前言
此篇图文,只做数据挖掘、统计和分析的技术分享,不涉及用户隐私信息的挖掘,请知悉!
如有侵犯,请邮件网站管理员1071235258@qq.com,进行删除~。
顺便说下,我们的python 学习交流群:367203382 ,加他,加他,加他~~

然后通过取经和发现,腾讯居然提供网页版本查看qq成员列表信息的链接~,这不是方便爬虫嘛~,嘿嘿。能白嫖就得白嫖~
如果它不提供,我们就得用笨办法,UI自动化方式,一个一个右键--查看属性--》获取qq 号,性别,地区等信息。
它是有个规律的URL: https://qun.qq.com/member.html#gid=779133600,gid = 此处是群号

看看到底多少人,是1811人:

来跟着小编,动起我们的小手,敲个数据挖掘的程序,这里为啥不说爬虫呢,因为数据挖掘更好听一些。
咱们先分析一下,这个网页的数据,随着下拉条的拉动进行ajax异步 加载的,所以我们要操作浏览器的滚动条进行下滑操作。
操作浏览器的神器,就是我么之前Python 自动化办公课程所讲到的Selenium技术。
下方给出课程链接:https://edu.51cto.com/sd/b12dd
通过Selenium 来操作浏览器的下拉滚动条。
但是后来想了想,我的鼠标是罗技G503 Hero ,当初买它就看中它的无限滑轮,稍微一把拉,滚动好长时间,‘
这样就可以省了,selenium 操作浏览器向下滑动的代码,要不然滑动条需要根据 总人数 / 屏幕显示+++次数,要滑动很多次。
下面代码实现
setp1:
我们要先打开一个谷歌浏览器,然后手动打开这个页面,为什么呢,需要这个页面需要我们登陆一个QQ账号。
为了节省获取cookie 的代码,我们可以手动+自动配合嘛。先手动打开这个页面,登陆下你的QQ,
然后这2千多人的qq 个人资料,就不都是你的了吗。
selenium 直接操作一个打开的谷歌浏览器代码,我们还是贴出来让小伙伴瞅瞅。
