步会一直延时,永远也同步不完,error错误日志里会一直出现上面两行信息。解决方法就是把slave机器上的server-id改成不一致,然后重启MySQL即可。
4.4 避免在master上执行大事务
这是一个真实的案例,一张大表大约有70 GB,因为业务需要,要删除一些数据,由于删除的ID关联的数据太多,该删除操作变成了一个大事务,一下子就把slave给卡死了,当时的现象是执行“show slave status\G; ”时,Exec_master_Log_Pos值一直不发生变化,但Seconds_Behind_master的值却越来越大,致使同步落后越来越多。
当时的SQL语句是:
delete from bigtable where UserId=v userid;
表数据如图4-1所示。

碰到这个问题后,我想出的解决办法是改为用存储过程,每删除1000条事务就提交一次,循环操作直至删除完毕。经过优化,行锁的范围变小了,性能也就变好了。相关代码如下:
DELIMITER $$
USE BIGDB$$
DROP PROCEDURE IF EXISTS BIG table delete 1k$$
CREATE PROCEDURE BIG table delete 1k(IN v UserId INT)
BEGIN
del 1k:LOOP
delete from BIGDB.BIGTABLE where UserId=v UserId limit 1000;
select row count()into@count;
IF @count = 0 THEN
select CONCAT('BIGDB.BIGTABLE UserId=', v UserId, 'is', @count, 'rows.')as BIGTABLE delete finish;
LEAVE del 1k;
END IF;
select sleep(1);
END LOOP del 1k;
END$$
DELIMITER ;
存储过程上线后,观察一段时间,同步复制时,slave复制正常,问题解决。
4.5 slave_exec_mode参数可自动处理同步复制错误
大家有没有遇到这种情况,假日里,你正在外面享受生活,突然手机收到一条短信——主从同步报错,会让你原本很好的心情一下子沉入谷底。因为如果你处理不及时,同步复制会因报错而中断,这样就会对业务产生影响(如果你没有做特殊的设置,MySQL是不会自动跳过这个错误的),尤其是开启了读写分离功能后——用户发了一个帖子,半天没找到自己刚才发的帖子,投诉的电话就得在老板的耳旁响起了。
那么该如何解决呢?slave_exec_mode这个参数可以帮助你。
你可以动态设置,如下所示:
set global slave exec mode='IDEMPOTENT';
其默认值是STRICT(严格模式),如图4-2所示。

注意
设置完毕后,并不能立即生效,需要重启下复制进程,第一步:关闭同步复制;第二步:开启同步复制,这样才可以。
设置完毕后,当出现的1023错误(记录没找到)和1062错误(主键重复)时,就会自动跳过该错误,并且记录到错误日志里。其实,slave_exec_mode参数和slave_skip_errors参数的作用是一样的,只不过slave_skip_errors参数必须加到配置文件my.cnf里然后重启MySQL,而slave_exec_mode参数可以动态设置。
另外,你还可以在Nagios主机上做个监控,当出现同步报错时,执行相应的命令:
MySQL-uroot-p123456-h(yourIP)-e"set global slave exec mode='IDEMPOTENT'; "
下面是我实现的一个脚本skip_slave_error.sh:
#! /bin/bash
user=admin
passwd=123456
port=3306
MySQLpath=/usr/local/MySQL/bin
for hostip in 'cat slaveip.txt'
do
result=$($MySQLpath/MySQL -u$user -p$passwd -h$hostip -P$port \
-e"show slave status\G"|awk-F": "'/slave SQL Running/{print$2}')
if [ "$result" ! = "Yes" ]; then
$MySQLpath/MySQL -u$user -p$passwd -h$hostip -P$port \
-e"set global slave exec mode='IDEMPOTENT'; "
$MySQLpath/MySQL -u$user -p$passwd -h$hostip -P$port \
-e "stop slave; "
$MySQLpath/MySQL -u$user -p$passwd -h$hostip -P$port \
-e "start slave; "
echo "replication is error and skip" | mail -s "replcation Alert" hechunyang@139.com \
-- -f nagiosadmin@139.com -F nagiosadmin
#发送一封邮件并短信通知你同步报错已经跳过了。
fi
done
slaveip.txt文件填写你的slave机器的IP,如下面这样一行一行添加,上面的脚本会调用slaveip.txt:
# cat slaveip.txt 192.168.8.22 192.168.8.23 192.168.8.24 192.168.8.25 192.168.8.26
然后将脚本skip_slave_error.sh加入到crontab里,每十分钟检查一次。
*/10**** bash/home/hechunyang/skip slave error.sh
这样可以尽可能地减少业务影响的范围扩大,等你到家时再做下一步处理。
参考手册:

