下载:
https://pan.baidu.com/s/1nvGaFdn SPSS® Modeler 下载
IBM® SPSS® Modeler 是一组数据挖掘工具,通过这些工具可以采用商业技术快速建立预测性模型,并将其应用于商业活动,从而改进决策过程。
借助 SPSS Modeler,您可以快速直观地构建准确的预测模型而无需进行编程。
Demos 文件夹
应用程序申请使用的数据文件和样本流安装在产品安装目录的 Demos 文件夹下(例如:C:Program FilesIBMSPSSModeler<version>Demos)。可以在 Windows 的“开始”菜单中的 IBM SPSS® Modeler 程序组访问此文件夹,也可以通过单击文件 > 打开流对话框中最近访问的目录列表中的 Demos 来进行访问。
作为一种数据挖掘应用程序,IBM® SPSS® Modeler 提供了用以寻找大数据集中有用关系的策略性方法。与更传统的统计方法相比,您在开始时不必知道您要寻找什么。您可以通过拟合不同的模型和研究不同的关系来探索您的数据,直到发现有用的信息。
启动 IBM® SPSS® Modeler
开始 > 所有程序 > IBM SPSS Modeler 18.0 > IBM SPSS Modeler 18.0
使用 IBM SPSS Modeler 即处理数据的三个步骤。
首先,将数据读入 IBM SPSS Modeler。
接着,通过一系列处理来运行数据。
最后,将数据发送至目标。
这一操作序列称为 数据流 ,因为数据以一条条记录的形式,从数据源开始,依次经过各种操纵,最终到达目标(模型或某种数据输出)。
图 2. 简单流
例如,可以使用记录选项选用板选项卡中包含的节点对数据记录执行操作,如选择、合并和追加等。
要将节点添加到画布中,请双击“节点”选用板中的图标并将节点拖放到画布上。随后可将各个图标连接以创建一个表示数据流动的 流 。
每个选用板选项卡均包含一组不同的流操作阶段中使用的相关节点,如:
- 源 此类节点将数据引入 SPSS Modeler 中。
- 记录选项 此类节点可对数据记录执行选择、合并和追加等操作。
- 字段选项 此类节点可对数据字段执行操作,如过滤、导出新字段和确定给定字段的测量级别等。
- 图形 此类节点可在建模前后以图表形式显示数据。图形包括散点图、直方图、网络节点和评估图表。
- 建模 此类节点可使用 SPSS Modeler 中提供的建模算法,例如神经网络、决策树、聚类算法和数据序列等。
- 数据库建模 此类节点使用 Microsoft SQL Server、IBM DB2 和 Oracle 以及 Netezza 数据库中提供的建模算法。
