1、import介绍
它是用来导入工具包提供给我们可以快速构建我们的程序的功能函数。
> Correct:
import os
import sys
> Correct:
from subprocess import Popen, PIPE导入应按以下顺序分组:
- 标准库导入。
- 相关第三方。
- 本地应用程序/库特定的导入,您应该在每组导入之间放置一个白行。
- 推荐绝对导入
import mypkg.sibling
from mypkg import sibling
from mypkg.sibling import example5、相对导入(不推荐)python3 中已经废除
from . import sibling
from .sibling import example2、导入模块的正确姿势
模块只是扩展名为.py 的文件,模块的名称就是文件的名称。模块当中可以有很多函数或类。
当我们创建模块名的时候,尽量要言简意赅。
不要这样:import create_women_object
应该这样:import girlfriend 或者from users import girlfriend不要这样: import users.women.girlfriend、import USERS
应该这样: import users_girlfriend、import users避免使用在文件名中使用点和特殊字符,导入代码的可读性也至关重要,毕竟万事开头难。开头的阅读新也至关重要。
不要这样:from user import *
friend = get_girlFriend()
应该这样:from user import get_girlFriend
friend = get_girlFriend()
最好是这样:import user
user.get_girlFriend() # 可以明确标记get_girlFriend() 哪个模块下的。
当巧合出现: from user import get_girlFriend
from person import get_girlFriend
friend1 = get_girlFriend() # 就会发生冲突
friend2 = get_girlFriend() # 就会发生冲突
冲突:如果两个包里有同名模块,或者两个模块里有同名的函数或类,那么后引入的那个会把先引入的覆盖掉。
解决冲突使用as起别名: from user import get_girlFriend as u_gf
from person import get_girlFriend as p_gf
as 不仅可以给函数换名字,防止冲突,还能给整个模块换个名称,例如:import pandas as pd