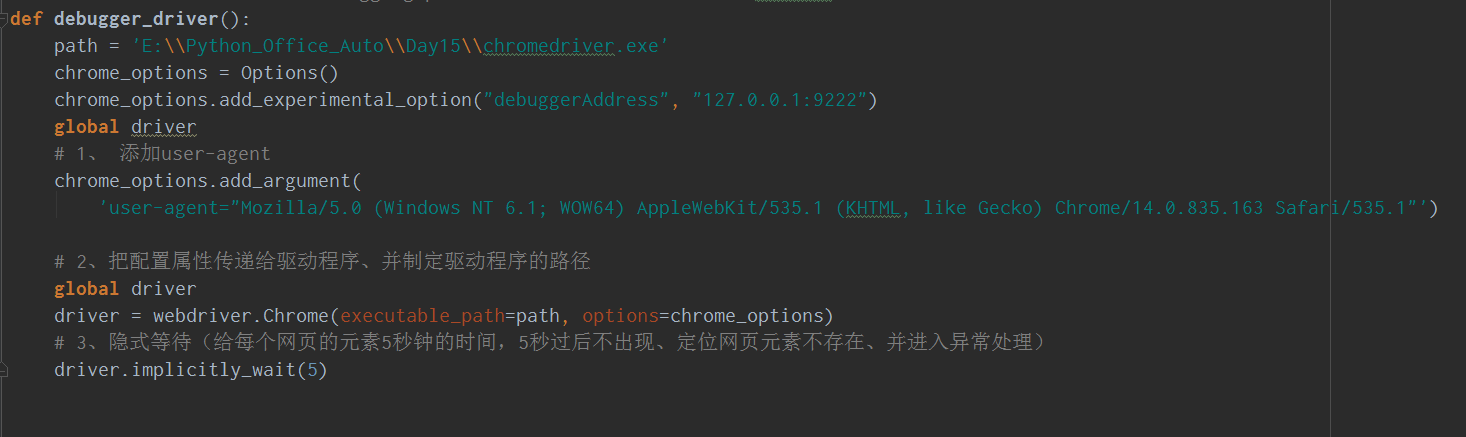
Step2:
我们要获取这些放在表格的资料,我们去分析html 网页中的tr 标签,就对应着每个成员的信息。
但是我看到这个网页标签的命名,就应该体会到,当时做前端的小姐姐,心理的状态了:
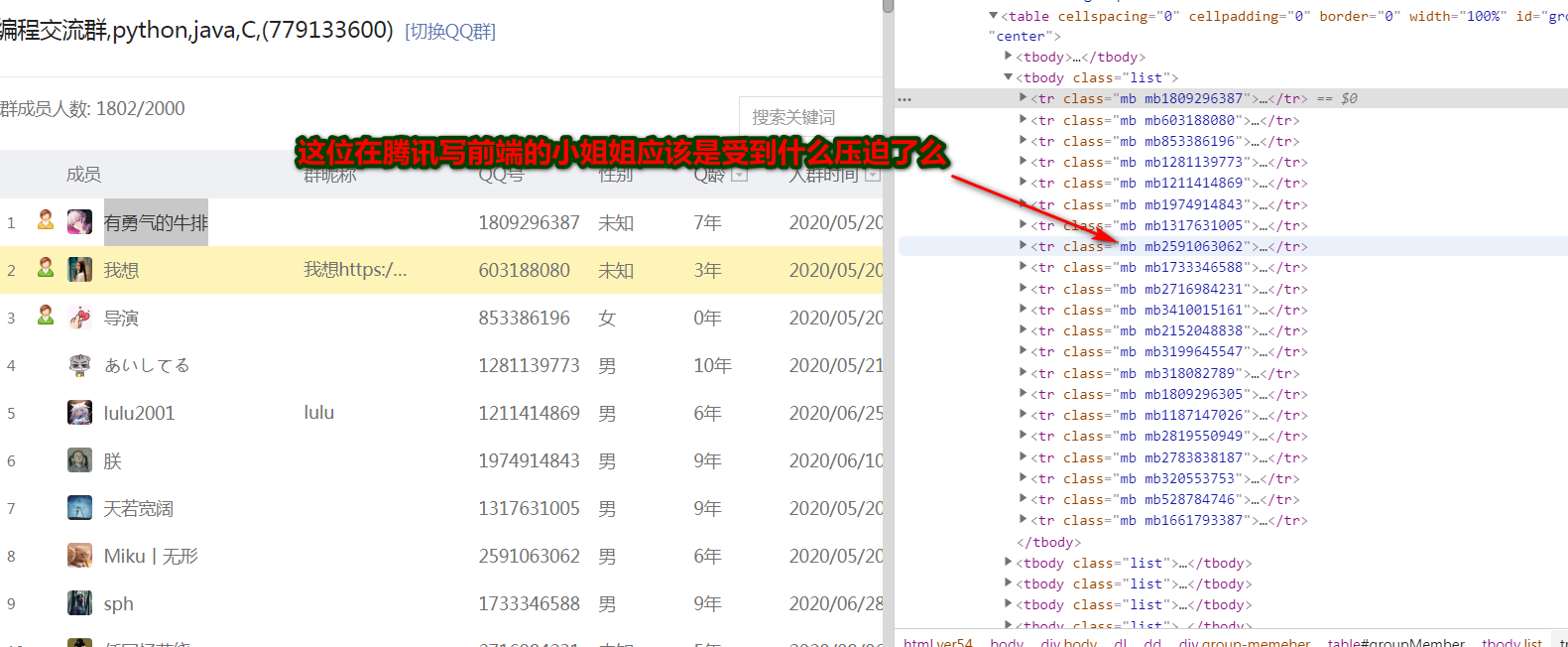
Step3:
通过selenium 获取的html网页源码,传给bs4 进行解析,一个很神奇的库。
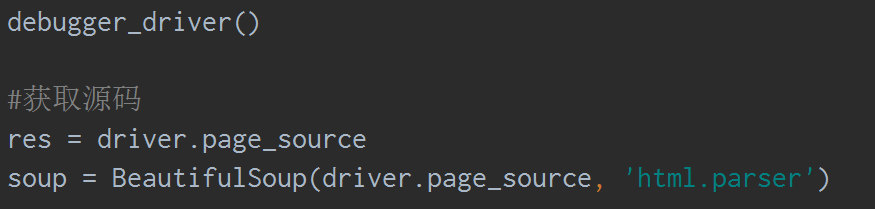
然后for 循环上给他安排上,所有数据给他拿下:
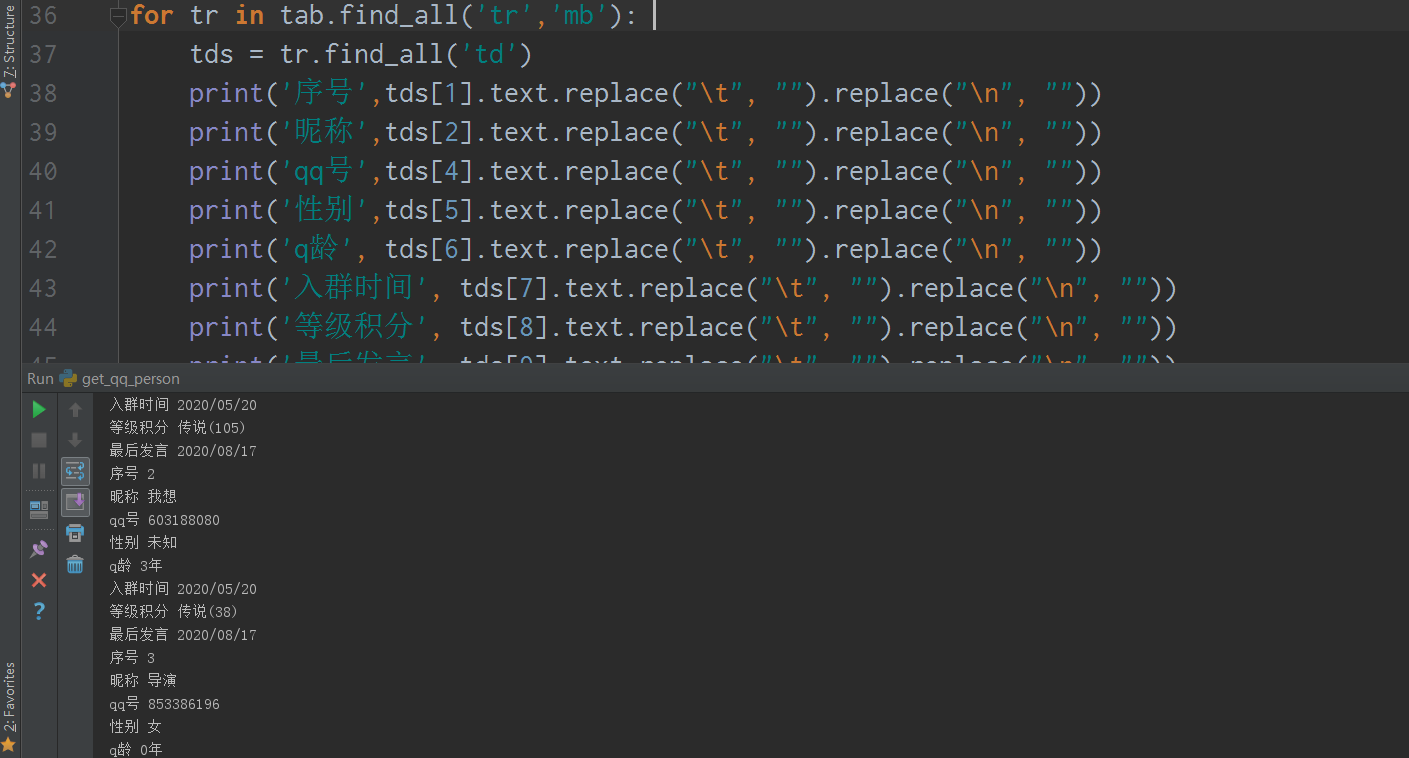
拿下之后,你愿意怎么分析,怎么分析,我就不管了~~~~,你是写文件,写excel ,还是写数据库!

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