- 输出 此类节点生成可在 SPSS Modeler 中查看的数据、图表和模型等多种输出结果。
- 导出 此类节点生成可在外部应用程序(如 IBM® SPSS Data Collection 或 Excel)中查看的多种输出。
- IBM SPSS Statistics 此类节点从 IBM SPSS Statistics 中导入数据或将数据导出到其中,并用于运行 IBM SPSS Statistics 过程。
随着对 SPSS Modeler 的熟悉,您也可以自定义供自己使用的选用板内容。
在“节点选用板”左侧,您可以通过选择 Analytic Server、“分类”、“关联”或“细分”来过滤节点。
“节点”选用板下方是一个报告窗格,此窗格提供各种操作的进度反馈,例如何时将数据读入数据流中。“节点”选用板下方还有一个状态窗格,此窗格提供有关应用程序当前正在执行的操作的信息以及何时需要用户反馈的指示信息。
IBM® SPSS® Modeler 中最常见的鼠标用法如下所示:
- 单击。使用鼠标右键或左键从菜单中选择选项、打开弹出菜单,以及访问其他标准控件和选项。单击并按住按键可移动和拖动节点。
- 双击。双击鼠标左键可将节点放入于流画布中以及编辑现有节点。
- 单击鼠标中键。单击鼠标中键并拖动光标可连接流画布中的节点。双击鼠标中键可断开某个节点的连接。如果没有三键鼠标,可在单击并拖动鼠标时通过按 Alt 键来模拟此功能。
构建流
要构建将创建模型的流,至少需要 3 个元素:
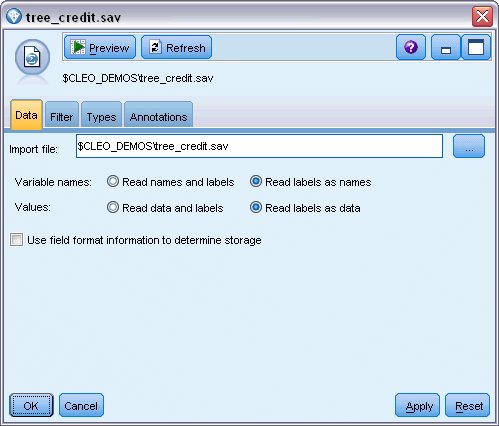
- 一个从某些外部源读取数据的源节点,在本示例中为 IBM® SPSS® Statistics 数据文件。
- 一个指定字段属性的源节点或“类型”节点,字段属性包括测量级别(字段包含的数据类型)以及每个字段在建模过程中的角色是目标还是输入等。
- 一个在运行流时生成模型块的建模节点。
Statistics 文件源节点从 tree_credit.sav 数据文件读取 IBM SPSS Statistics 格式数据,该文件安装在 Demos 文件夹中。(名为 $CLEO_DEMOS 的特殊变量用于引用位于当前 IBM SPSS Modeler 安装下的该文件。这样,无论当前的安装文件夹或版本是什么,均可以确保路径有效。)
图 2. 使用“Statistics 文件”源节点读取数据
类型节点指定每个字段的测量级别。测量级别是指示字段中数据的类型的类别。我们的源数据文件使用三种不同的测量级别。