这是数据分析核心模块的pandas 的常规引入写法。如果pandas 还没有掌握,赶紧去查看同乐老师的[python自动化办公的10、11、16章的内容](https://edu.51cto.com/course/21337.html "python自动化办公的10、11、16章的内容")。
3、init.py 是干啥的、包干哈的?
自从Python3.3之后,不需要在目录中包含init.py文件来表明这个目录是一个Python 包。
3.3之前是需要的,Pycharm 在建立package的时候会默认新建一个,这个init尽管新版本不需要它来表示我是一个包了,但是它还有许多妙用。最好是不要删除,以便引起不必要的麻烦和异常。
包的含义简单解释:是用来管理模块的,就是一个文件夹下面可以创建很多模块。
来源于Python官方社区
包是一种用“点式模块名”构造 Python 模块命名空间的方法。例如,模块名 A.B 表示包 A 中名为 B 的子模块。导入包时,Python 搜索 sys.path 里的目录,查找包的子目录。
Python 只把含 init.py 文件的目录当成包。这样可以防止以 string 等通用名称命名的目录,无意中屏蔽出现在后方模块搜索路径中的有效模块。 最简情况下,init.py 只是一个空文件,但该文件也可以执行包的初始化代码,或设置 all 变量。
购物车模块:
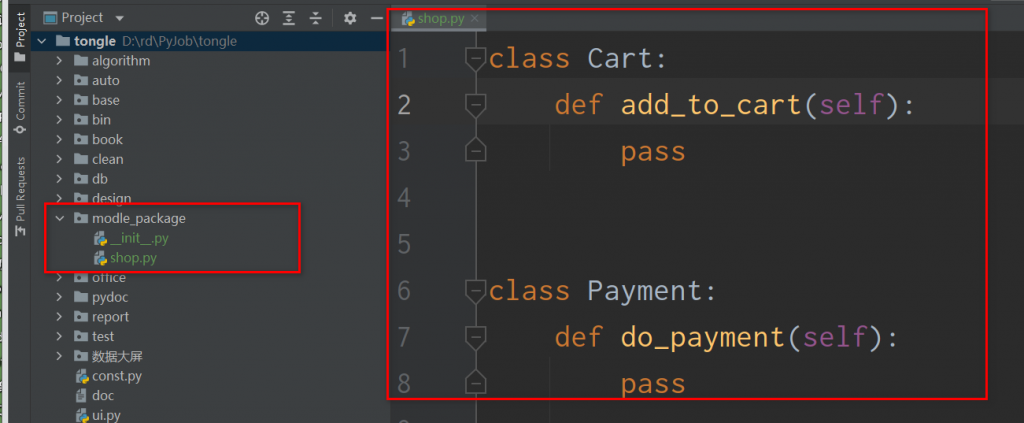
利用init对购物车模块进行拆解
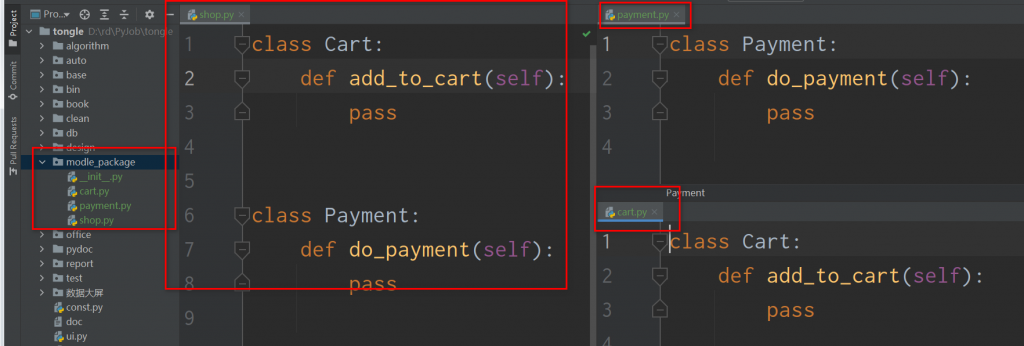
模块拆解的好处,就是好维护,功能单一职责,每个模块负责对应相关的功能职责。
利用init对拆解的模块逻辑式黏连在一起
但是我们再把拆开的模块,逻辑式的黏连在一起对外提供使用,就可以利用init.py

我们在modle_package包下的init.py文件中以from 的形式进行黏连在一起,以modle_package 作为对外服务的公共接口。来达到分久必合的原理。这种方式会让你用一个模块来处理项目的不同功能,这在大型项目和第三方库中特别有用。但是会给客户端要弄清楚这个功能函数在哪一个模块下,带来了一些负担,特别是喜欢用相对导入的小伙伴,利与弊自己权衡,我还是那句话,适合自己的才是最好的,PE8也不是都适合我们。
PE8代码规范:标准库代码应避免复杂的包布局并始终使用绝对导入。
在__init__文件中使用
from . import echo
from .. import formats
from ..filters import equalizer
# 这种叫做相对导入,大多数情况下不建议这么做,这么做得唯一好处就是,可以省略冗长的导入,以及避免外部包的结构或者包名而改动。**
4、通过包构建稳定的API,使用all关键字
API 就是你写好的功能函数,以开源软件包的形式,提供给别人使用。以免新旧版本差异过大,你就得把他的功能稳定下来,为了做到这一点,就得隐藏软件包内的代码结构。不要让外部开发者依赖这套结构,
