一、数据预处理
StandardScaler作用:去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本。StandardScaler对每列分别标准化。
去均值:各维度都减对应维度的均值。
去均值举例
X数据中年龄字段的值为(6,7,8) :求出均值(6+7+8)/3 = 7 ------->X(7-6,7-7,8-7)----->X(1,0,-1)
归一化: 把数变为(0,1)之间的小数,,更加便捷快速的处理。
归一化举例
例1:{3,4,5 }归一化后变成了{0.25,0.33 ,0.42}
解:3+4+5 = 12
3/12 = 0.25
4/12 = 0.33
5/12 = 0.42
标准化(standardScale):
使得新的X数据集方差为1,均值为0。
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
from sklearn.preprocessing import StandardScaler
X = [[0, 15],
[1, -10]]
StandardScaler().fit(X).transform(X)
# 使得新的X数据集方差为1,均值为0。
# array([[-1., 1.],
# [ 1., -1.]])
方差是各个数据与平均数之差的平方的和的平均数,公式为:
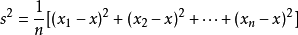
其中,x表示样本的平均数,n表示样本的数量,xi表示个体,而s^2就表示方差。
平方差:a²-b²=(a+b)(a-b)。文字表达式:两个数的和与这两个数的差的积等于这两个数的平方差。此即平方差公式
标准差:标准差=sqrt(((x1-x)^2 +(x2-x)^2 +......(xn-x)^2)/n)。是离均差平方的算术平均数的平方根,用σ表示。在概率统计中最常使用作为统计分布程度上的测量。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。
二、管道
管道机制是按照封装顺序依次执行的一种机制,在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。
管道构建流程
在Pipeline中的步骤为:
第一步,特征标准化(StandardScaler)
第二步,分类器(Classifier),也是最后一步
中间可加上比如数据降维(PCA)等步骤
完成管道部署后:
a.用 Pipeline.fit对训练集进行训练: pipe_lr.fit(X_train, y_train)
b.再直接用 Pipeline.score 对测试集进行预测并评分: pipe_lr.score(X_test, y_test)
在以下示例中,我们加载Iris数据集,将其分为训练集和测试集,然后根据测试数据计算管道的准确性得分
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 创建一个管道对象
pipe = make_pipeline(
StandardScaler(),
LogisticRegression(random_state=0) #分类函数名字叫逻辑回归
)
# 加载虹膜数据集并将其分为训练集和测试集
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 通过管道拟合数据
pipe.fit(X_train, y_train)
#计算分类准确率的得分
accuracy_score(pipe.predict(X_test), y_test)
回归:就是X 数据和 y 数据之间的关系.
线性回归:X 数据和 y 数据之间的关系是一条直线叫做线性回归。用来做预测
逻辑回归 : X 数据和 y 数据之间的关系 非直线,用来做分类。
这里不做详细的线性回归,逻辑回归公式原理的具体解释略。
逻辑回归与线性回归的关系
作者:mantch
逻辑回归是用来做分类算法的,大家都熟悉线性回归,一般形式是Y=aX+b,y的取值范围是[-∞, +∞],有这么多取值,怎么进行分类呢?不用担心,伟大的数学家已经为我们找到了一个方法。
首先我们先来看一个函数,这个函数叫做Sigmoid函数:
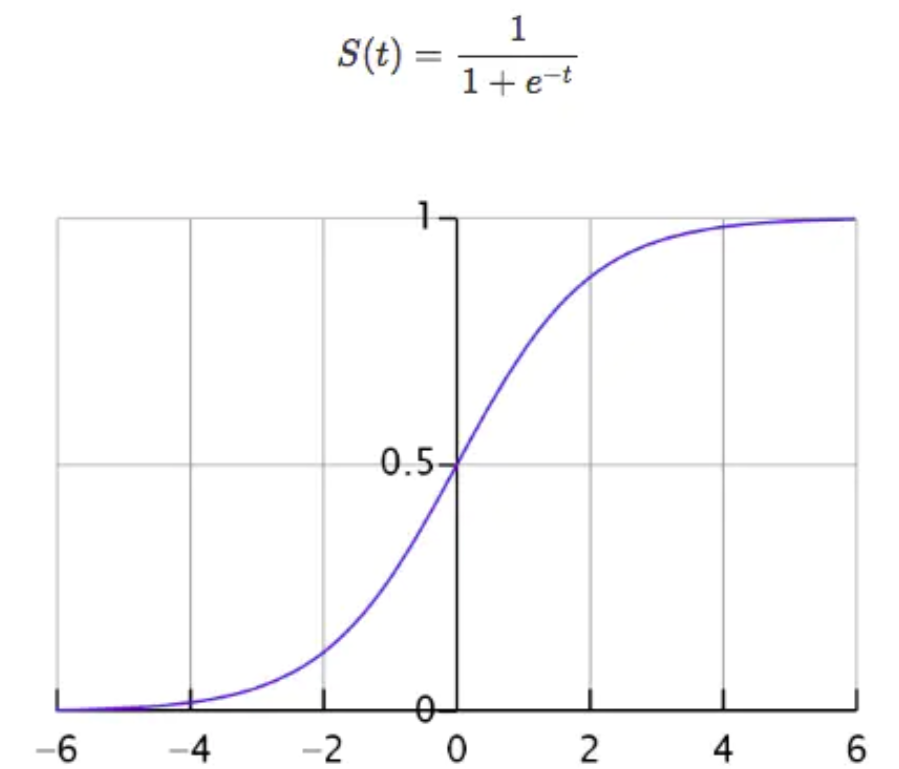 。
。函数中t无论取什么值,其结果都在[0,-1]的区间内,回想一下,一个分类问题就有两种答案,一种是“是”,一种是“否”,那0对应着“否”,1对应着“是”,那又有人问了,你这不是[0,1]的区间吗,怎么会只有0和1呢?这个问题问得好,我们假设分类的阈值是0.5,那么超过0.5的归为1分类,低于0.5的归为0分类,阈值是可以自己设定的。
好了,接下来我们把aX+b带入t中就得到了我们的逻辑回归的一般模型方程:
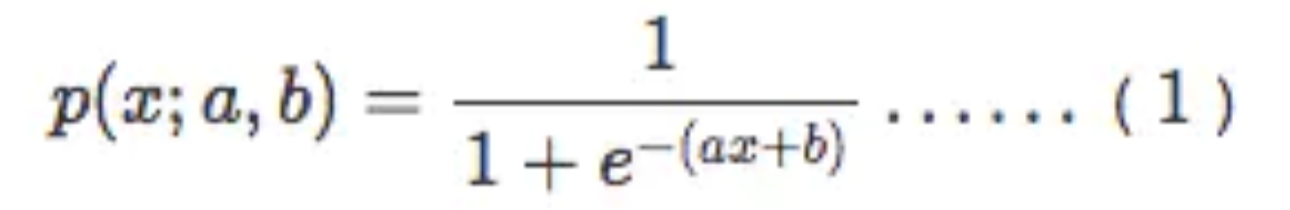
结果P也可以理解为概率,换句话说概率大于0.5的属于1分类,概率小于0.5的属于0分类,这就达到了分类的目的

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~