连续字段(例如年龄字段)包含连续的数字值,而名义字段(例如信用评价字段)有两个或多个不同值,例如不良、优良或无信用历史记录。有序字段(例如收入水平字段)用于描述包含具有固有顺序的多个不同值的数据,在此个案中为低、中和高。
图 3. 使用“类型”节点设置目标和输入字段
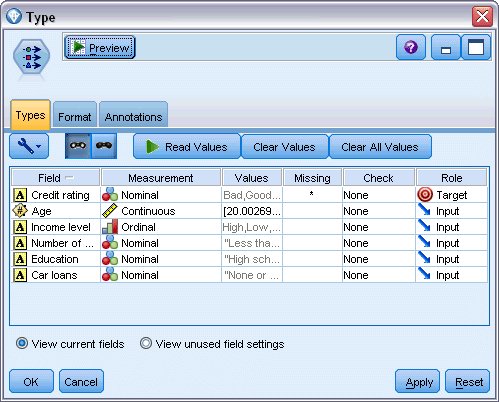
对于每个字段,类型节点还指定角色,以指示每个字段在建模中扮演的部分。将字段信用评价的角色设置为目标,此字段指示指定的客户是否拖欠贷款。这是目标,或者是要预测其值的字段。
对于其他字段,将角色设置为输入。输入字段有时也称为预测变量,或建模算法用其值来预测目标字段值的字段。
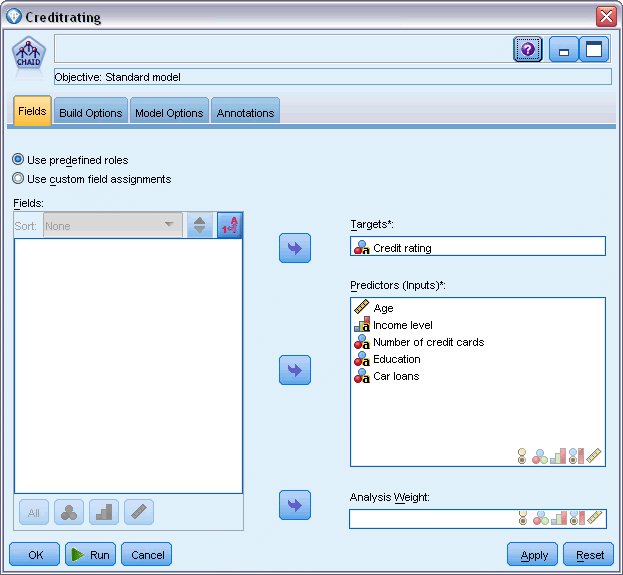
CHAID 建模节点将生成模型。
在建模节点的“字段”选项卡中,已选中使用预定义角色,这意味着将按在类型节点中的指定使用目标和输入。此时,可以更改字段角色,但就此示例而言,将按原样使用这些字段角色。
- 单击“构建选项”选项卡。
图 4. CHAID 建模节点,“字段”选项卡
下面是一些选项,可以在这些选项中指定要构建的模型种类。
由于我们想要一个全新的模型,因此使用缺省选项构建新模型。
我们还要求它为单个标准决策树模型,并且不包含任何增强,因此保留缺省目标选项构建单个树。
我们可以选择启动允许对模型进行微调的交互建模会话,本示例只使用缺省设置生成模型来生成模型。图 5. CHAID 建模节点,“构建选项”选项卡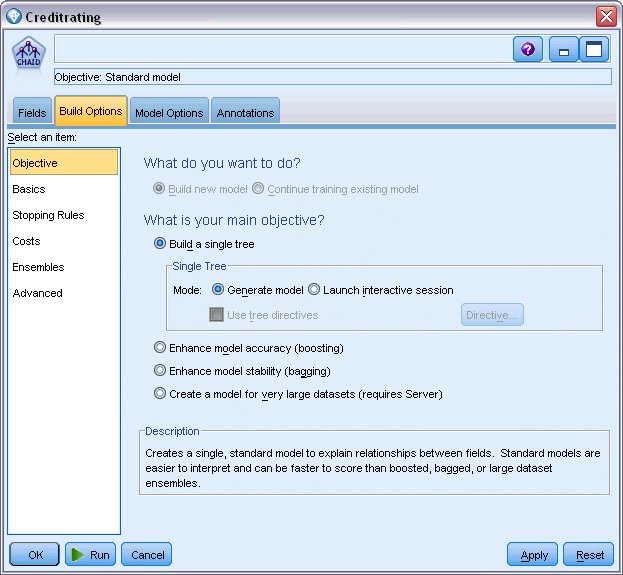
对于此示例,我们希望保持树相当简单,因此,将通过增加父节点和子节点个案的最小数来限制树增长。
- 在“构建选项”选项卡上,从左侧的导航器窗格选择停止规则。
- 选择使用绝对值选项。
- 将父分支中的最小记录数设置为 400。
- 将子分支中的最小记录数设置为 200。
图 6. 设置用于决策树构建的中止条件
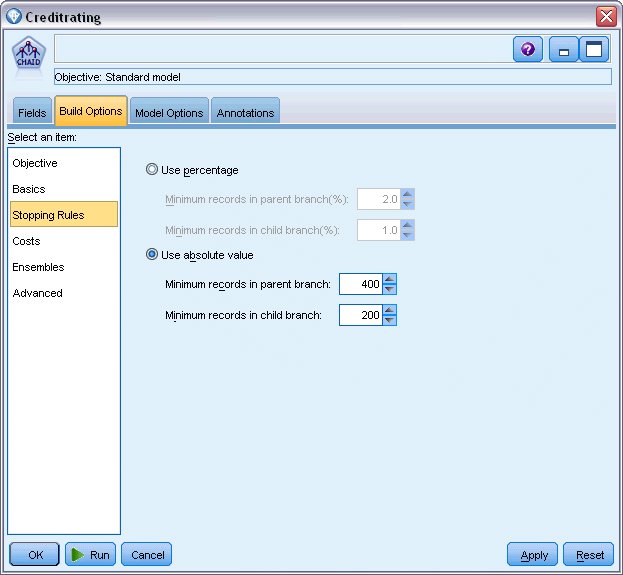
在本例中,我们可以使用所有其他缺省选项,因此单击运行以创建模型。(另外,也可以右键单击该节点,然后从上下文菜单中选择运行,或选择节点,并从“工具”菜单中选择运行。)
评估模型
我们已通过浏览模型了解了评分方式。但是,如果要评估模型的准确度,那么需要对一些记录进行评分,并将模型预测的响应与实际结果进行比较。我们将对用于估算模型的同一记录进行评分,从而对观察到的响应与预测响应进行比较。
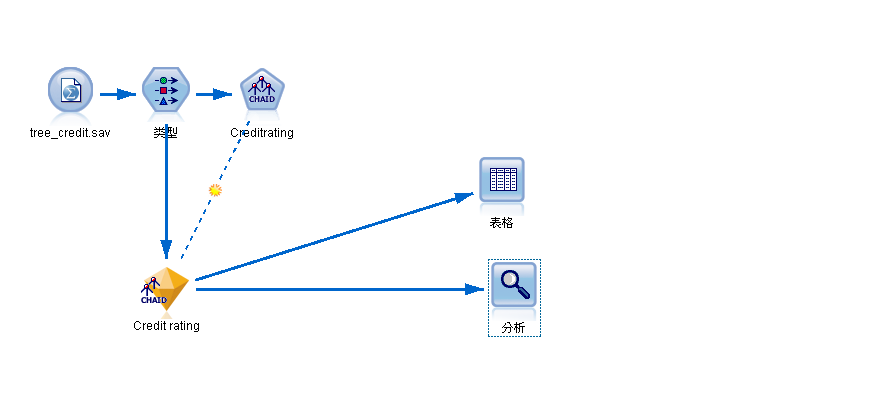