Python 允许我们通过all这个特殊属性,决定模块或包里面有哪些内容应该当做API公布给外界。all的值是一份列表,一般from foo import * 与 all 才是最佳拍档。
下面案例把相互关联的模块,以API方式共享:
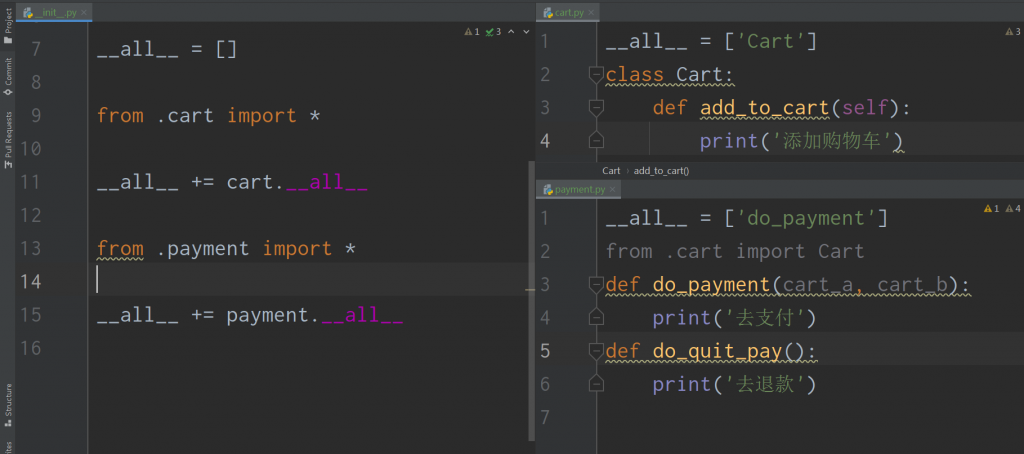
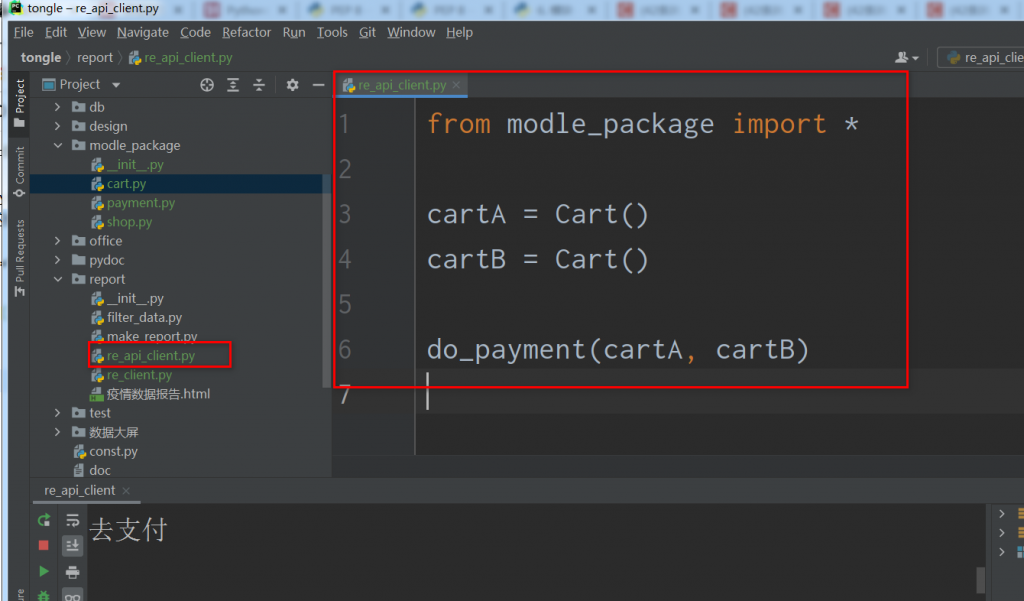
这种做法,可以很好的帮助我们打造明确而稳固的api.如果说你不对外提供,其实没有必要这么麻烦。
并且 from model_package import * 在内部用时,是禁止推荐使用的。
5、有用的扩展
有用扩展来源于python cookbook
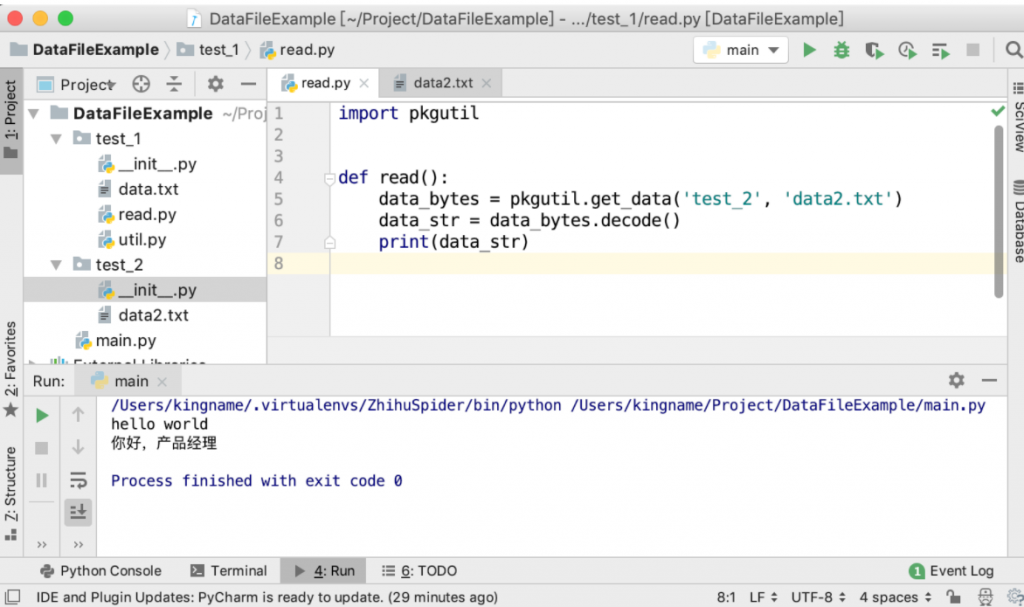
读取位于包中的数据文件
mypackage/
__init__.py
somedata.dat
spam.py现在假设spam.py文件需要读取somedata.dat文件中的内容。你可以用以下代码来完成:
# spam.py
import pkgutil
data = pkgutil.get_data(__package__, 'somedata.dat')pkgutil是Python自带的用于包管理相关操作的库,pkgutil能根据包名找到包里面的数据文件,然后读取为bytes型的数据。如果数据文件内容是字符串,那么直接decode()以后就是正文内容了。
为什么pkgutil读取的数据文件是bytes型的内容而不直接是字符串类型?
这是因为并不是所有数据文件都是字符串,如果某些数据文件是二进制文件或者图片,那么以字符串方式打开就会导致报错。所以为了通用,pkgutil会以bytes型方式读入数据,这相当于open函数的“rb”读取方式。使用pkgutil还有一个好处,就是只要知道包名就可以找到对应包下面的数据文件,数据文件并不一定要在当前包里面。!
下面案例截图来源于互联网:
https://www.cnblogs.com/du-jun/p/12192797.html
6、简单快捷导入多层级包下的某个模块
可以直接把多层级下某个模块,导入到系统环境变量,就像这样、
官方的解释
变量 sys.path 是字符串列表,用于确定解释器的模块搜索路径。该变量以环境变量 PYTHONPATH 提取的默认路径进行初始化,如未设置 PYTHONPATH,则使用内置的默认路径。可以用标准列表操作修改该变量:
import sys
sys.path.append('/ufs/guido/lib/python')
牛奶喝多了,有点醉了,深夜写写博客缓解一下,写了快一个多小时了,不写了,困了,睡觉!
明天继续更~

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


