一、定时器
JMeter常被定义成性能测试工具或是自动化测试工具,都没错,它就是测试工具,关键看你怎么使用它;
后起之秀JMeter与革命前辈Loadrunner比较,timer可以根据实际场景设置思考时间用于等待或是集合点同时并发;
言归正传,我们来看看Jmeter的timer成员有哪些,具体作用是什么?
定时器的作用域
1、定时器是在每个sampler(采样器)之前执行的,而不是之后(无论定时器位置在sampler之前还是下面);
2、当执行一个sampler之前时,所有当前作用域内的定时器都会被执行;
3、如果希望定时器仅应用于其中一个sampler,则把定时器作为子节点加入;
4、如果希望在sampler执行完之后再等待,则可以使用Test Action;
1、Constant Timer 等待时间(思考时间)
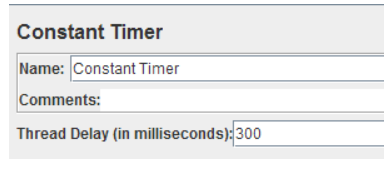
Name:恒定时间元件名称(可以理解是等待(思考)时间),
Comments:注释,随意;
Thread Delay(in milliseconds):线程等待时间,单位毫秒;
tips:用法(场景),更真实的模拟用户场景,需要设置等待时间,或是等待上一个请求的时间,才执行,给sampler之间的思考时间;
2、Synchronizing Timer 集合时间(集合点)
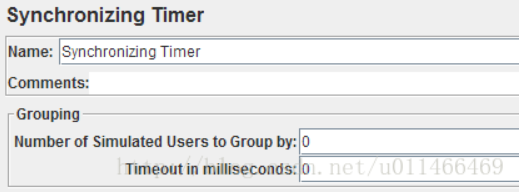
Name:Synchronizing Timer 同步定时器名称(集合点)
Comments:注释,可以让定时器变得有意思,一目了然;
Grouping
Number of Simulated Users to Group by: 同组用户数量,设置为0,等效于线程组中的线程数(Number of Threads(users));
Timeout in milliseconds:超时时间,单位毫秒,默认为0;如果设置为0,定时器等待同组的用户数,如果设置大于0,将以等待的最大线程数运行;
如果超时,等待的用户数没有到达,定时器将停止等待;如果超时了,设置并发的用户数大于线程数,那么脚本无法停止;
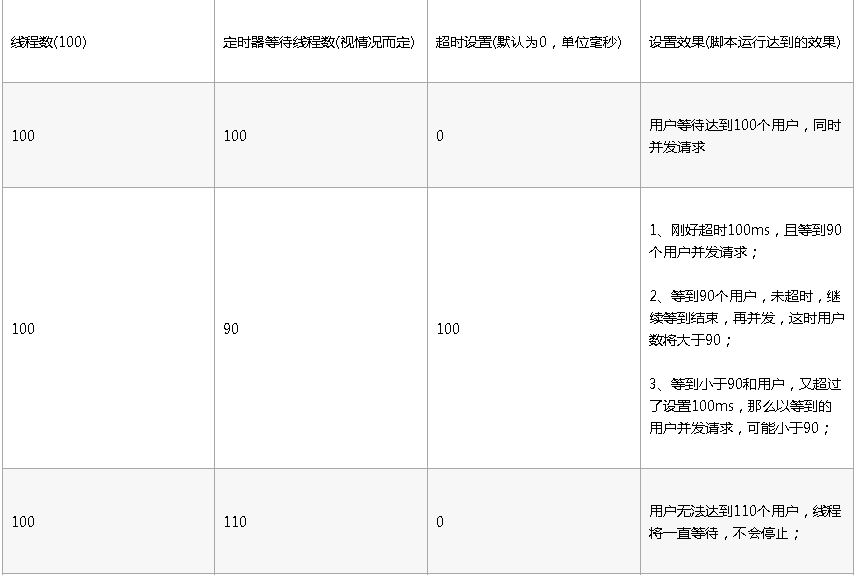
tips:线程组用户数100,添加同步定时器,