图 1. 将模型块附加到输出节点以进行模型评估
- 要查看分数或预测值,请将表节点添加到模型块,然后双击“表”节点,并单击运行。
表在名为 $R-Credit rating 的字段中显示预测分数,该字段由模型创建。我们可以将这些值与包含实际响应的原始信用评价字段进行比较。
按照惯例,在评分过程中生成的字段的名称基于目标字段,但是要加上标准前缀。前缀 $G 和 $GE 由广义线性模型生成,$R 是用于本例中的 CHAID 模型所生成的预测的前缀,$RC 用于置信度值,$X 通常是使用整体生成的,而 $XR、$XS 和 $XF 在目标字段分别为“连续”、“分类”、“集合”或“标志”字段的情况下用作前缀。不同的模型类型使用不同的前缀集。置信度值是模型自身对每个预测值的准确度的估计,范围为 0.0 到 1.0。图 2. 显示已生成的评分和置信度值的表
与预期的一样,预测值与大多数(并非全部)记录的实际响应相匹配。出现此情况的原因是每个 CHAID 终端节点都具有混合响应。预期值与 最常见 的响应相匹配,但对于该节点中的其他响应,该预期值是错误的。(记住,16% 的少部分低收入客户没有拖欠。)
为了避免出现这种情况,可以继续将树拆分为越来越小的分支,直到每个节点都只包含优良或不良响应为止。但是,这样的模型可能会非常复杂,并且不易推广到其他数据集。
要查看具体有多少预测值正确,我们可通读表格,并计算预测字段 $R-Credit rating 的值匹配信用评价的值的记录数量。幸运的是,有更简单的方法 - 我们可以使用自动执行此操作的“分析”节点。 - 将模型块连接到“分析”节点。
- 双击“分析”节点,然后单击运行。
图 3. 附加“分析”节点
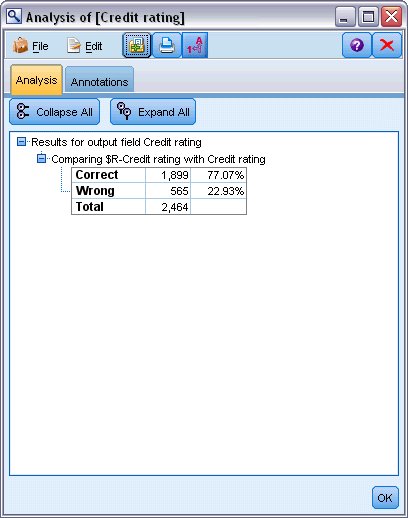
分析表明,对于 2464 条记录中的 1899 条记录(超过 77%),模型预测的值与实际响应相匹配。
图 4. 观察到的响应与预测响应的比较分析结果
此结果受到评分的记录和用于评估模型的记录相同的事实的限制。在真实情况中,可使用分区节点将数据拆分为培训和评估的单独示例。
通过使用一个样本分区生成模型并使用另一个样本对模型进行检验,您会得到该模型推广到其他数据集的情况
通过“分析”节点,我们可以根据已知道实际结果的记录来检验模型。下一阶段介绍如何使用模型对我们不知道结果的记录进行评分。例如,这可能包括当前不是银行客户的人员,但他们是促销邮寄的潜在目标。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






