前言
Day4的爬虫类感觉,写的好多重复代码 ,写的有点像java,经过利用scrapy的ItemLoader机制,终于代码有点像Python了!
其实编程语言,没有简洁之分,跟代码的设计模式有关,通过封装,代码的抽取来达到实际作用业务逻辑代码的简洁!
那些通过正则表达式,日期转换,MD5加密的业务处理逻辑方法的细节,让我封装在共用的类里进行重用来达到简洁的效果~
业务类
(由1百几十行,缩减到45行!如果去掉引入库包和换行,其实20几行就能爬取一个网站 )
import scrapy
import re
import datetime
from scrapy.http import Request
from urllib import parse
from BoleOnline.items import JobBoleArticleItem, ArticleItemLoader
from BoleOnline.utils.common import get_md5
from scrapy.loader import ItemLoader
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
# 获取 下一页面的url并交给scrapy进行下载
post_nodes = response.css("#archive .floated-thumb .post-thumb") # a selector, 可以在这个基础上继续做 selector
for post_node in post_nodes:
post_url = post_node.css("a::attr(href)").extract_first("")
img_url = post_node.css("a img::attr(src)").extract_first("")
yield Request(url=parse.urljoin(response.url, post_url),
meta={"front-image-url": img_url}, callback=self.parse_detail)
# 必须考虑到有前一页,当前页和下一页链接的影响,使用如下所示的方法
next_url = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_detail(self, response):
# 文章封面图
front_img_url = response.meta.get("front-image-url", "")
# 通过item loader 加载item
item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response)
item_loader.add_xpath("re_title", "//div[@class='entry-header']/h1/text()")
item_loader.add_value("url", response.url)
item_loader.add_value("url_object_id", get_md5(response.url))
item_loader.add_value("front_img_url", [front_img_url])
item_loader.add_xpath("re_create_date", "//p[@class='entry-meta-hide-on-mobile']/text()")
item_loader.add_xpath("re_dianGood_number", "//span[contains(@class,'vote-post-up')]/h10/text()")
item_loader.add_xpath("re_get_number", "//span[contains(@class,'bookmark-btn')]/text()")
item_loader.add_xpath("re_talk_number", "//a[contains(@href,'#article-comment')]/span/text()")
item_loader.add_xpath("tags", "//p[@class='entry-meta-hide-on-mobile']/a/text()")
item_loader.add_xpath("re_content", "//div[@class='entry']")
article_item = item_loader.load_item()
yield article_item
pass
控制类
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
import datetime