插入一个重点定时器:BeanShell Timer
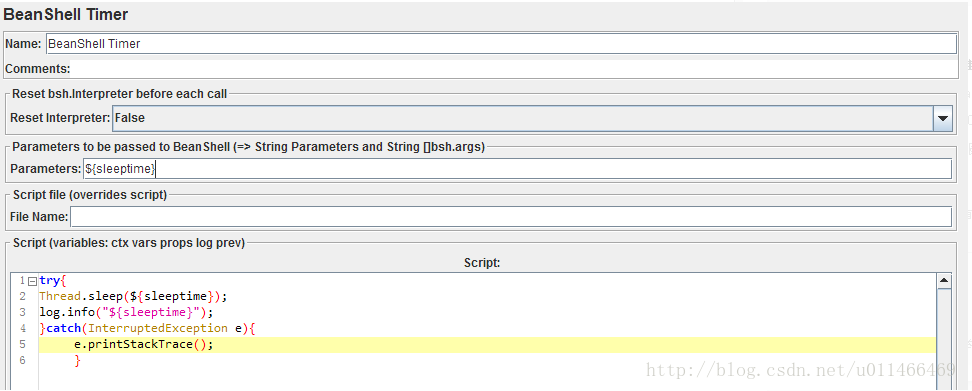
Name:名称,随意;
Comments:注释,随意.
Reset Interpreter:是否每次迭代重置解析器,默认false,官方建议长时间运行的脚本中设置True;
Parameters:BeanShell的入参;入参可以是单个变量,也可以是数组;
File Name:BeanShell 脚本可以从脚本文件中读取;
Script (Variables:ctx vars props log prev):编写的脚本(。。。),
如:
try{
Thread.sleep(${sleeptime});
log.error("${sleeptime}");
log.warn(ctx.getThreadNum().toString());
vars.put("company","www.baidu.com");
log.info(vars.get("company"));
log.warn(props.get("log_level.jmeter"));
props.put("log_level.jmeter","ERROR");
log.warn(props.get("log_level.jmeter"));
}catch(InterruptedException e){
e.printStackTrace();
}
tips:解释一下脚本中调用JMeter的运行属性:
Log,直接调用log类,如log.error()写日志,info,warn等等
Ctx,可以获取JmeterContent实例获取运行时信息;如获取线程号log.info(ctx.getThreadNum().toString());
Vars,访问变量获取对应的值,也可以设置变量;如vars.put("company","www.baidu.com");
comany可以直接被其他元件调用${company}
Props,直接访问及修改Jmeter的属性,如log.warn(props.get("log_level.jmeter"));
改变日至级别props.put("log_level.jmeter","ERROR");
Prev,访问前面sampler的结果.
3、Gaussian Random Timer 高斯定时器
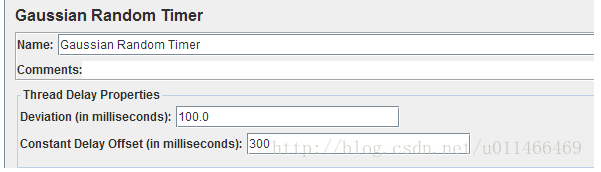
这三类定时器,个人理解差不得太多,都有一个固定延迟时间,然后再给一个延迟偏差;
例如:Gaussian Random Timer 高斯定时器;
Name:定时器的名称,随意
Comments:注释,随意;
Tread Delay Properties:单位都是毫秒,固定延迟300ms,偏差100ms,意思是时间延迟300-400ms之间;
Deviation (in milliseconds):偏差值,是一个浮动范围;
Constant Delay offset (in milliseconds):固定延迟时间
4、Uniform Random Timer 暂停一个随机时间;
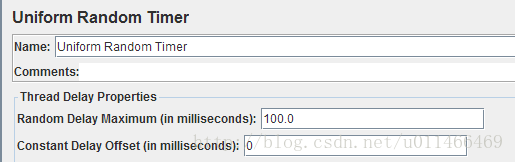
同上解读,只是偏差是随机,意思:0-100ms之间,可能是55ms
5、Poisson Random Timer 泊松定时器
6、 固定吞吐量定时器(Constant Throughput Timer)
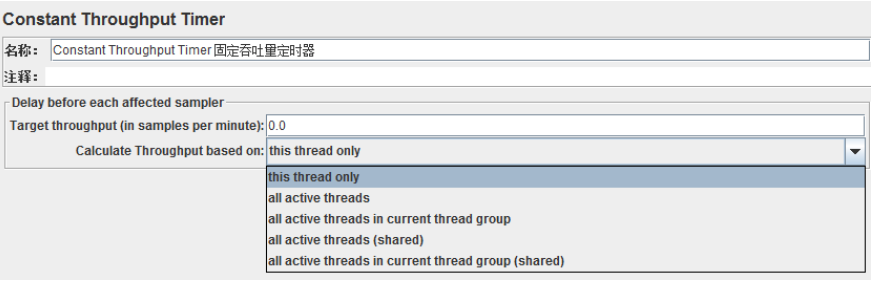
可以让JMeter以指定数字的吞吐量(即指定TPS,只是这里要求指定每分钟的执行数,而不是每秒)执行。
吞吐量计算的范围可以为指定为当前线程、当前线程组、所有线程组等范围,并且计算吞吐量的依据可以是最近一次线程的执行时延。
这种定时器在特定的场景下,还是很有用的。
7、JSR223定时器(JSR223 Timer)

在jemter最新的版本中,新增了这个定时器,可以这么理解,这个定时器相当于BeanShell定时器的“父集”,它可以使用java、JavaScript、beanshell等多种语言去实现你希望完成的事情;
我们都知道jemter是一种开源的纯java工具,可以自己构件各个组件,jar包去完成各种事情。
8、BSF定时器(BSF Timer)
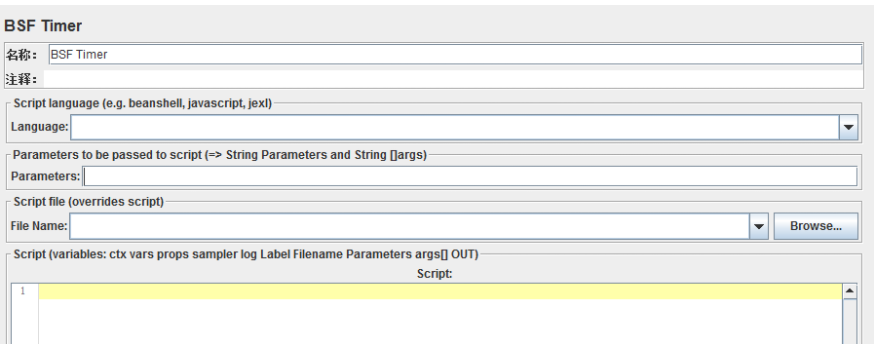
BSF Timer,也是jmeter新的版本中新增的定时器,其使用方法和JSR223 Timer很相似,只需要在jmeter的lib文件夹导入其jar包,就可以支持脚本语言直接访问Java对象和方法的一定时器。
二、 定时器(Synchronizing Timer)之集合点应用
性能测试中我们经常提到一个概念就是“并发”,其实在实际真实的性能测试中是不存在真正的并发的。为了更真实的模拟对一个请求的并发测试场景,我们通常设置一个集合点,JMeter中提供了这样的一个功能设置。
那么集合点的大致概念是什么呢?
简单理解就是:设置一个阀值(请求数量),当请求数达到这个阀值时,允许请求同时发出。例如:想测试一座桥的并发(忽略载重等其他因素,只考虑通过),那么并发的请求就是类似于多少辆车可同时通过桥,而车辆一般情况下是不可能同时通过桥的,因而我们可以在桥头A,设置一个集合点,等车辆数满足一定的数量,同时让车辆通过此桥。
添加路径:右键单击线程组,依次选择【添加/定时器/Synchronizing Timer】即可添加集合点