4.6 如何验证主从数据一致
Maatkit是一个开源的工具包,为MySQL日常管理提供了帮助。目前,已被Percona公司收购并维护。其中mk-table-checksum是用来检测master和slave上的表结构和数据是否一致的。而mk-table-sync则是在主从数据不一致时,用来修复的。
注意
这两个perl脚本在运行时都会锁表,表的大小取决于执行的快慢,勿在高峰期间运行,可选择凌晨。
其使用方法如下:
[root@vm02]#mk-table-checksum h=vm01, u=admin, p=123456 \ h=vm02, u=admin, p=123456 -d hcy -t t1 Cannot connect to MySQL because the Perl DBI module is not installed or not found. Run'perl-MDBI'to see the directories that Perl searches for DBI. If DBI is not installed, try: Debian/Ubuntu apt-get install libdbi-perl RHEL/CentOS yum install perl-DBI OpenSolaris pgk install pkg:/SUNWpmdbi
[root@vm02]# 这里提示缺少perl-DBI模块,那么直接运行yum install perl-DBI。再次执行这一条命令: [root@vm02 bin]#mk-table-checksum h=vm01, u=admin, p=123456 \ h=vm02, u=admin, p=123456 -d hcy -t t1 DATABASE TABLE CHUNK HOST ENGINE COUNT CHECKSUM TIME WAIT STAT LAG hcy t1 0 vm02 InnoDB NULL 1957752020 0 0 NULL NULL hcy t1 0 vm01 InnoDB NULL 1957752020 0 0 NULL NULL [root@vm02 bin]# 如果表数据不一致,CHECKSUM的值是不相等的。 下面,解释一下输出的意思: ❑ DATABASE:数据库名 ❑ TABLE:表名 ❑ CHUNK:checksum时的近似数值 ❑ HOST:MySQL的地址 ❑ ENGINE:表引擎 ❑ COUNT:表的行数 ❑ CHECKSUM:校验值 ❑ TIME:所用时间 ❑ WAIT:等待时间 STAT:master_POS_WAIT()返回值 ❑ LAG:slave的延时时间 如果你想过滤出不相等的表,可以用mk-checksum-filter这个工具。只要在-d hcy后面加个管道符就行了。示例如下: [root@vm02~]#mk-table-checksum h=vm01, u=admin, p=123456 \ h=vm02, u=admin, p=123456 -d hcy | mk-checksum-filter hcy t2 0 vm01 InnoDB NULL 1957752020 0 0 NULL NULL hcy t2 0 vm02 InnoDB NULL 1068689114 0 0 NULL NULL
在知道有哪些表不一致后,可以用mk-table-sync这个工具来处理(如图4-3所示)。