import re
from scrapy.loader.processors import MapCompose,TakeFirst, Join
from scrapy.loader import ItemLoader
from BoleOnline.utils.common import date_convert
from BoleOnline.utils.common import get_number
from BoleOnline.utils.common import remove_tags
from BoleOnline.utils.common import return_value
from BoleOnline.utils.common import add_jobbole
class BoleonlineItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#
pass
class ArticleItemLoader(ItemLoader):
# 自定义itmeloader
default_output_processor = TakeFirst()
class JobBoleArticleItem(scrapy.Item):
# 标题
re_title = scrapy.Field(
input_processor=MapCompose(add_jobbole)
)
# 文章创建日期
re_create_date = scrapy.Field(
input_processor=MapCompose(date_convert)
)
# 文章链接
url = scrapy.Field()
# 文章鏈接md5加密
url_object_id = scrapy.Field()
# 文章封面图链接
front_img_url = scrapy.Field(
output_processor=MapCompose(return_value)
)
# 封面图路径
front_img_path = scrapy.Field()
# 文章点赞数
re_dianGood_number = scrapy.Field(
input_processor=MapCompose(get_number)
)
# 文章收藏数
re_get_number = scrapy.Field(
input_processor=MapCompose(get_number)
)
# 文章评论数
re_talk_number = scrapy.Field(
input_processor=MapCompose(get_number)
)
# 文章主题标签
tags = scrapy.Field(
input_processor=MapCompose(remove_tags),
output_processor=Join(",")
)
# 文章内容
re_content = scrapy.Field()
pass
公用类
import hashlib
import re
import datetime
__author__ = 'zhangtongle'
def get_md5(url):
if isinstance(url,str):
url = url.encode("utf-8")
m = hashlib.md5()
m.update(url)
return m.hexdigest()
def add_jobbole(value):
return value + ".jobbole"
def date_convert(value):
try:
re_create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date()
except Exception as e:
re_create_date = datetime.datetime.now().date()
return re_create_date
def get_number(value):
# 利用正则表达式,过滤掉不要的字符
re_math = re.match(".*?(d+).*", value)
if re_math:
number = re_math.group(1)
else:
number = 0
return number
def remove_tags(value):
#去掉tag中的评论
if "评论" in value:
return ""
else:
return value
def return_value(value):
return value
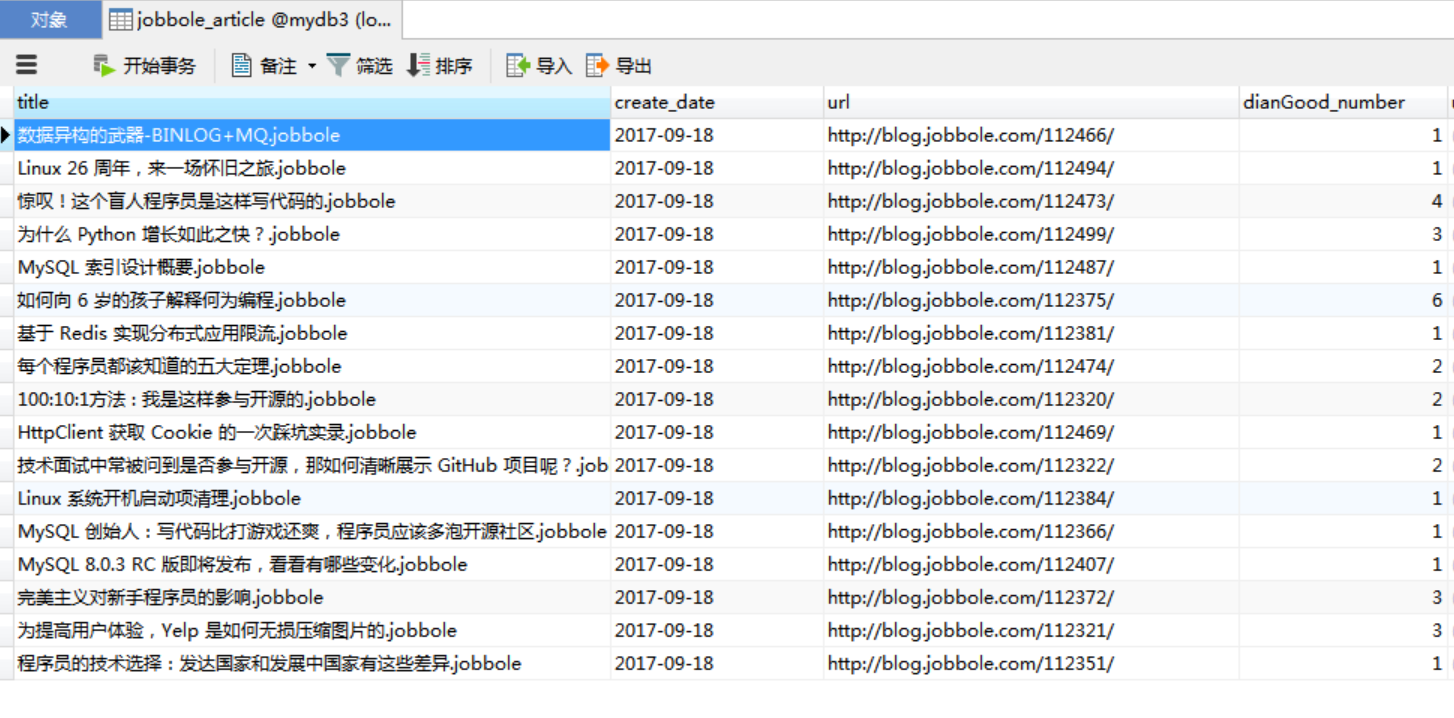
运行结果

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~