添加后,显示如下图所示:
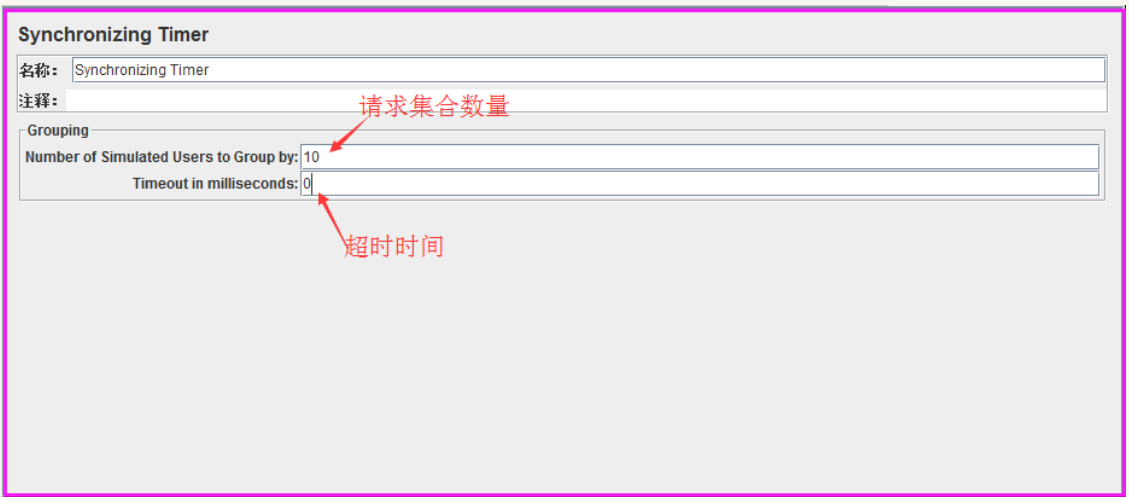
PS:超时时间为0时,默认无超时限制。
实际运行过程中,可能出现请求数当不满足集合点设置的请求数时,JMeter一直卡顿在如下页面:
解决办法是:设置同步定时器的超时时间。
同步定时器(Synchronizing Timer)的超时时间设置要求:
超时时间 > 请求集合数量 * 1000 / (线程数 / 线程加载时间)
三、 前置处理器
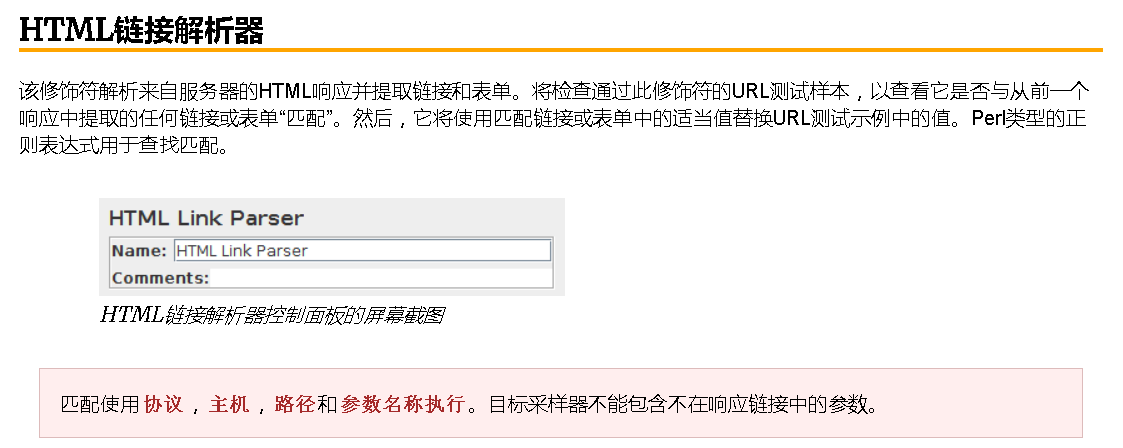
1、HTML链接解析器
2、HTTP URL重写修饰符
该修饰符的工作方式与HTML链接解析器类似,只是它具有比HTML链接解析器更易于使用的特定目的,并且效率更高。对于使用URL重写来存储会话ID而不是Cookie的Web应用程序,该元素可以连接到ThreadGroup级别,与HTTP Cookie管理器非常相似。简单地给它一个会话id参数的名称,它会在页面上找到它,并将该参数添加到该ThreadGroup的每个请求中。
另外,这个修饰符可以附加到选择请求,它只会修改它们。聪明的用户甚至会确定这个修饰符可以用来获取躲避 HTML链接解析器的值。