图4-3 主从数据不一致
该工具的使用方法如下:
[root@vm02 ~]# mk-table-sync --execute --print --no-check-slave --transaction \
--databases hcy h=vm01, u=admin, p=123456 h=vm02, u=admin, p=123456
INSERT INTO'hcy'. 't2'('id', 'name')VALUES('5', 'ss')/*maatkit src db:hcy
src tbl:t2 src dsn:h=vm01, p=..., u=admin dst db:hcy dst tbl:t2
dst dsn:h=vm02, p=..., u=admin lock:0 transaction:1 changing src:0 replicate:0
bidirectional:0 pid:3246 user:root host:vm02*/;
它的工作原理是:先一行一行地检查主从库的表是否一样,如果发现有哪里不一样,就执行删除、更新、插入等操作,使其达到一致。表的大小决定着执行速度的快慢。
4.7 binlog_ignore_db引起的同步复制故障
这是我一个同事提供的案例,在MySQL master上使用binlog_ignore_db命令忽略了一个库以后,使用MySQL -e执行的所有语句就不写binlog了。听他这样说,我也觉得很奇怪,详细询问当时的情况,原来是在进行主从复制时,有一个库不复制,查了他的my.cnf配置,binlog格式为row模式,跟他要了当时的语句,如下:
MySQL -e "create table db.tb like db.tb1"
查看手册,了解到是因为忽略某个库的复制有两个参数,一个是binlog_ignore_db,另一个是replicate-ignore-db,它们的区别是:
binlog_ignore_db参数是设置在主库上的,例如,binlog_ignore_db=test,那么针对test库下的所有操作(增、删、改)都不会记录下来,这样slave在接收主库的binlog时文件量就会减少,这样做的好处是可以减少网络I/O,减少slave端I/O线程的I/O量,从而最大幅度地优化复制性能。但也存在了一个隐患,对于这个隐患,在后面的演示中会提到。
replicate-ignore-db参数是设置在从库上的,例如,replicate-ignore-db=test,那么针对test库下的所有操作(增、删、改)都不会被SQL线程执行,从性能上来说,它虽然没有binlog_ignore_db好(不管是否需要,复制的binlog都被会被I/O线程读取到slave端,这样不仅仅增加了网络I/O量,也给slave端的I/O线程增加了RelayLog的写入量),但在安全上,可以保证master和slave数据的一致性。
下面就来演示一下,创建表为什么没有记录在binlog日志里,如图4-4所示。
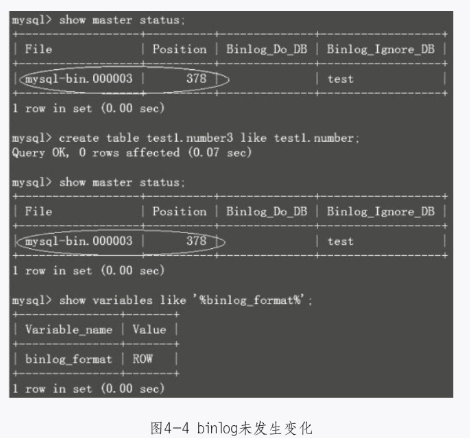
结果新创建的表在slave上一个都没有。到底是什么原因引起的呢?那就是因为没有使用use库名,如果使用了,就可以记录binlog了,如图4-5所示。
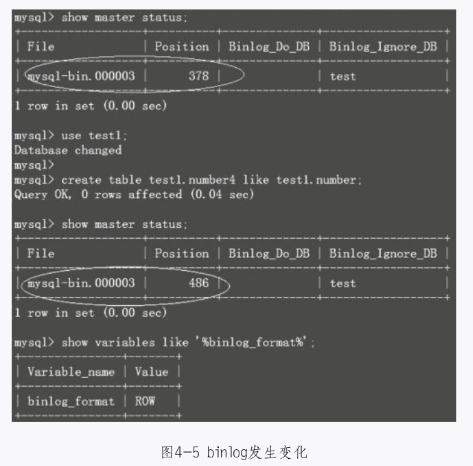
所以,如果想在slave上忽略一个库的复制,最好不要用binlog_ignore_db这个参数,使用replicate-ignore-db = yourdb取代之。
4.8 MySQL5.5.19/20同步一个Bug
当我们在用低版本MySQL5.1.43(slave)向高版本5.5.19(master)同步复制时,运维组反馈MySQL反复重启,后来,在错误日志里发现了一个Bug信息,如图4-6所示。
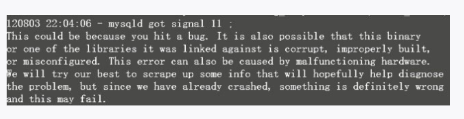
图4-6 Bug信息
后来经过排查,得知低版本向高版本同步复制,只要同步复制的点指错,主机master的MySQL服务就会循环重启,MySQL和Percona版本均是如此,但版本一致的,就不会发生此问题。如果点指对,即使同步复制因为某种原因导致报错,主机master的MySQL服务也不会循环重启。
比如master上的binlog和POS点是:
MySQL-bin.000001,107
那么你在slave上执行如下操作:
CHANGE master TO master LOG FILE='MySQL-bin.000001', master LOG POS=106;
就会触发那个BUG。有兴趣的朋友可以用那两个版本试试。官方下载地址:http://downloads.MySQL.com/archives.php,目前MySQL5.5.25a之后的版本已经修复了此BUG。但不推荐低版本向高版本同步,手册上解释:

意思为:MySQL支持从高版本向低版本同步(即master是低版本,slave是高版本,那么slave向master同步复制时是兼容的,没有问题)。

但反过来,就会存在问题。尤其是字符集设置这块,如图4-7所示。
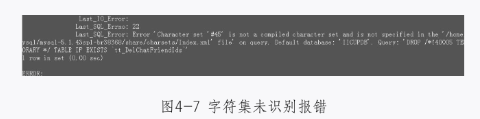
图4-7 字符集未识别报错
在低版本V5.1.43里,是不识别高版本这种字符集的,如图4-8所示。
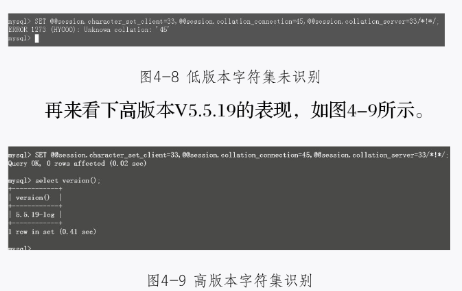
这条语句是可以识别的。
所以在这里提醒大家一下,如果master的版本低,slave的版本高,做主从复制是没有问题,可以兼容。但反过来,master的版本高,slave的版本低,就会出现文中这种情形,在日常操作中格外注意。
4.9 恢复slave从机上的某几张表的简要方法
在日常工作中,同步报错是数据库管理员遇到最多的一个问题,如果你修复后发现还没有解决,通常的方法就是在master上重新导出一份,然后在slave上恢复。这个方法是针对整个库不是很大的情况的,那如果是较大呢?全部导出再导入耗时就很长。
这时,就要通过特殊的方法恢复某几张表,例如,有a1、b1、c1这三张表的数据跟master上的不一致,操作方法如下:
1)停止slave复制,命令如下:
MySQL>stop slave;
2)在主库上导出这三张表,并记录下同步的binlog和POS点:
#MySQLdump-uroot-p123456-q--single-transaction--master-data=2 yourdb a1 b1 c1>./a1 b1 c1.sql
3)查看a1_b1_c1.sql文件,找出记录的binlog和POS点:
#more a1 b1 c1.sql
例如master LOG FILE='MySQL-bin.002974', master LOG POS=55056952;
4)把a1_b1_c1.sql复制到slave机器上,并做Change master to指向:
MySQL>start slave until master LOG FILE='MySQL-bin.002974', master LOG POS=55056952;
直到sql_thread线程为NO,这期间的同步报错一律跳过即可,可用如下命令跳过:
stop slave; set global sql slave skip counter=1; start slave;
注意
这一步是为了保障其他表的数据不丢失,一直同步,直到同步到那个点为止,a1、b1、c1表的数据在之前的导出已经生成了一份快照,只需要导入后开启同步即可。
5)在slave机器上导入a1_b1_c1.sql,命令如下:
#MySQL-uroot-p123456 yourdb<./a1 b1 c1.sql
6)导入完毕后,开启同步即可。
MySQL>start slave;
这样我们就恢复了3张表,并且同步也修复了。
4.10 如何干净地清除slave同步信息
比如,在某些应用场景,我们要下线一台slave从机,一般会执行reset slave来清除show slave status\G里面的同步信息,但当你再次执行时,发现并不是我们想要的结果,如下所示:
MySQL> stop slave; Query OK, 0 rows affected (0.19 sec) MySQL> reset slave; Query OK, 0 rows affected (0.17 sec) MySQL> show slave status\G; *************************** 1. row *************************** slave IO State: master Host:192.168.8.22 master User: repl master Port:3306 Connect Retry:10 master Log File: Read master Log Pos:4 Relay Log File: vm02-relay-bin.000001 Relay Log Pos:4 Relay master Log File: slave IO Running: No slave SQL Running: No Replicate Do DB: Replicate Ignore DB: Replicate Do Table: Replicate Ignore Table: Replicate Wild Do Table: Replicate Wild Ignore Table: Last Errno:0 Last Error: Skip Counter:0 Exec master Log Pos:0 Relay Log Space:126 Until Condition: None Until Log File: Until Log Pos:0 master SSL Allowed: No master SSL CA File: master SSL CA Path: master SSL Cert: master SSL Cipher: master SSL Key: Seconds Behind master: NULL master SSL Verify Server Cert: No Last IO Errno:0 Last IO Error: Last SQL Errno:0 Last SQL Error: Replicate Ignore Server Ids: master Server Id:22 1 row in set (0.02 sec) ERROR: No query specified
执行reset slave,其实是把master.info和relay-log.info文件给删除,但里面的同步信息还在,如果此时有人误开启了start slave,结果就会又开始从头同步了,有可能还会造成数据丢失。那么可以用下面这个方法,让其清除得更为彻底。
MySQL> reset slave all; Query OK, 0 rows affected (0.04 sec) MySQL> show slave status\G; Empty set (0.02 sec) ERROR: No query specified
注意
此语句支持在MySQL5.5.20或更高版本。
来源:MySQL管理之道(第二版) 作者:贺春旸

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