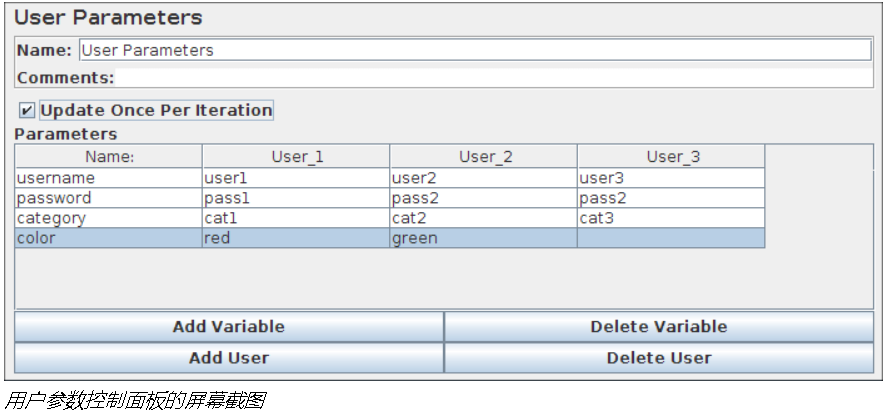
3、用户参数
允许用户为特定于各个线程的用户变量指定值。
用户变量也可以在测试计划中指定,但不针对单个线程。此面板允许您为任何用户变量指定一系列值。对于每个线程,将按顺序为该变量分配一个值。如果线程数多于值,则会重新使用这些值。例如,这可以用于分配每个线程要使用的不同用户标识。用户变量可以在任何JMeter组件的任何字段中引用。
通过单击面板底部的添加变量按钮并填写“ 名称: ”列中的变量名称来指定该变量。要为系列添加新值,请点击“ 添加用户”按钮并在新添加的列中填写所需的值。
可以使用函数语法在同一个线程组中的任何测试组件中访问值:$ {variable}。
另请参阅CSV数据集配置元素,它更适合大量的参数

4、BeanShell预处理器
BeanShell PreProcessor允许在采样前应用任意代码。
有关使用BeanShell的完整详细信息,请参阅BeanShell网站。
测试元素支持ThreadListener和TestListener方法。这些应该在初始化文件中定义。有关示例定义,请参阅BeanShellListeners.bshrc文件。



JSR223预处理器
在进行示例之前,JSR223预处理器允许应用JSR223脚本代码。


JDBC预处理器
JDBC PreProcessor使您能够在样本运行之前运行一些SQL语句。如果您的JDBC Sample需要某些数据在DataBase中,并且您无法在设置线程组中计算此值,那么这会很有用。有关详细信息,请参阅JDBC请求
请参阅以下测试计划:

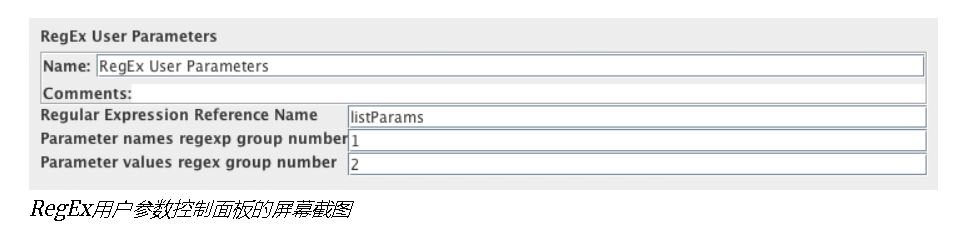
RegEx用户参数
允许使用正则表达式为从另一个HTTP请求提取的HTTP参数指定动态值。RegEx用户参数特定于单个线程。
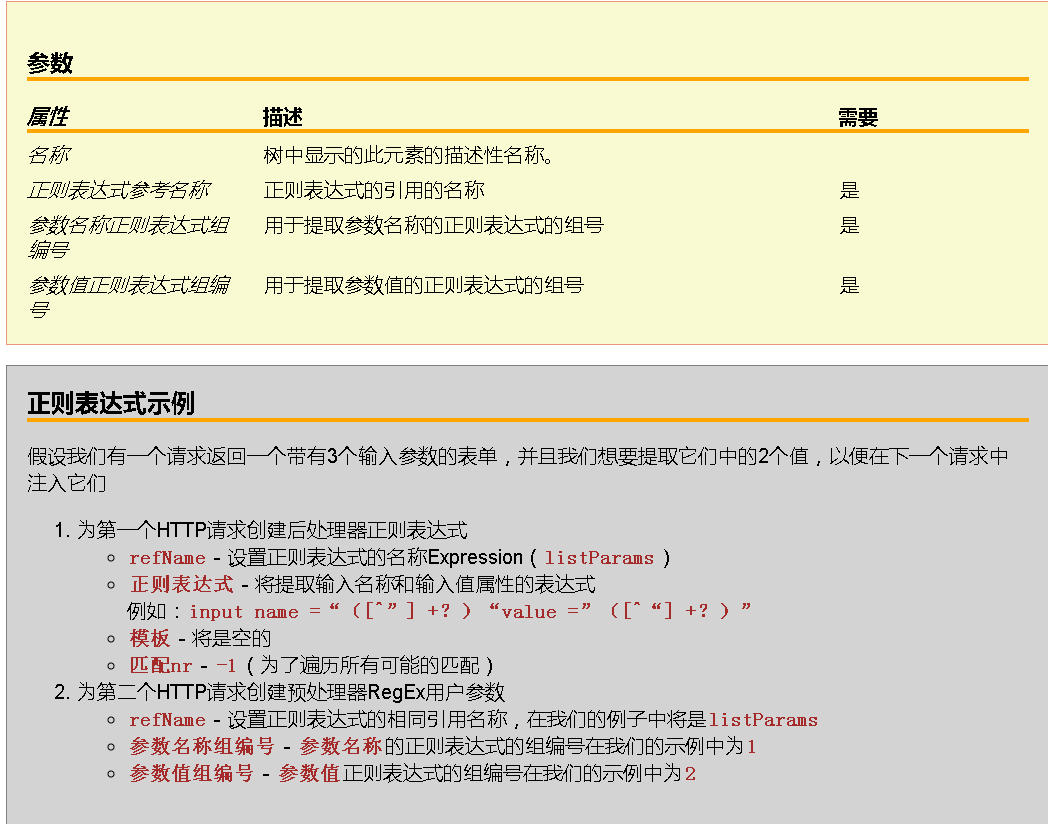
此组件允许您指定提取HTTP请求参数的名称和值的正则表达式的引用名称。必须为参数名称和参数值指定正则表达式组号。只有使用此名称匹配的RegEx用户参数的采样器中的参数才会进行替换。
采样超时
如果预处理器花费很长时间才能完成,则该预处理器会计划一个计时器任务以中断样本。如果超时值为零或负值,则超时值将被忽略。为此,采样器必须实现可中断。已知下列采样器可以这样做:
AJP,BeanShell,FTP,HTTP,Soap,AccessLog,MailReader,JMS订户,TCPSampler,TestAction,JavaSampler
测试元素适用于连接超时或响应超时等个别超时不足或者采样器不支持超时的情况。超时时间应该设置得足够长,以便在正常测试中不会触发,但足够短以至于会中断卡住的样本。
[默认情况下,JMeter使用Callable来中断采样器。这与定时器在同一个线程中执行,所以如果中断需要很长时间,它可能会延迟处理后续超时。这不会成为问题,但如果必要, 可以将InterruptTimer.useRunnable属性设置为true,以使用单独的Runnable线程而不是Callable。]

四、 后置处理器
后置处理器实例之 - 正则表达式提取器(一)概述及简单实例
那么我们如何获取 HTTP请求 响应结果中的数据呢?此文以获取类目 手机数码-手机通讯-苹果 结果列表中的第一个商品的系统编号为例演示(脚本基于上篇文章,请知悉)。
如下为请求响应数据中的部分数据,我们最终要获取的数据为 "sysNo": "2142717" 中的 2142717。

那么我们如何获取呢? JMeter 提供的后置处理器中提供了响应的获取方法,例如:正则表达式提取器、BeanShell PostProcessor、BSF PostProcessor 等。当下以 正则表达式提取器为例演示讲解,对应的添加路径为:【添加/后置处理器/正则表达式提取器】,添加后目录结果如下:

对应添加的正则表达式提取器如下所示:
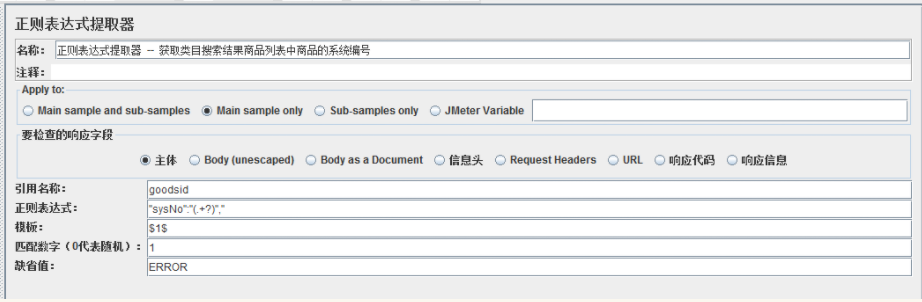
正则表达式提取器说明:
Apply to:应用范围
要检查的响应字段:样本数据源。
引用名称:其他地方引用时的变量名称,引用方法:${引用名称}
正则表达式:数据提取器,如上图的 "sysNo":"(.+?)"," 其中 (.+?) :为非贪婪匹配,建议均使用非贪婪匹配,除非特殊情况。不熟悉正则的,劳烦联系度娘或者谷大爷,谢谢!
模板:对应正则表达式提取器类型,样式为:1。若为:0,则为所有的匹配数据,例如:"sysNo":"123453463"," 其中 123453463 为 (.+?) 匹配的数据,即最终提取的目标部分。若模板为:1,则 1 对应正则表达式中的 (.+?)
匹配数字:正则表达式匹配数据的最终结果可以看做一个数组,匹配数字即可看做是数组的第几个元素。当为 0 时,随机返回匹配的数据,当为 1 时,表示返回匹配结果数组的第一个元素。
缺省值:匹配失败时的默认值。通常用于后续的逻辑判断,一般通常为特定含义的英文大写单词组合,简单可写为 ERROR。
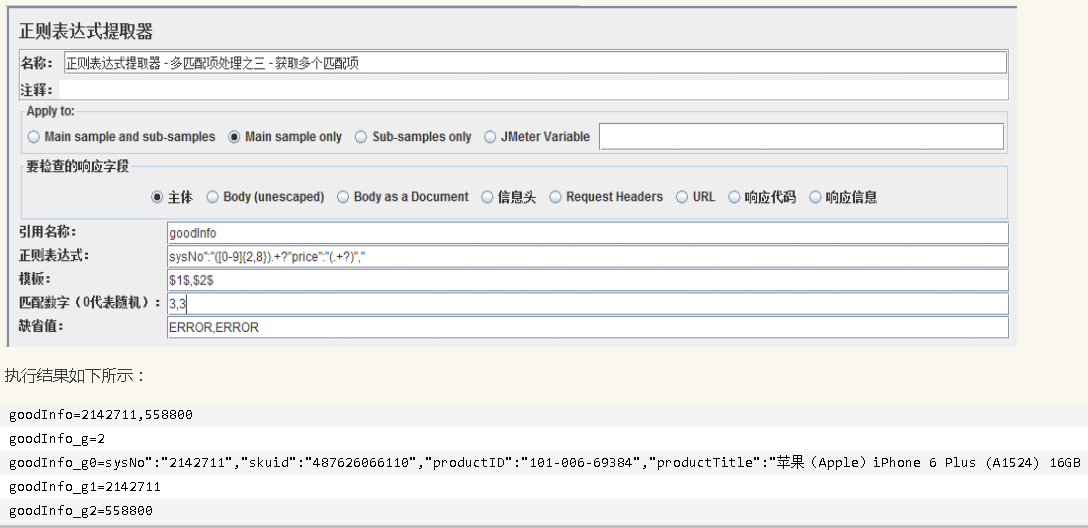
执行结果如下所示:
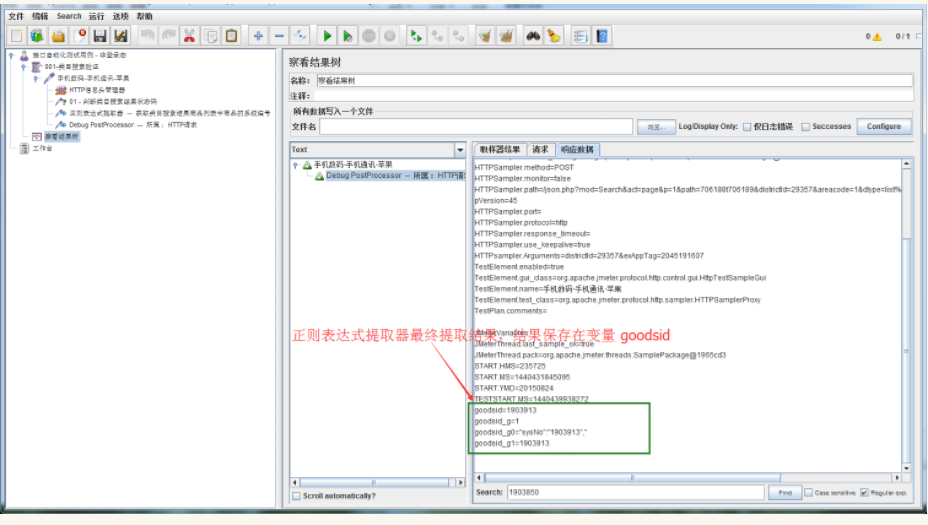
此文主要对正则表达式提取器的 正则表达式、模板、匹配数字,三者的关系,做进一步的讲解。
截取商品列表响应结果数据中的一段商品数据如下所示:

参照上述商品信息数据,假定我们需要获取的是商品的系统编号、商品价格,那么我们改如何写呢?对应上述信息获取商品系统编号、商品销售价格,最终的正则表达式如下所示:
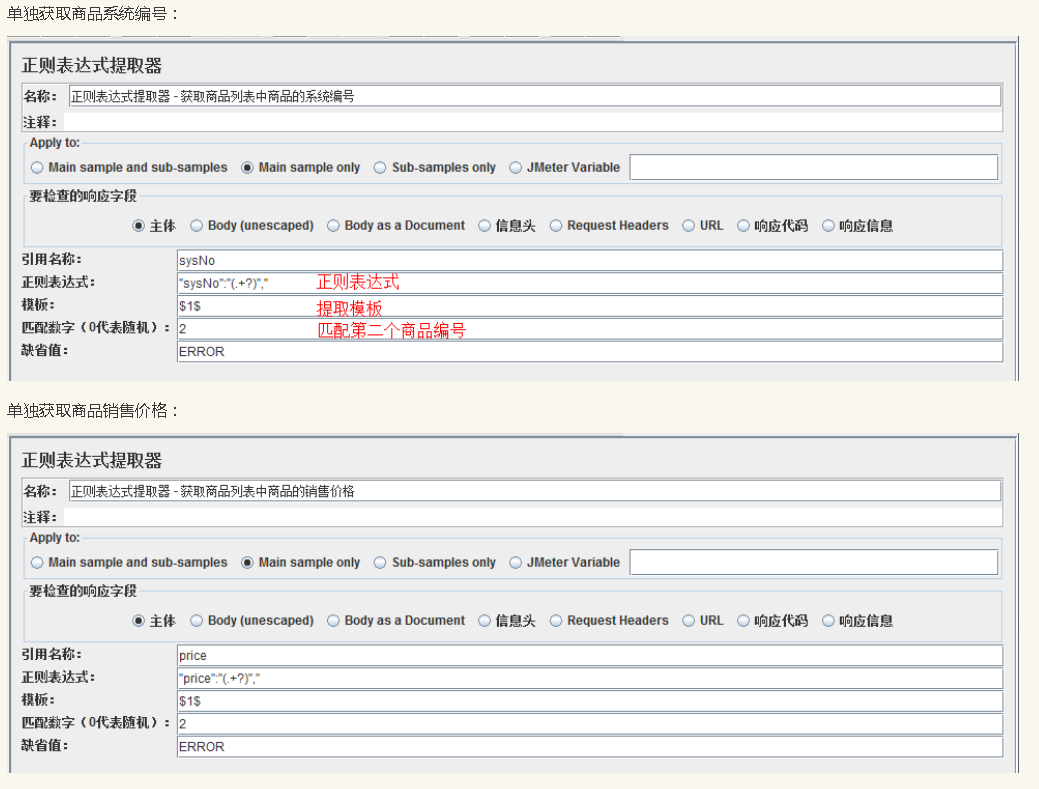

在前文的讲述中,正则表达式提取器的模板是匹配正则表达式提取式的控制模板。例如:模板 1 中的数字 1 代表取第一个正则提取式的内容,当为0时,为整个正则表达式完整匹配项。那么我们就可以通过模板控制我们选取的提取式,以获取相应的内容,进行相应的后续操作。通过模板控制,单独获取商品系统编号、销售价格的正则表达式提取配置如下所示:
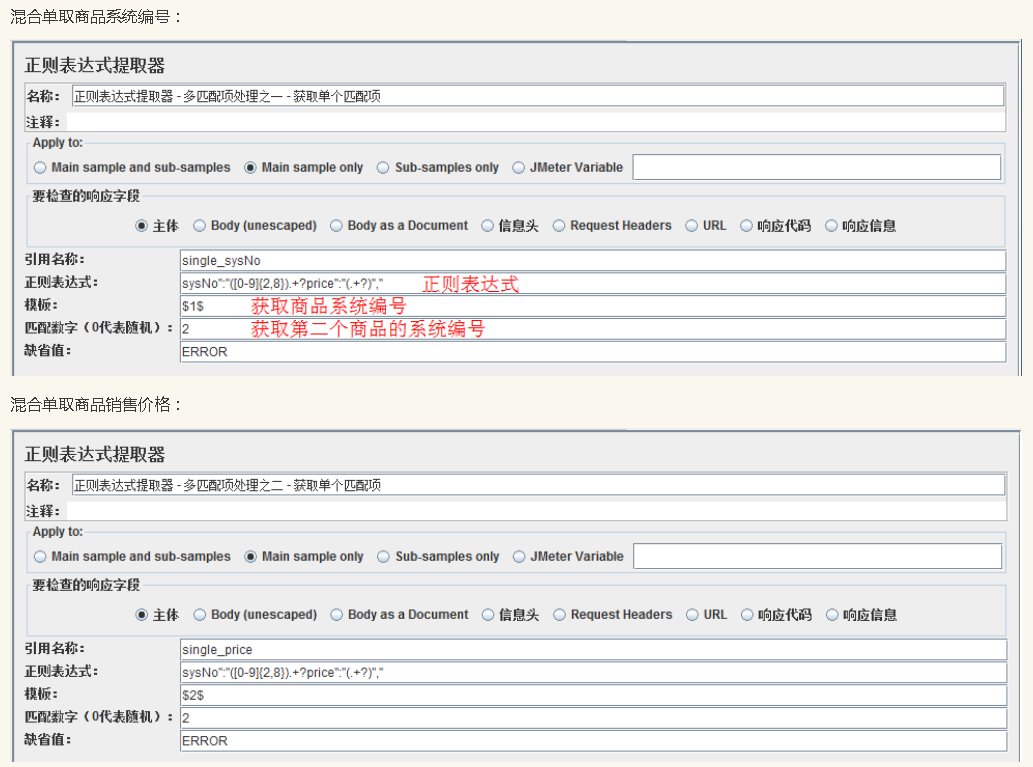

经过上述的讲解及演示,细心的小主可能已经发现了,在提取相关联的数据时,通过单独提取的方式非常的不方便,而且在数量多的时候,难免出现配置数据不对应的情况,造成所取的关联数据并非关联数据。那么针对此种情况,我们改如何处理呢?通过 上篇文章 及本文前面的讲解,我们知道,既然可以通过模板控制提取内容的选取,那是否可将相关联的需提取的内容同时在一个正则表达式提取器中完成呢?答案是可以的,仅需在引用名称、模板、匹配数字、缺省值 进行相应的配置即可,同时以英文半角字符 “,” 分隔即可。下面就以同时获取系统编号和销售价格为例进行演示:
正则提取器配置如下所示:
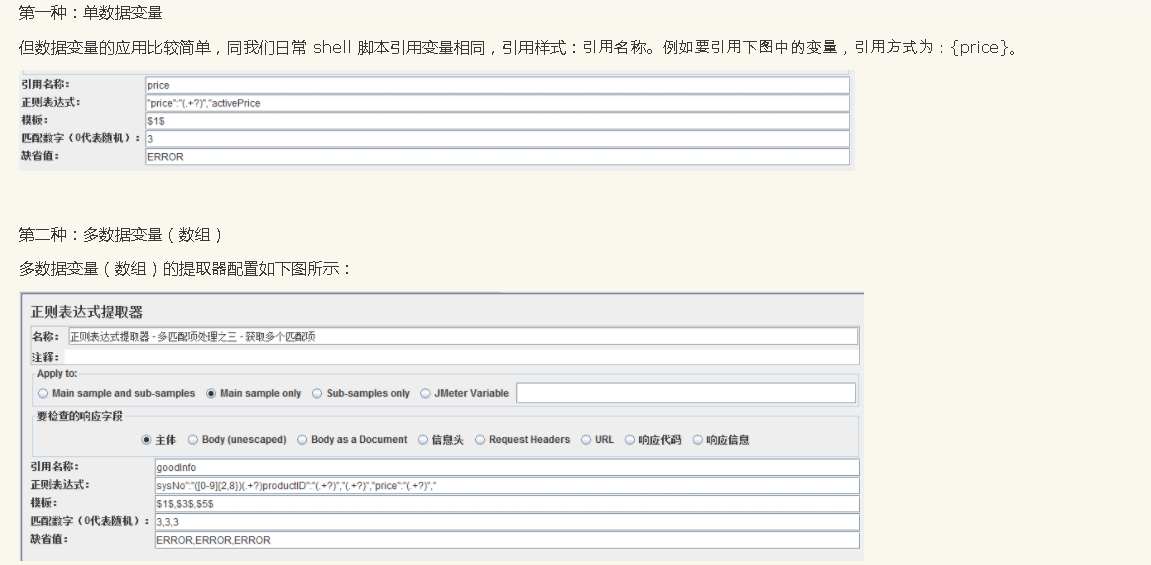
此文主要讲述如何引用正则表达式提取器获取的数据信息。其实,正则表达式提取器获取的数据,均可看做一个变量(单个数据,此处指所需获取的测试相关数据)或数组(多个数据),通过引用变量或者数组的数据,达到应用其数据的目的。下面针对此两种方式进行介绍。
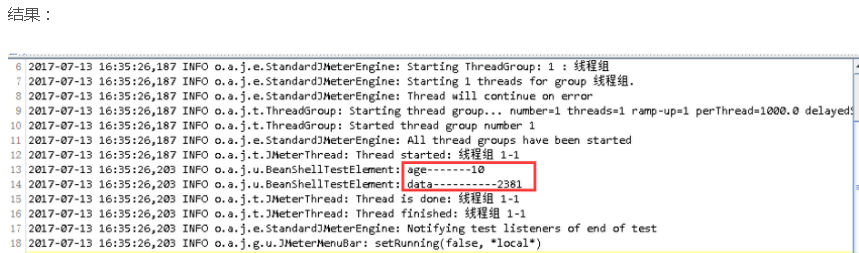
1. BeanShell PostProcessor
语法与BeanShell Sampler一样,但注意可用的变量有不同的

2. JDBC PostProcessor
在请求运行之后进行数据库操作。
使用方法与JDBC Request 是一样的。
应用场景,比如在创建用户,需要知道保存在数据库中的用户信息,可以使用JDBC PreProcessor进行查询

3. JSON Extractor
json 提取器,使用JSON-PATH语法,具体察看:
http://goessner.net/articles/JsonPath/
注意只有响应数据为json时适用
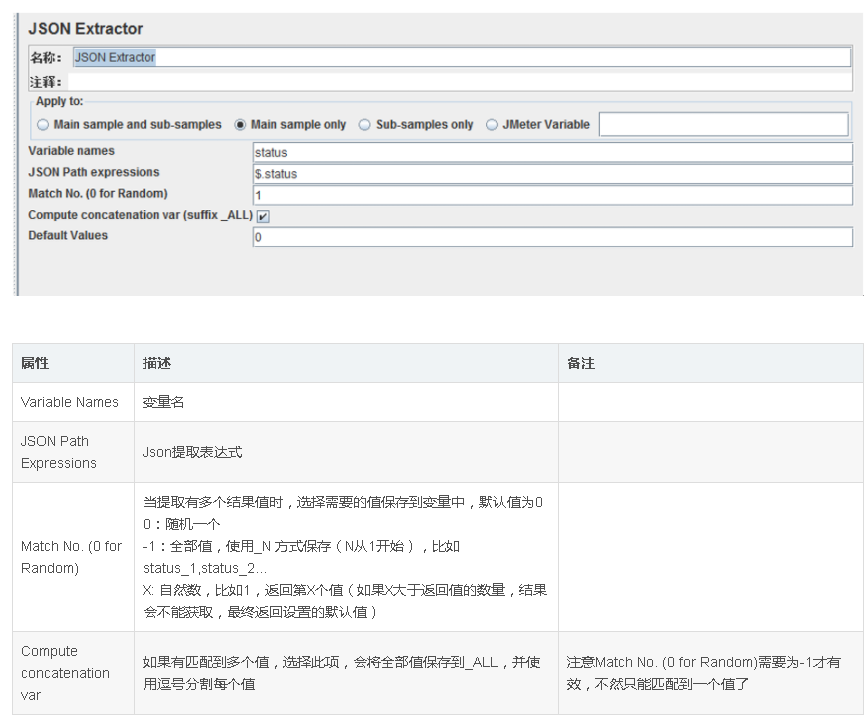
比如一个获取用户信息请求,请求失败返回为json,需要提取status值
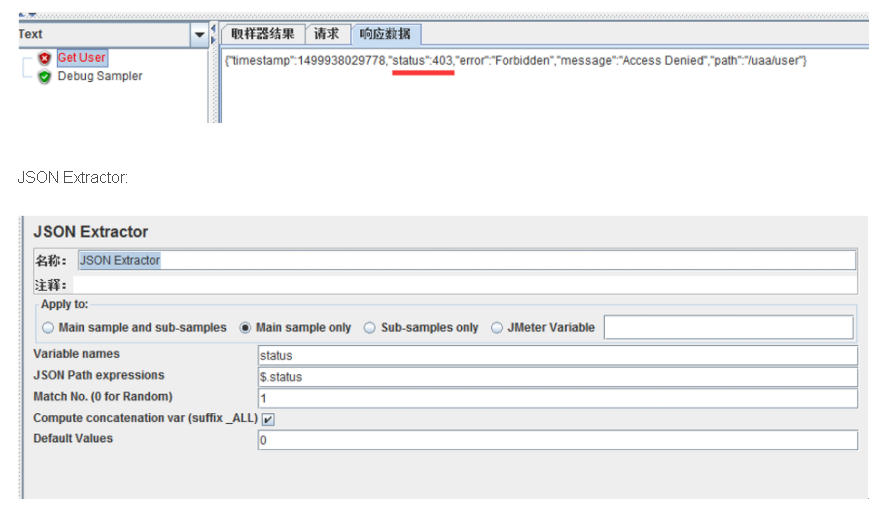
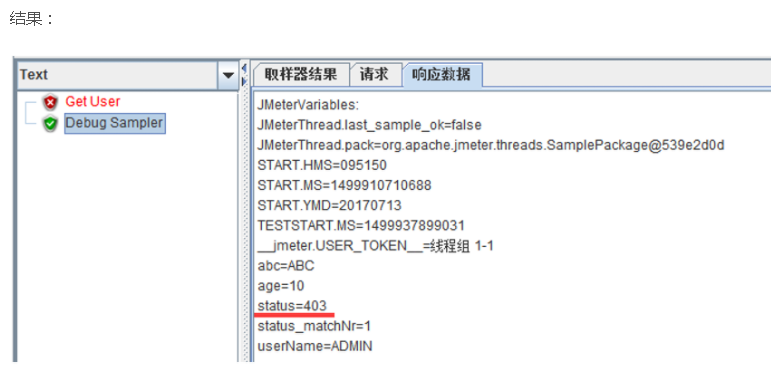
来源:
https://blog.csdn.net/tomoya_chen/article/details/78194110
https://blog.csdn.net/kdslkd/article/details/77719379
https://blog.csdn.net/u011466469/article/details/78322513
https://www.cnblogs.com/fengpingfan/p/5583594.html
https://www.cnblogs.com/imyalost/p/6004678.html
http://jmeter.apache.org/usermanual/component_reference.html#Regular_Expression_Extractor

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


